在pandas中进行数据分析,面对复杂的数据处理需求时经常会创建自定义函数来进行数据处理。那么,自定义函数在pandas中如何使用呢?
一、创建自定义函数
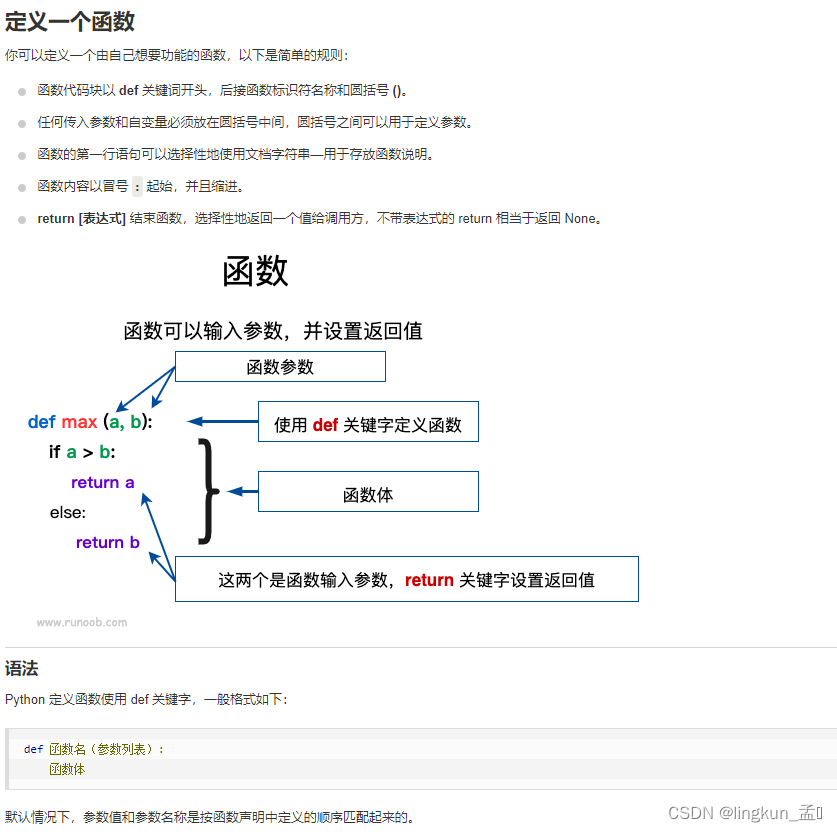
示例:计算BMI指数
二、使用自定义函数
pandas 的 apply() 函数可以作用于 Series 或者整个 DataFrame,功能也是自动遍历整个 Series 或者 DataFrame, 对每一个元素运行指定的函数。DataFrame中 apply的工作方式为,先通过axis参数,按行/列将DataFrame切片成一行/列的Series,放入元组。然后使用底层的C语言实现高效的元组遍历。
官方上给出的 apply() 用法:
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds)
func 代表的是传入的函数或 lambda 表达式;
axis 参数可提供的有两个,该参数默认为0/列
0 或者 index ,表示函数处理的是每一列;
1 或 columns ,表示处理的是每一行;
raw ;bool 类型,默认为 False;
False ,表示把每一行或列作为 Series 传入函数中;
True,表示接受的是 ndarray 数据类型;
apply() 最后的是经过函数处理,数据以 Series 或 DataFrame 格式返回。
axis参数
axis参数指的是“切片的方向”而不是“应用的方向”。因此axis=0表示沿着0轴方向切片即按列切片,axis=1表示沿着1轴方向切片即按行切片

apply参数传递
DataFrame中 apply的工作方式为,先通过axis参数,按行/列将DataFrame切片成一行/列的Series,放入元组。然后将元组中的元素(各行/列切片形成的Series)传入要应用的函数func。当要应用的函数func只有一个函数时写成apply(func)和apply(lambda x:func(x))效果是一致的。但是当func有多个参数时,只能写成apply(lambda x:func(x,y,z))。同时使用lambda函数也增加了func参数的灵活性,使的func的参数不局限与一整行/列形成的Series。但是lambda 改变了apply函数的作用域,需要注意。




