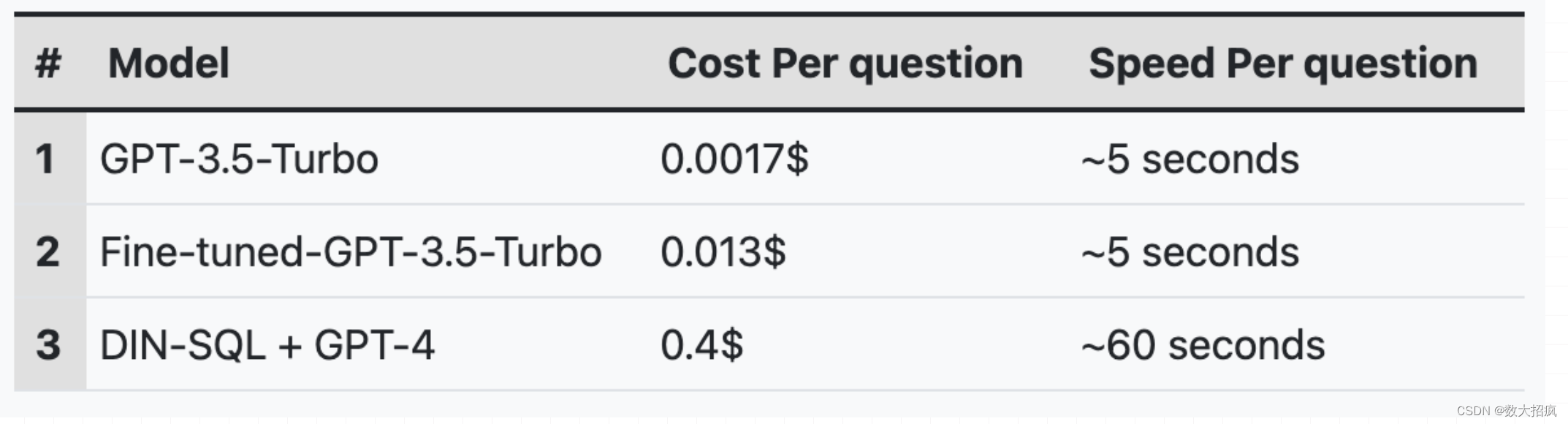
本文介绍: 因此,在使用Spider数据集时,我们将样本数量从7000个减少到5750个,并进行总共2个时期的微调。我们将微调模型的性能与未经微调的GPT3.5-Turbo和DIN-SQL + GPT-4(Spider的当前最先进方法)进行了基准测试,以获得零-shot性能。微调的G-3.5-Turbo的性能与之前的方法相比进的提示技术,包括少量提示、思维链提示和分解提示)保持一致,这是当前最先进的方法。如上所示,与DIN-SQL与GPT-4相比,微调的GPT-3.5-Turbo模型的成本。
提交训练集进行微调
一旦我们创建了JSONL文件(可以在这里或ipfs_here找到一个小样本),下一步是使用以下命令将创建的文件上传到OpenAI:
上传文件后,可以使用以下命令检查上传的状态:
结果应该类似于:
当状态变为已处理时(类似于下面的示例),您可以将文件用于微调:
现在,我们准备开始微调作业。可以使用以下python代码创建一个微调作业:
微调过程的持续时间将根据微调数据集的大小而有所不同。微调有一个最大令牌限制,设置为50000000个令牌。因此,在使用Spider数据集时,我们将样本数量从7000个减少到5750个,并进行总共2个时期的微调。
模型性能

结论
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。