本文介绍: 得益于一种名为潜在一致性模型(LCM)的新技术,文本转换成图像的AI即将迎来重大飞跃。潜在扩散模型(LDM)等传统方法在使用文本提示生成详细、创造性的图像方面令人印象深刻,然而它们的致命弱点是速度慢。使用LDM生成单单一个图像可能需要数百个步骤,这对于许多实际应用来说实在太慢了。

1、高效训练LCM
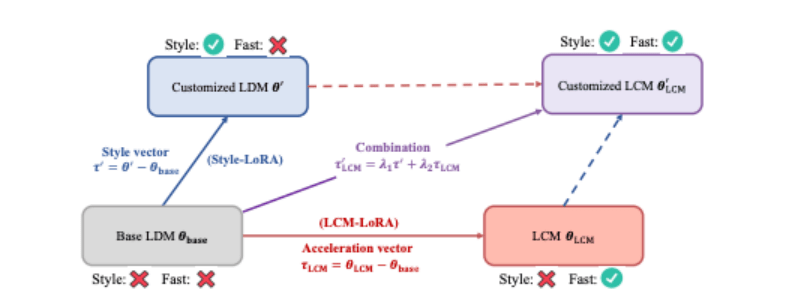 图1、LCM-L
图1、LCM-L2、结果

3、局限性
4、主要的启示
5、LCM-LoRA作为通用加速模块
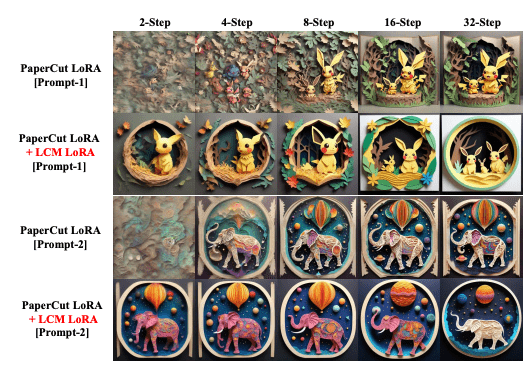 图3
图36、结论
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。