本文介绍: 只不过运行过程变成了红色,但可以像普通python代码一样可以随时暂停。
一、网页信息
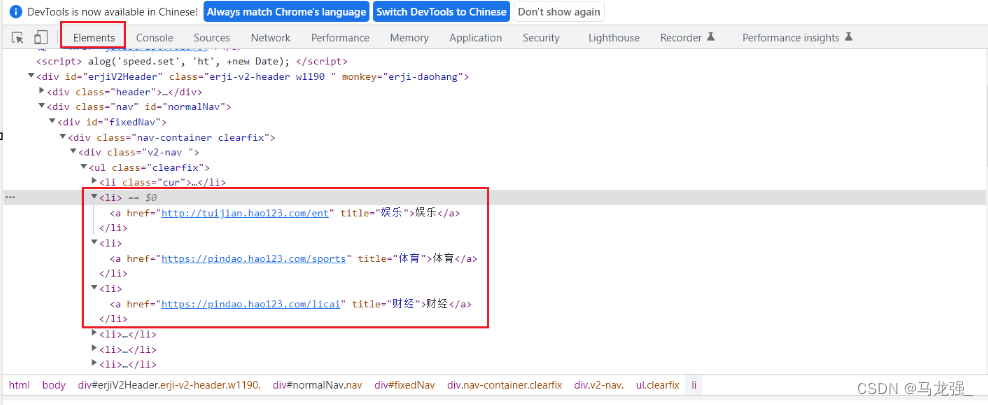
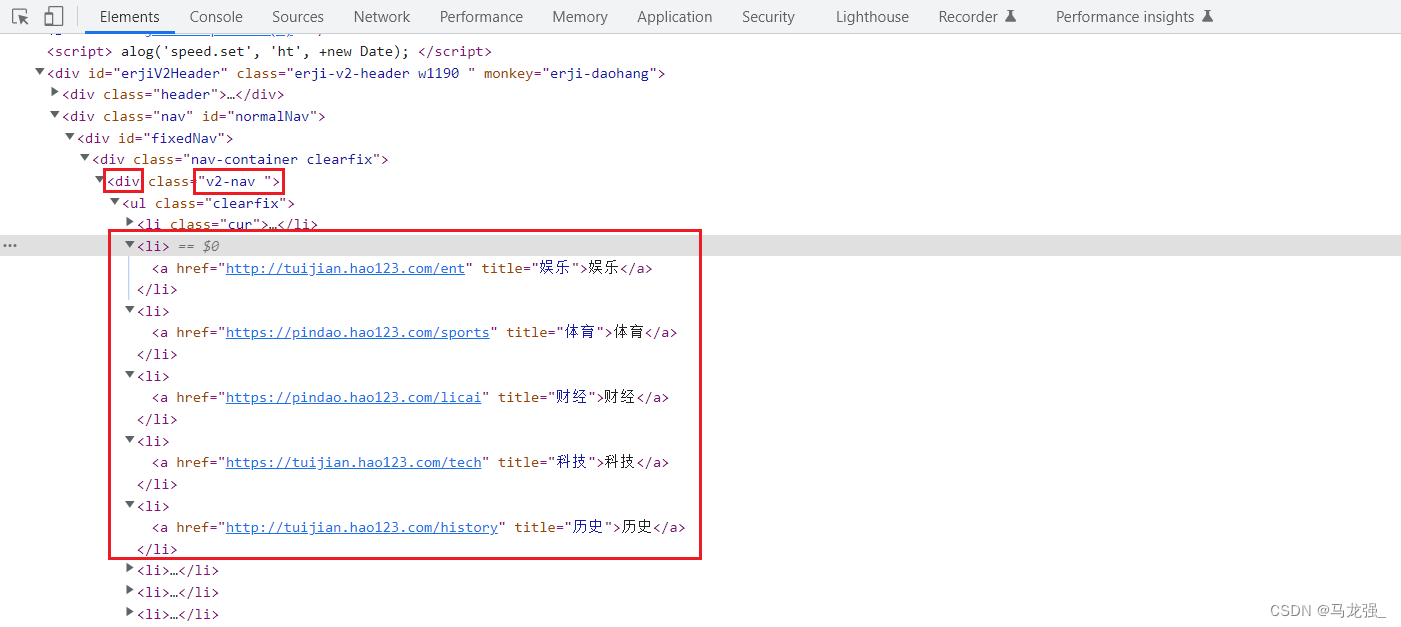
 二、检查网页,找出目标内容
二、检查网页,找出目标内容
三、根据网页格式写正常爬虫代码
四、创建Scrapy项目haohao
1.进入相关目录中,执行:scrapy startproject haohao
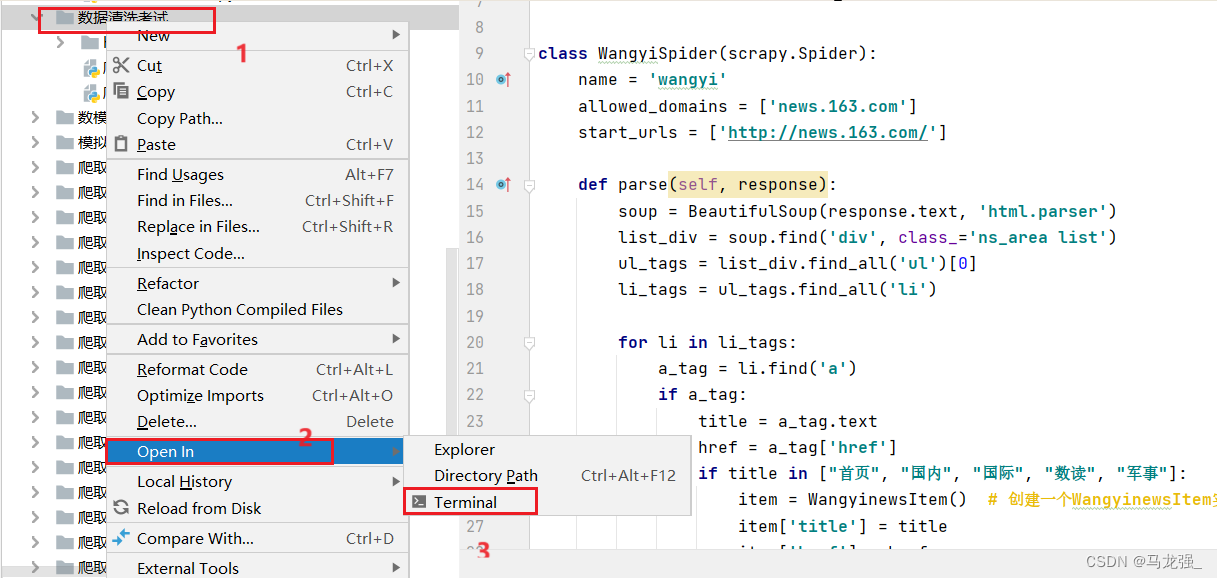
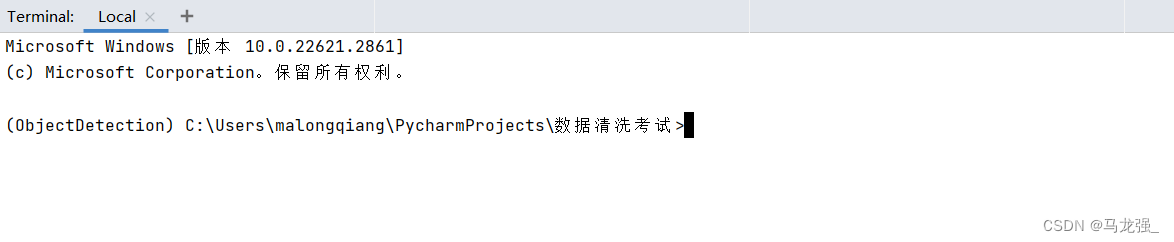
2.创建结果

五、创建爬虫项目haotuijian.py
1.进入相关目录中,执行:scrapy genspider haotuijian http://tuijian.hao123.com/

2.执行结果,目录中出现haotuijian.py文件
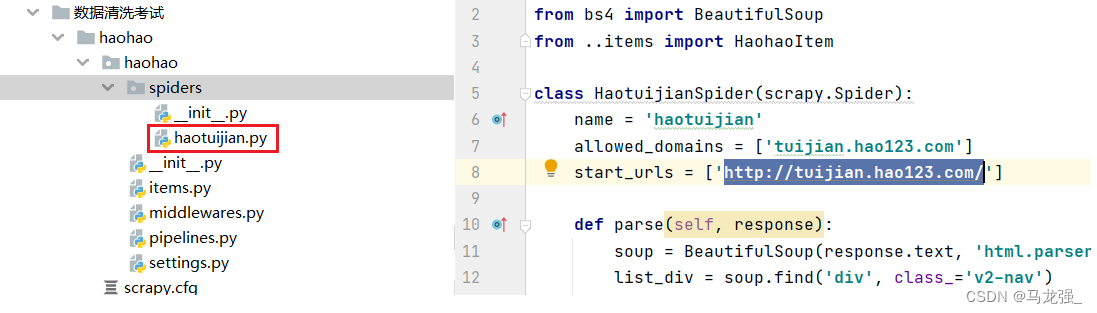
六、写爬虫代码和配置相关文件
1.haotuijian.py文件代码
2.items.py文件代码
3.pipelines.py文件代码(保存数据到Mongodb、Mysql、Excel中)
4.settings.py文件配置



七、运行代码
1.进入相关目录,执行:scrapy crawl haotuijian
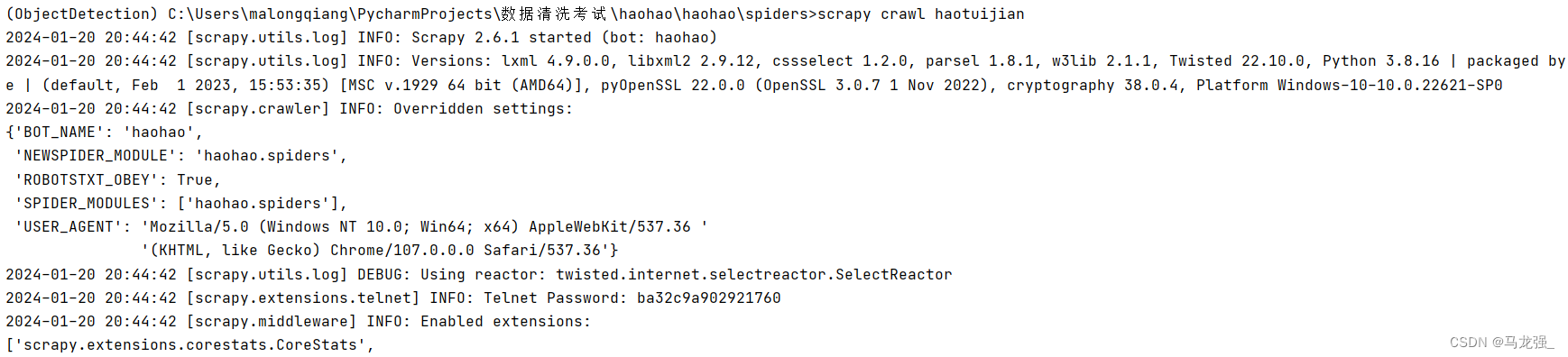
2.执行过程
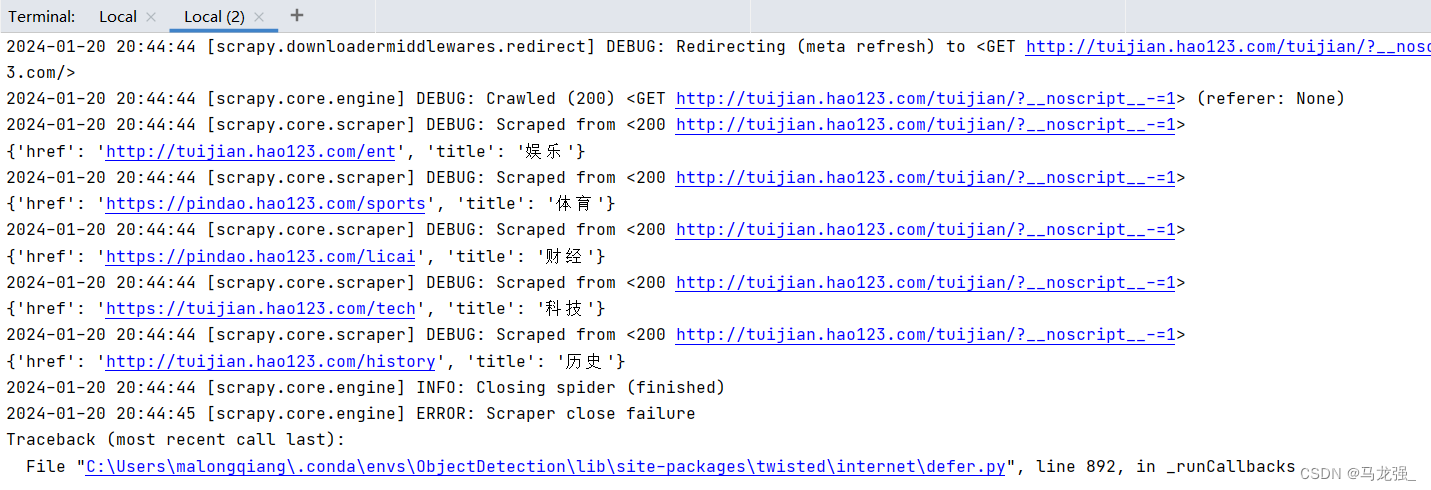
3.执行结果
(1) haohao.excel
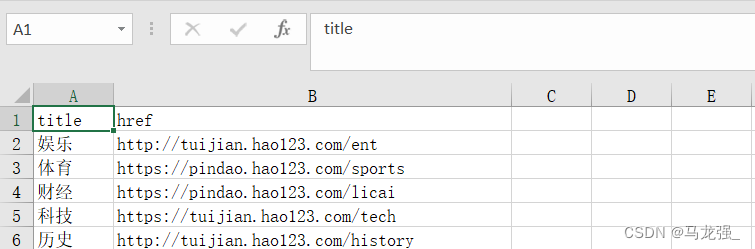
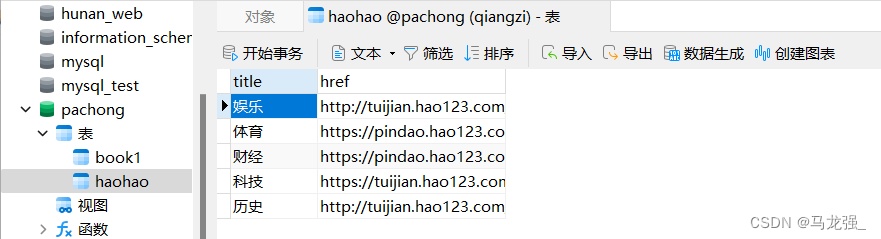
(2) Mysql:haohao (需提前创建表)
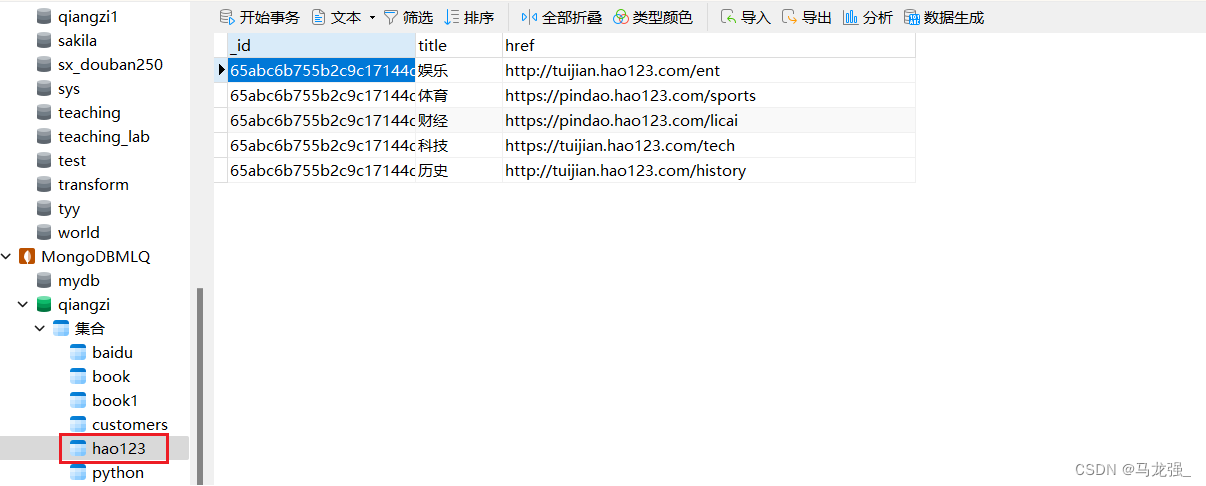
(3)Mongodb: hao123
八、知识补充
1.创建main.py文件,并编写代码
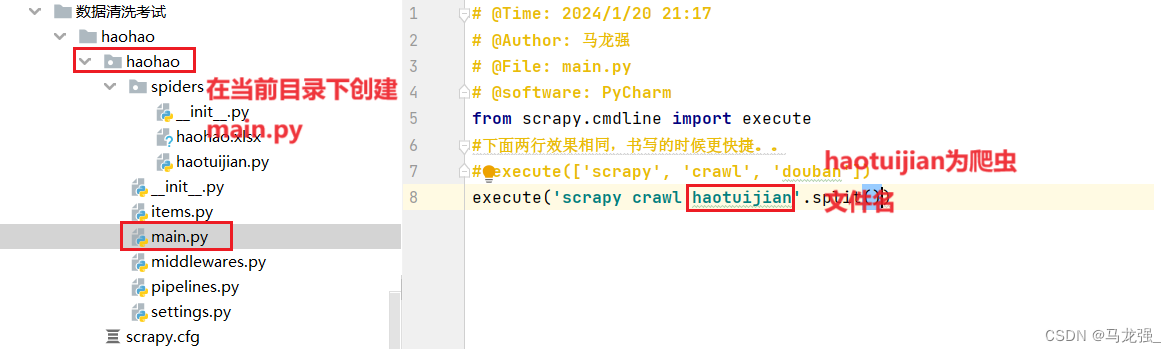
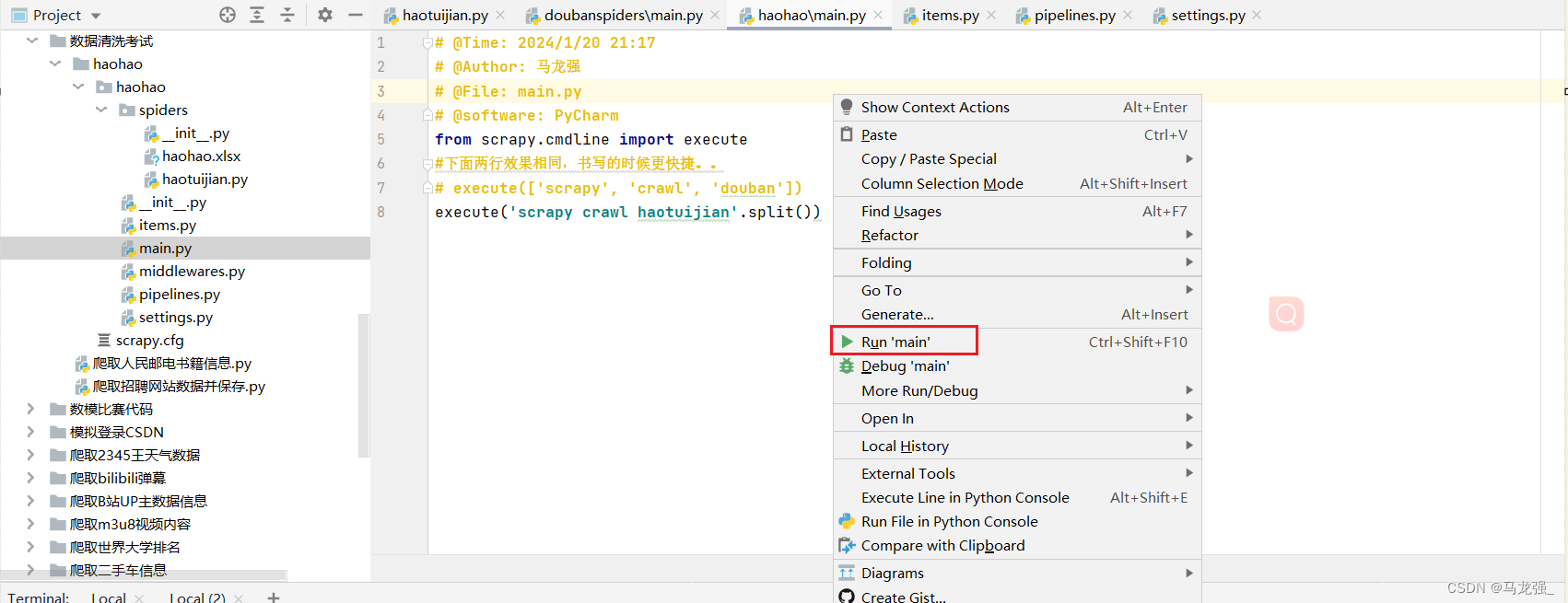
2.直接运行main.py文件
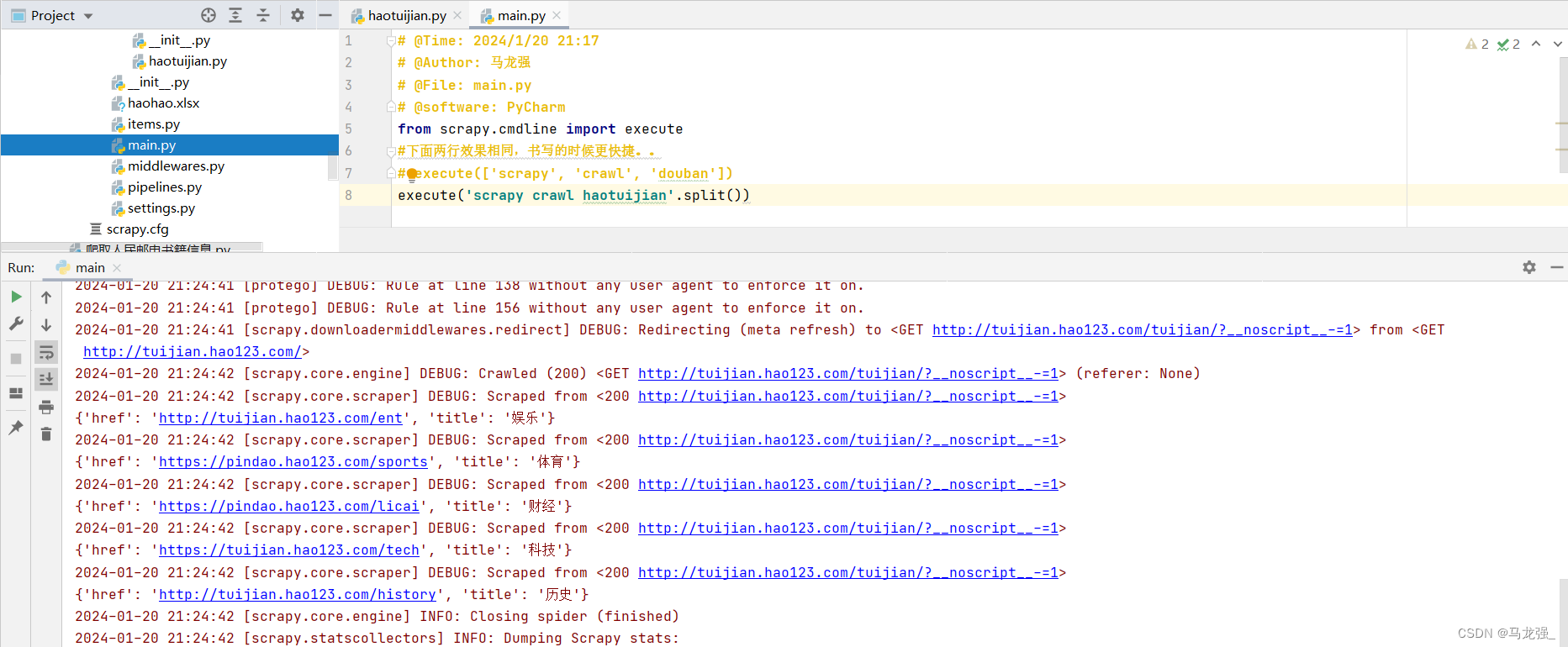
3.运行结果与使用指令运行结果相同(只不过运行过程变成了红色,但可以像普通python代码一样可以随时暂停)
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。