大数据分析与应用实验任务十
实验目的:
实验任务:
进入pyspark实验环境,在桌面环境打开jupyter notebook,或者打开命令行窗口,输入pyspark,完成下列任务:
实验一、参考教材5.3-5.6节各个例程编写代码,逐行理解并运行。
1. DataFrame 的创建
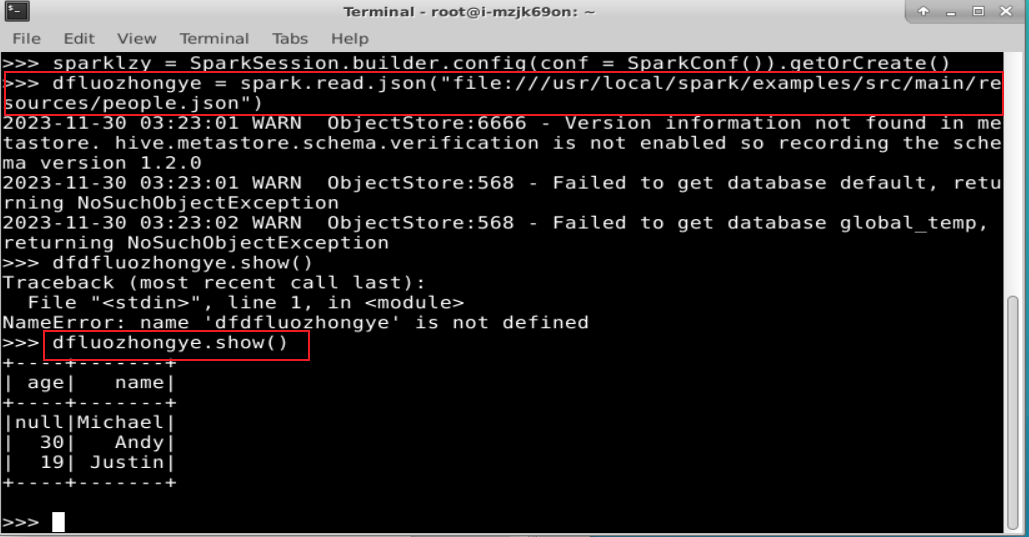
在编写独立应用程序时,可以通过如下语句创建一个 SparkSession 对象:
读取在“/usr/local/spark/examples/src/main/resources/”目录下的样例数据 people.json
2. DataFrame 的保存
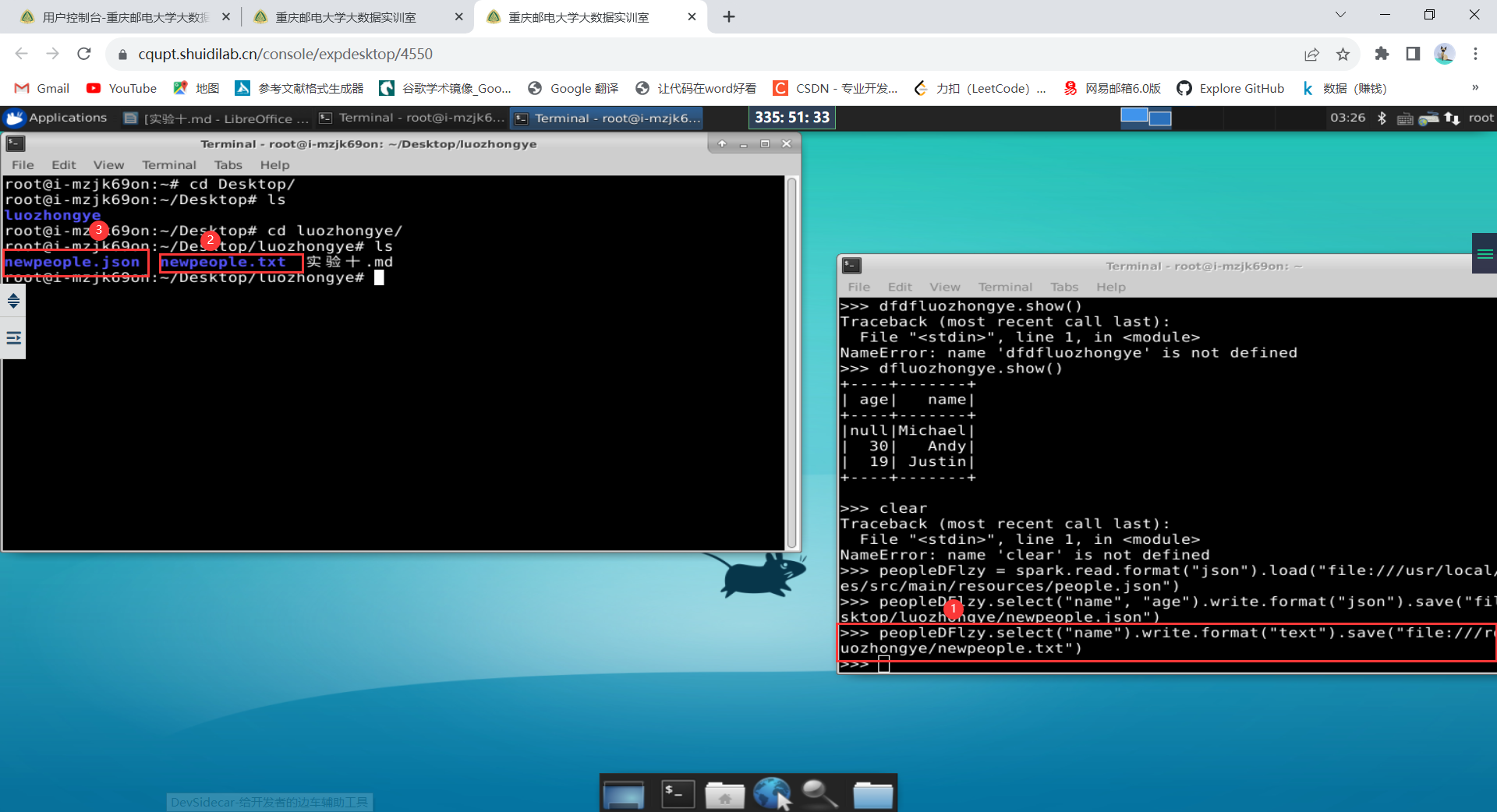
如果要再次读取 newpeople.json 中的数据生成 DataFrame,可以直接使用 newpeople.json 目录名称,而不需要使用 part-00000-3db90180-ec7c-4291-ad05-df8e45c77f4d.json 文件(当然,使用这个文件也可以),代码如下:
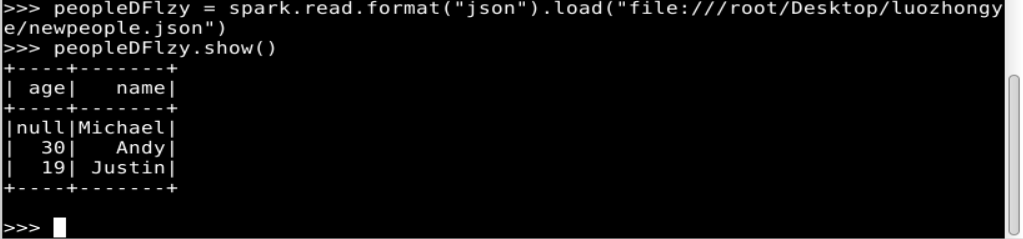
3. DataFrame 的常用操作
(1) printSchema()

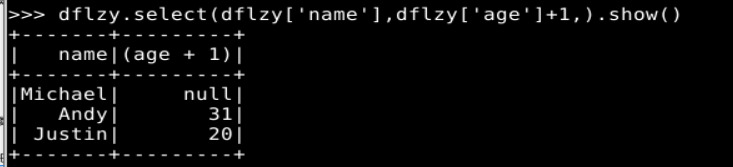
(2) select()
(3) filter()

(4) groupBy()
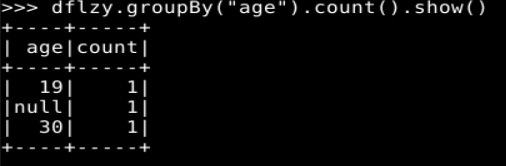
(5) sort()
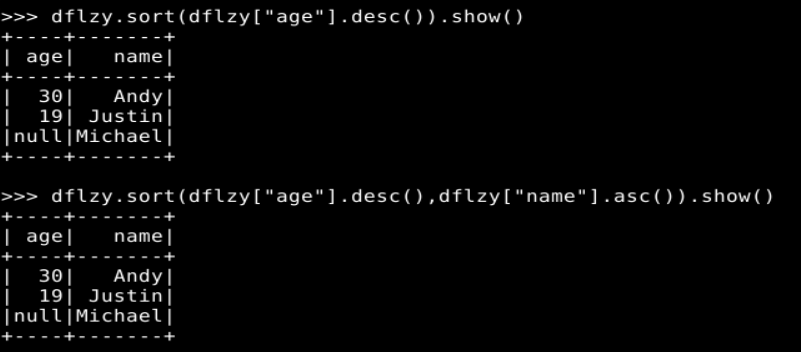
4. 从 RDD 转换得到 DataFrame
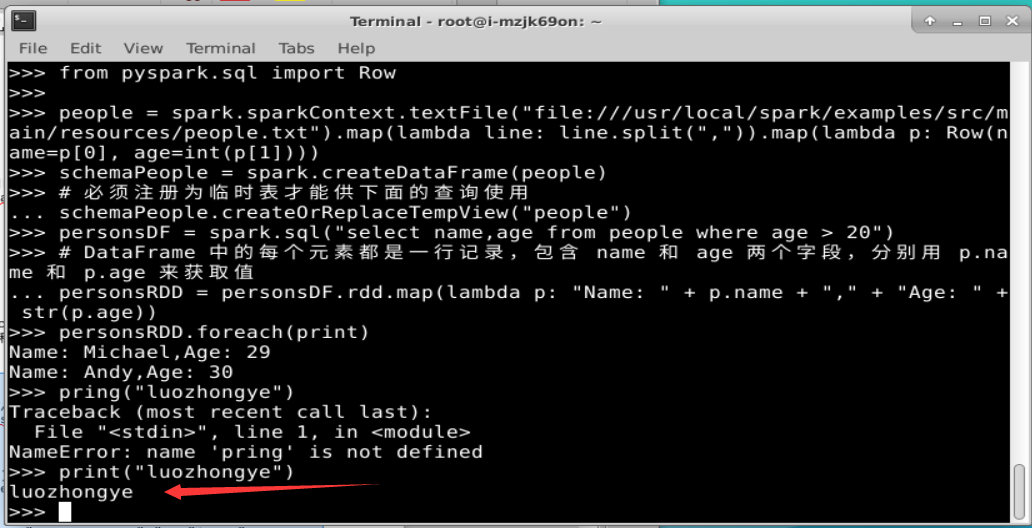
(1) 利用反射机制推断 RDD 模式
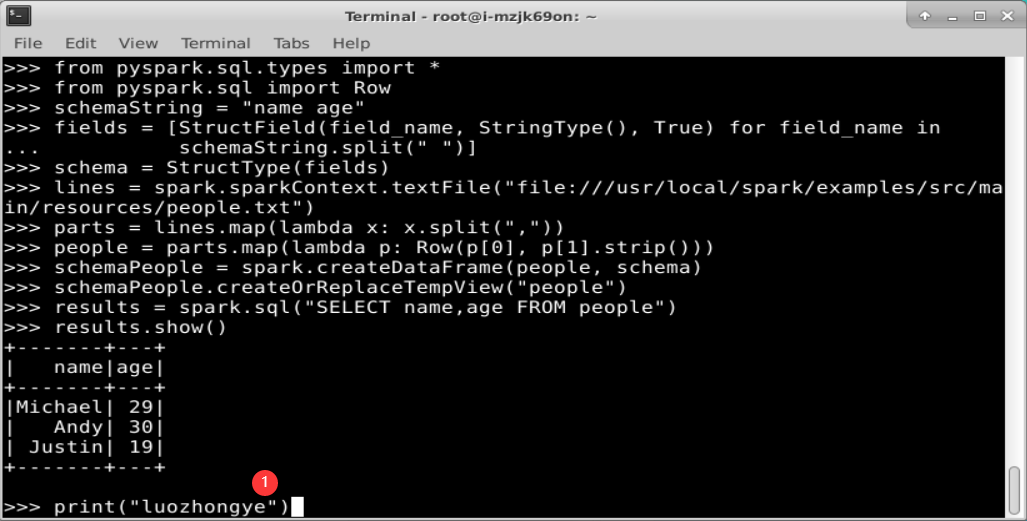
(2)使用编程方式定义 RDD 模式
实验二、完成p113页实验内容第1题(spark SQL基本操作),另注意自行修改题目中的数据。
1. Spark SQL 基本操作
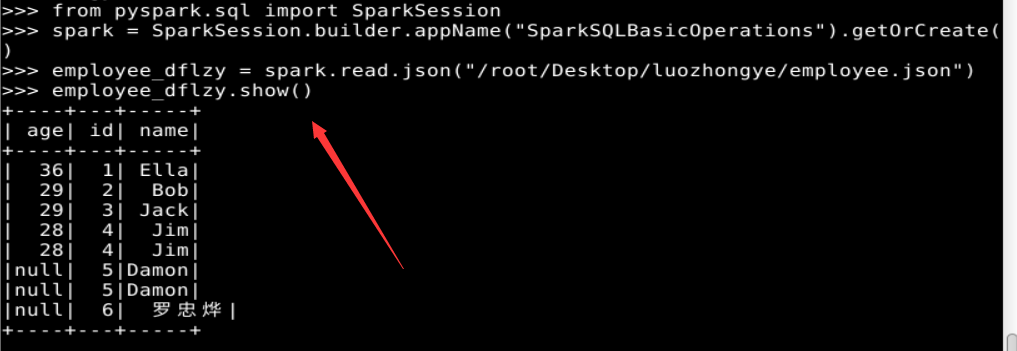
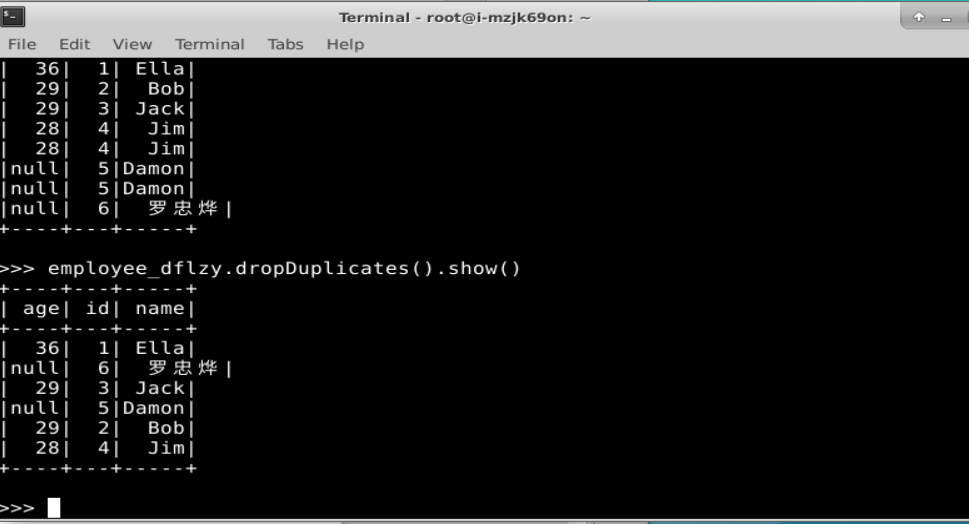
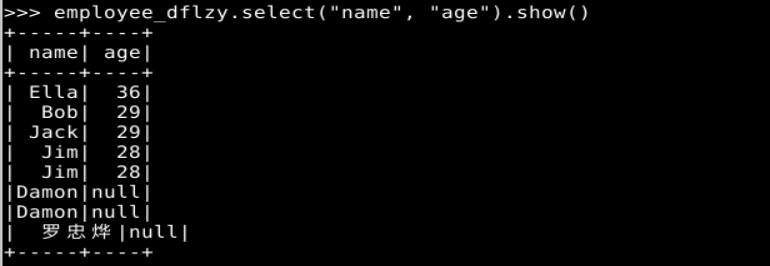

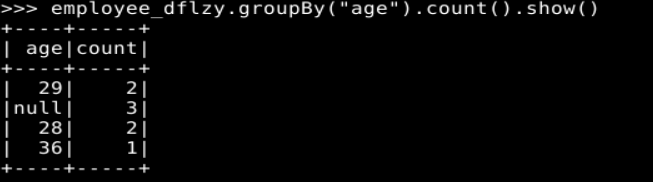
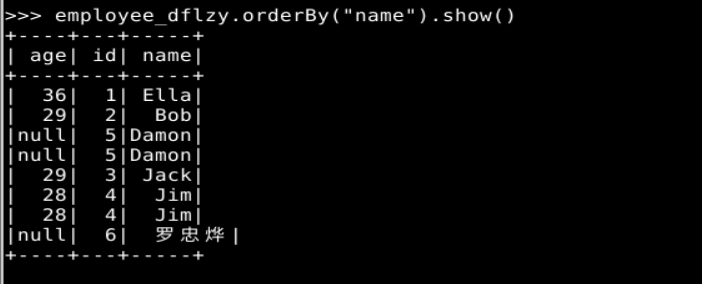
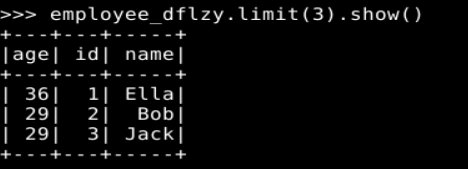
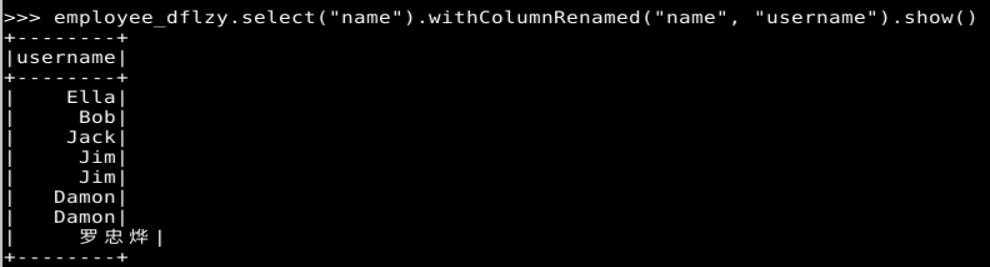
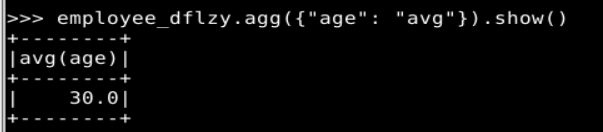

2. 编程实现将 RDD 转换为 DataFrame
3. 编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee, 包含下表 所示的两行数据。
(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入表 5-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







