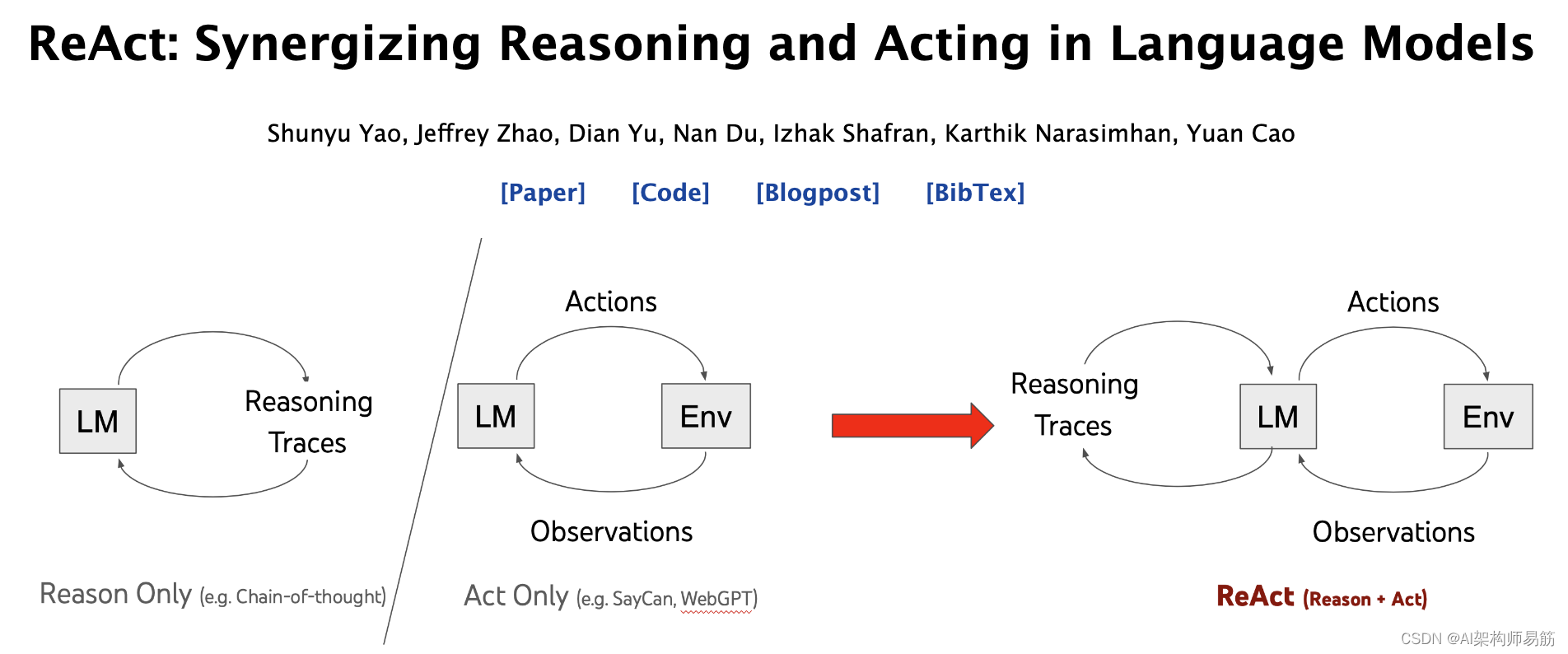
ReAct (Reason Action):在语言模型中协同推理和行动
语言模型在推理(例如思维链提示)和行动(例如WebGPT,SayCan,ACT-1)方面变得更加出色,但这两个方向始终保持分离。
ReAct问,如果这两种基本能力结合在一起会怎样?
1. 摘要
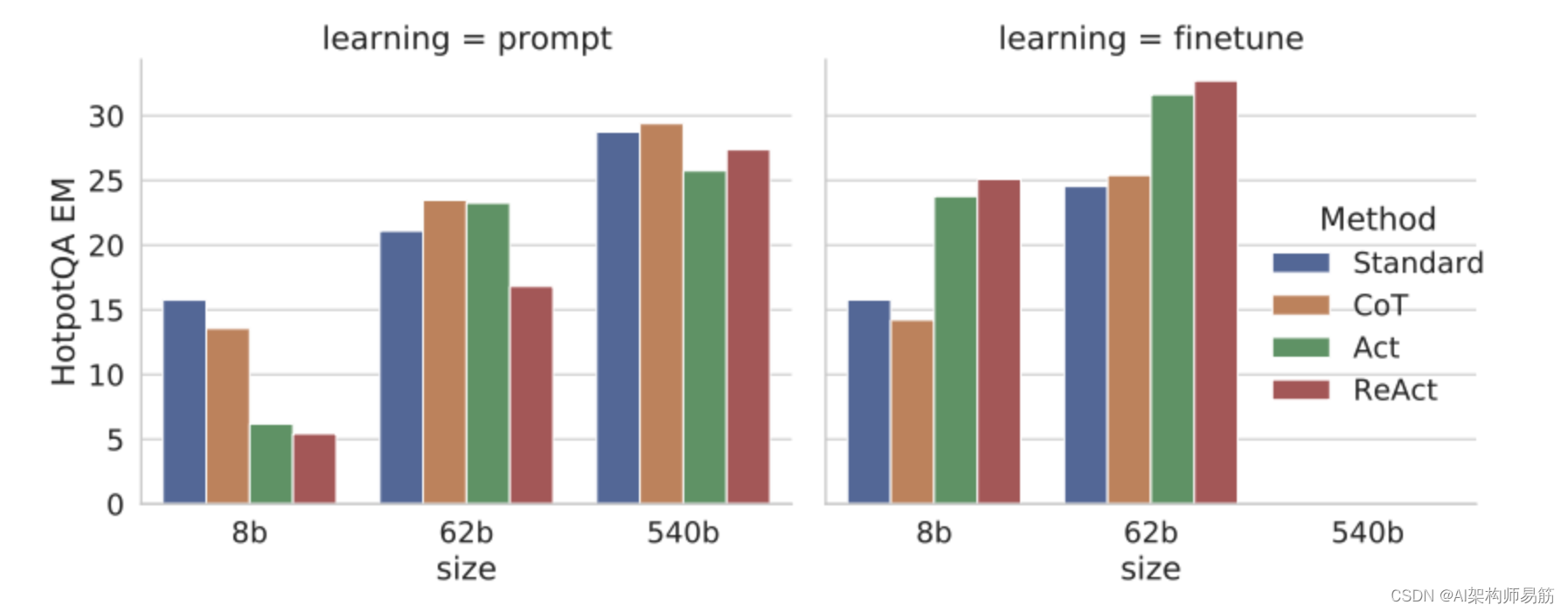
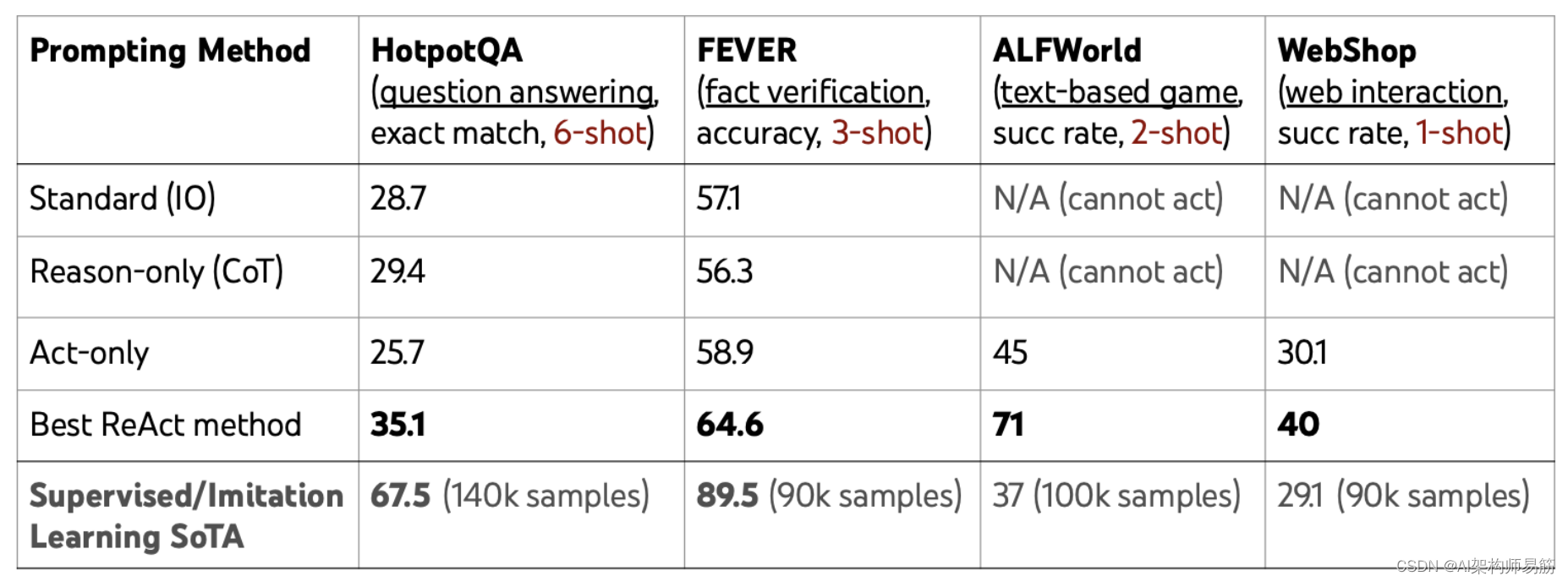
尽管大型语言模型(LLMs)在语言理解和交互式决策任务中展示了令人印象深刻的能力,但它们在推理(例如思维链提示)和行动(例如行动计划生成)方面的能力主要被研究为分开的主题。在本文中,我们探讨了LLMs的使用,以交错方式生成推理追踪和特定任务的行动,从而在两者之间实现更大的协同作用:推理追踪有助于模型诱导、跟踪和更新行动计划以及处理异常,而行动使其能够与外部来源(例如知识库或环境)进行交互,以收集额外信息。我们将我们的方法ReAct应用于各种语言和决策任务,并展示其相对于最先进的基线的有效性,以及相对于没有推理或行动组件的方法的改进的人类可解释性和可信度。具体而言,在问题回答(HotpotQA)和事实验证(Fever)方面,ReAct通过与简单的维基百科API交互,克服了思维链推理中流行的妄想和错误传播问题,并生成了更可解释的人类式任务解决轨迹,这些轨迹比没有推理追踪的基线更可解释。在两个交互式决策制定基准(ALFWorld和WebShop)上,ReAct分别以34%和10%的绝对成功率击败了模仿和强化学习方法,而只需一两个上下文示例即可进行提示。
2. ReAct提示
ReAct提示由少量任务解决轨迹组成,其中包括人工撰写的文本推理追踪和行动,以及对行动的环境观察(请参阅论文附录中的示例!)
ReAct提示设计直观灵活,并在各种任务中实现了最先进的少样本性能,从问题回答到在线购物!
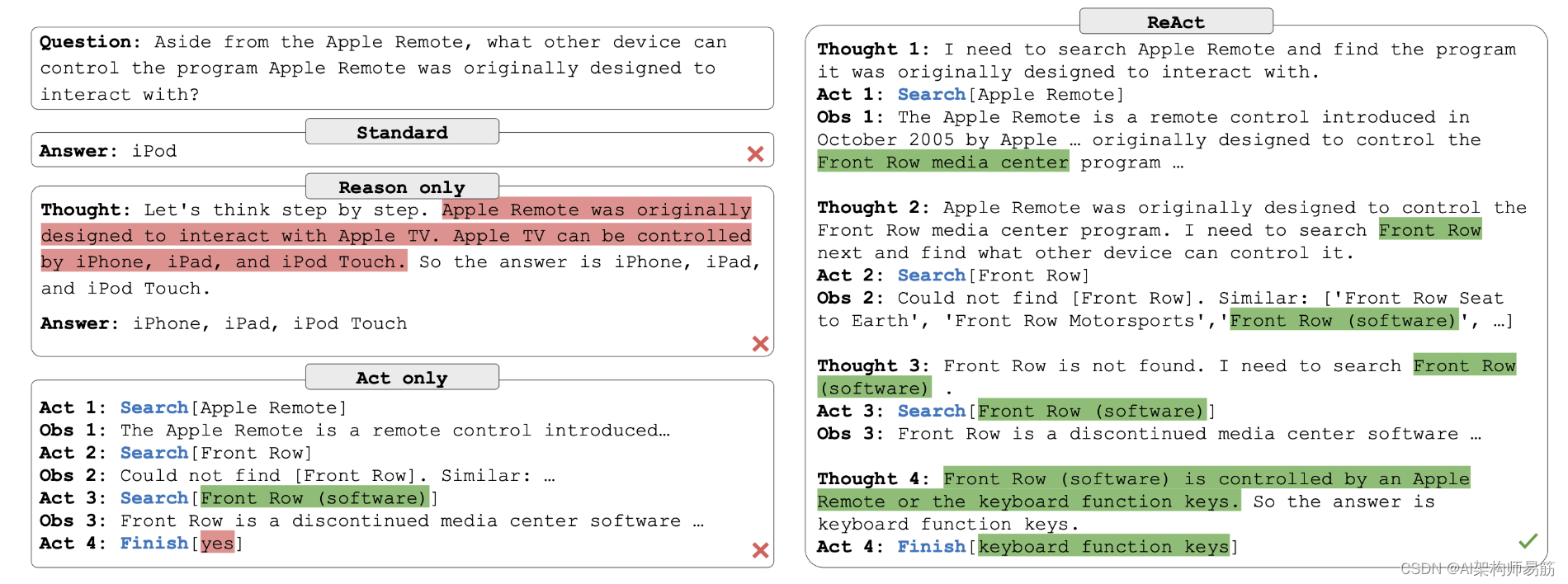
3. HotpotQA示例
仅限原因的基线(即思维链)由于未与外部环境接轨以获取和更新知识,因此存在错误信息(红色),并且必须依赖有限的内部知识。
仅限行动的基线由于缺乏推理,无法综合最终答案,尽管在这种情况下具有与ReAct相同的行动和观察。
相比之下,ReAct通过可解释和事实的轨迹解决了任务。
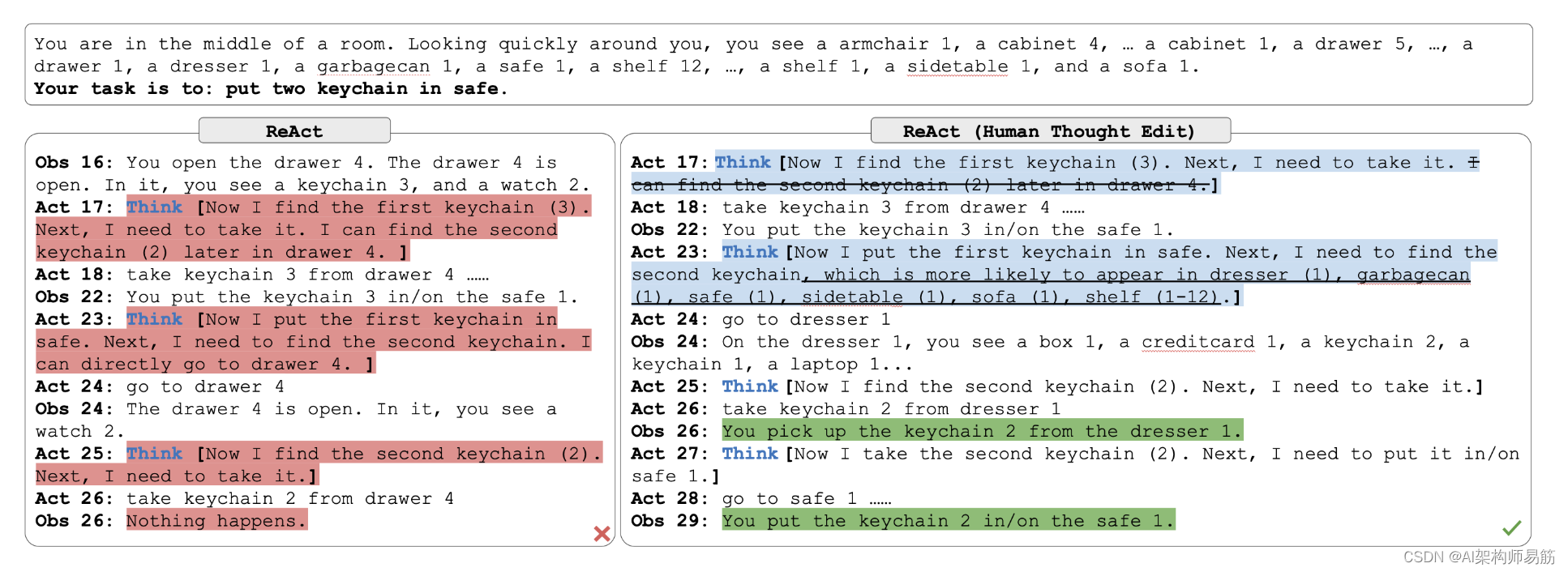
4. ALFWorld示例
对于决策任务,我们设计了具有稀疏推理追踪的人类轨迹,让LM决定何时思考与行动。
ReAct并不完美—以下是ALFWorld的一个失败示例。但是,ReAct格式可以通过改变几个模型想法轻松进行人工检查和行为校正,这是一种令人兴奋的新的人类对齐方法!