本文介绍: 1. 目的:了解什么是分布式SQL计算;了解什么是Apache Hive2. 使用Hive处理数据的好处操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手底层执行MapReduce,可以完成分布式海量数据的SQL处理3. 什么是分布式SQL计算?以分布式的形式,执行SQL语句,进行数据统计分析。4. Apache Hive是做什么的?很简单,是一款分布式SQL计算的工具,将SQL语句翻译成MapReduce程序,从而提供用户分布式SQL计算的能力。
一、 Apache Hive概述
1. 目的:了解什么是分布式SQL计算;了解什么是Apache Hive
2. 使用Hive处理数据的好处
3. 什么是分布式SQL计算?
以分布式的形式,执行SQL语句,进行数据统计分析。
4. Apache Hive是做什么的?
很简单,是一款分布式SQL计算的工具,将SQL语句翻译成MapReduce程序,从而提供用户分布式SQL计算的能力。
2. 模拟实现Hive功能
3. Hive基础架构

4. Hive部署
4.1 在VMware虛拟机集群中,完成Hive的安装部署
4.2 在阿里云中创建RDS作为Hive的元数据存储数据库,并完成Hive的安装部署
4.3 在Ucloud云中创建UDB作为Hive的元数据存储数据库,并完成Hive的安装部署
5. Hive初体验

6. Hive客户端
6.1 HiveServer2 & Beeline
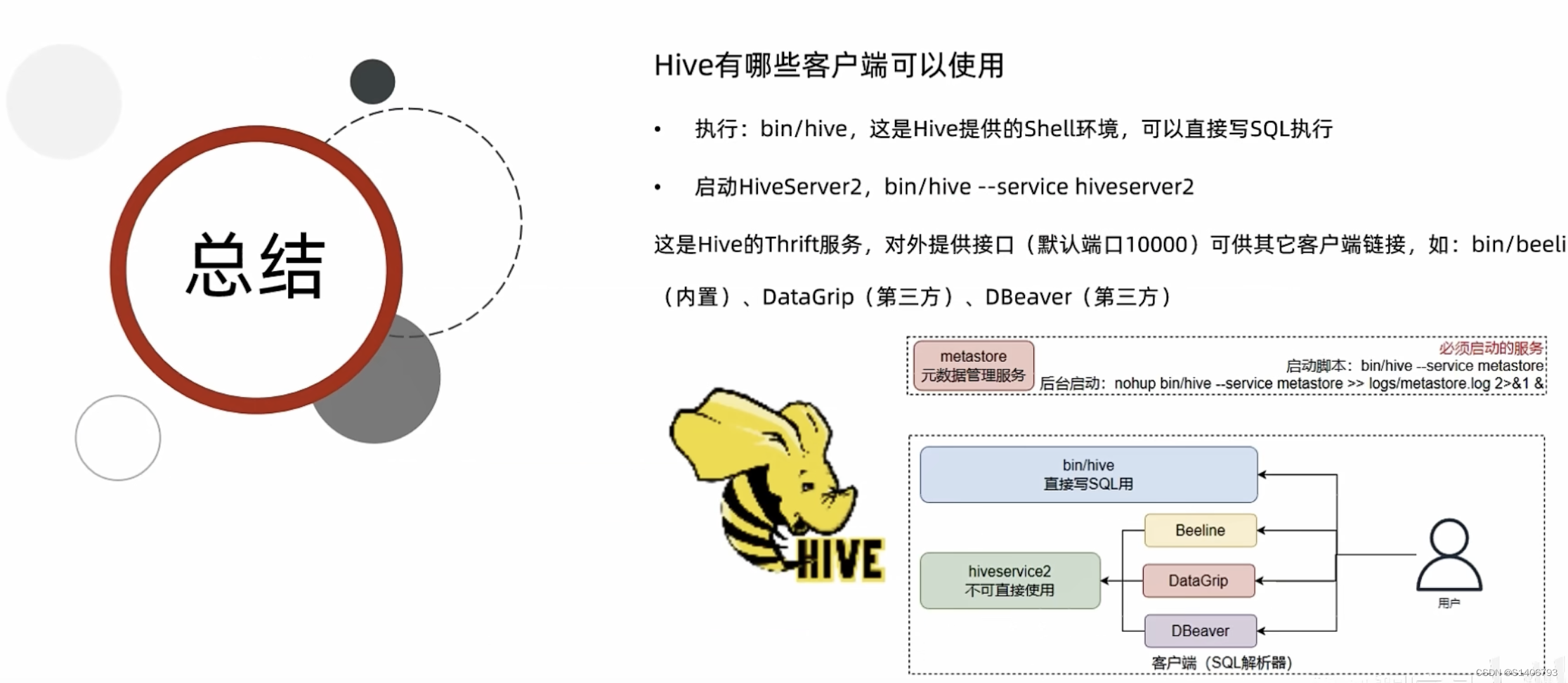
6.2 DataGrip & DBeaver
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







