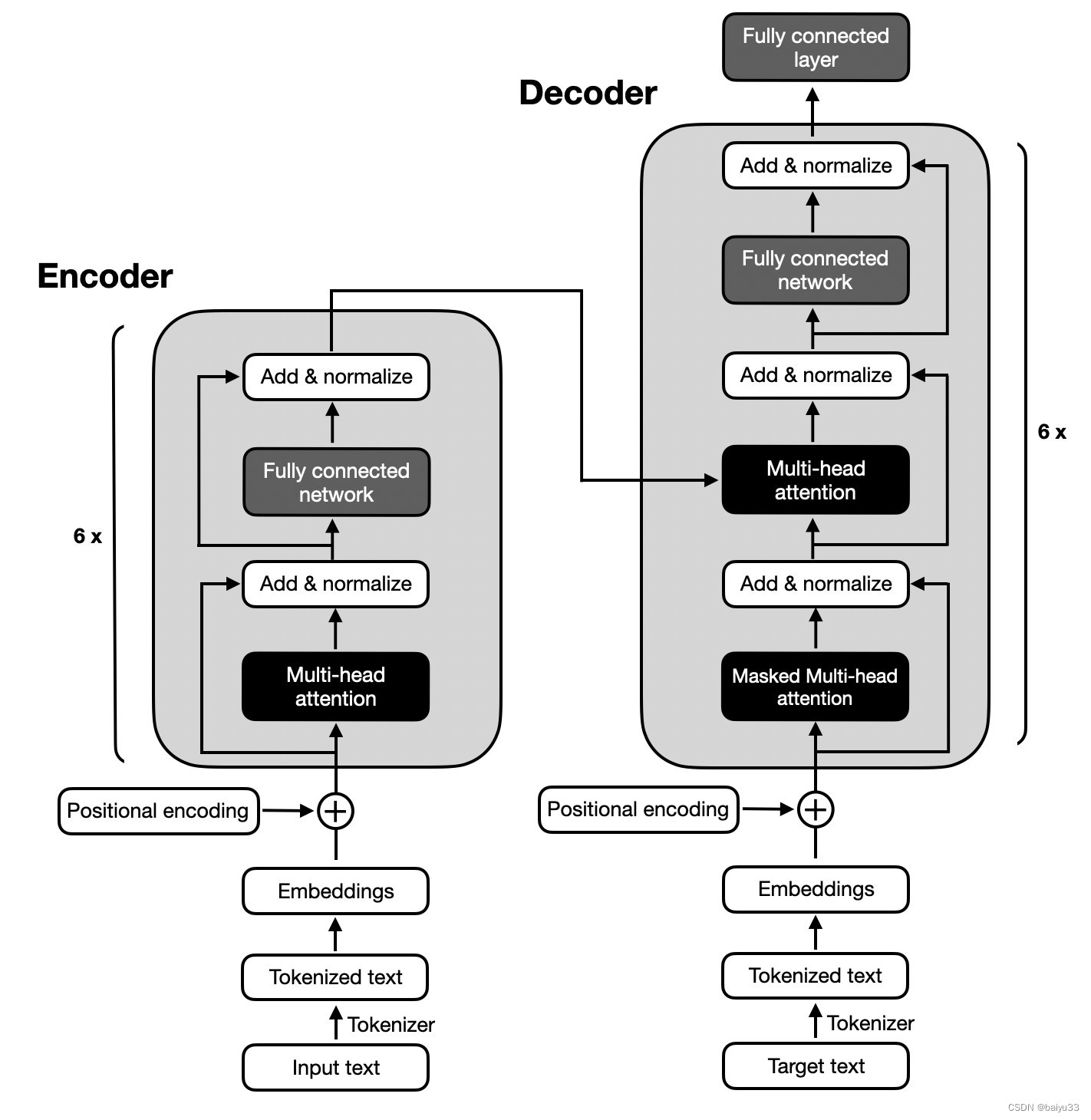
简介
Encoder和Decoder共同组成transfomer,分别对应图中左右浅绿色框内的部分.

Encoder:
目的:将输入的特征图转换为一系列自注意力的输出。
工作原理:首先,通过卷积神经网络(CNN)提取输入图像的特征。然后,这些特征通过一系列自注意力的变换层进行处理,每个变换层都会将特征映射进行编码并产生一个新的特征映射。这个过程旨在捕捉图像中的空间和通道依赖关系。
作用:通过处理输入特征,提取图像特征并进行自注意力操作,为后续的目标检测任务提供必要的特征信息。
Decoder:
目的:接受Encoder的输出,并生成对目标类别和边界框的预测。
工作原理:首先,它接收Encoder的输出,然后使用一系列解码器层对目标对象之间的关系和全局图像上下文进行推理。这些解码器层将最终的目标类别和边界框的预测作为输出。
作用:基于Encoder的输出和全局上下文信息,生成目标类别和边界框的预测结果。
总结:Encoder就是特征提取类似卷积;Decoder用于生成box,类似head
源码实现:
Encoder 通常是6个encoder_layer组成,Decoder 通常是6个decoder_layer组成
我实现了核心的BaseTransformerLayer层,可以用来定义encoder_layer和decoder_layer
具体源码及其注释如下,配好环境可直接运行(运行依赖于上一个博客的代码):
import torch
from torch import nn
from ZMultiheadAttention import MultiheadAttention # 来自上一次写的attension
class FFN(nn.Module):
def __init__(self,
embed_dim=256,
feedforward_channels=1024,
act_cfg='ReLU',
ffn_drop=0.,
):
super(FFN, self).__init__()
self.l1 = nn.Linear(in_features=embed_dim, out_features=feedforward_channels)
if act_cfg == 'ReLU':
self.act1 = nn.ReLU(inplace=True)
else:
self.act1 = nn.SiLU(inplace=True)
self.d1 = nn.Dropout(p=ffn_drop)
self.l2 = nn.Linear(in_features=feedforward_channels, out_features=embed_dim)
self.d2 = nn.Dropout(p=ffn_drop)
def forward(self, x):
tmp = self.d1(self.act1(self.l1(x)))
tmp = self.d2(self.l2(tmp))
x = tmp + x
return x
# transfomer encode和decode的最小循环单元,用于打包self_attention或者cross_attention
class BaseTransformerLayer(nn.Module):
def __init__(self,
attn_cfgs=[dict(embed_dim=64, num_heads=4), dict(embed_dim=64, num_heads=4)],
fnn_cfg=dict(embed_dim=64, feedforward_channels=128, act_cfg='ReLU', ffn_drop=0.),
operation_order=('self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm')):
super(BaseTransformerLayer, self).__init__()
self.attentions = nn.ModuleList()
# 搭建att层
for attn_cfg in attn_cfgs:
self.attentions.append(MultiheadAttention(**attn_cfg))
self.embed_dims = self.attentions[0].embed_dim
# 统计norm数量 并搭建
self.norms = nn.ModuleList()
num_norms = operation_order.count('norm')
for _ in range(num_norms):
self.norms.append(nn.LayerNorm(normalized_shape=self.embed_dims))
# 统计ffn数量 并搭建
self.ffns = nn.ModuleList()
self.ffns.append(FFN(**fnn_cfg))
self.operation_order = operation_order
def forward(self, query, key=None, value=None, query_pos=None, key_pos=None):
attn_index = 0
norm_index = 0
ffn_index = 0
for order in self.operation_order:
if order == 'self_attn':
temp_key = temp_value = query # 不用担心三个值一样,在attention里面会重映射qkv
query, attention = self.attentions[attn_index](
query,
temp_key,
temp_value,
query_pos=query_pos,
key_pos=query_pos)
attn_index += 1
elif order == 'cross_attn':
query, attention = self.attentions[attn_index](
query,
key,
value,
query_pos=query_pos,
key_pos=key_pos)
attn_index += 1
elif order == 'norm':
query = self.norms[norm_index](query)
norm_index += 1
elif order == 'ffn':
query = self.ffns[ffn_index](query)
ffn_index += 1
return query
if __name__ == '__main__':
query = torch.rand(size=(10, 2, 64))
key = torch.rand(size=(5, 2, 64))
value = torch.rand(size=(5, 2, 64))
query_pos = torch.rand(size=(10, 2, 64))
key_pos = torch.rand(size=(5, 2, 64))
# encoder 通常是6个encoder_layer组成 每个encoder_layer['self_attn', 'norm', 'ffn', 'norm']
encoder_layer = BaseTransformerLayer(attn_cfgs=[dict(embed_dim=64, num_heads=4)],
fnn_cfg=dict(embed_dim=64, feedforward_channels=1024, act_cfg='ReLU',
ffn_drop=0.),
operation_order=('self_attn', 'norm', 'ffn', 'norm'))
encoder_layer_output = encoder_layer(query=query, query_pos=query_pos, key_pos=key_pos)
# decoder 通常是6个decoder_layer组成 每个decoder_layer['self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm']
decoder_layer = BaseTransformerLayer(attn_cfgs=[dict(embed_dim=64, num_heads=4), dict(embed_dim=64, num_heads=4)],
fnn_cfg=dict(embed_dim=64, feedforward_channels=1024, act_cfg='ReLU',
ffn_drop=0.),
operation_order=('self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm'))
decoder_layer_output = decoder_layer(query=query, key=key, value=value, query_pos=query_pos, key_pos=key_pos)
pass
具体流程说明:
Encoder 通常是6个encoder_layer组成,每个encoder_layer[‘self_attn’, ‘norm’, ‘ffn’, ‘norm’]
Decoder 通常是6个decoder_layer组成,每个decoder_layer[‘self_attn’, ‘norm’, ‘cross_attn’, ‘norm’, ‘ffn’, ‘norm’]
按照以上方式搭建网络即可
其中norm为LayerNorm,在样本内部进行归一化。
原文地址:https://blog.csdn.net/zwhdldz/article/details/135613995
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56584.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!