本文介绍: 给住院病人分配icd诊断编码通常是专业的人类编码专家的工作。在人工智能领域,主要的方向是通过有监督深度学习模型来进行自动icd编码。然而,学习如何预测大量的罕见编码仍然是临床实践中存在的困难。因此本文尝试利用现成的大语言模型来尝试开发一个零样本和少样本的编码对齐方案,尝试避开特定任务的训练过程。由于无监督的预训练并不能保证对于ICD本体和临床编码任务的准确性,因此本文将任务视为信息抽取。让大语言模型根据提供的编码概念来进行相关提及的抽取。

Tags: Diagnosis Prediction, LLM
Authors: Alison Q. O’Neil, Antanas Kascenas, Joseph S. Boyle, Maria Liakata, Pat Lok
Created Date: January 18, 2024 3:57 PM
Status: Reading
organization: Anglia Ruskin University, Canon Medical Research Europe, Queen Mary University of London, The Alan Turing Institute, University of Edinburgh, University of Warwick
介绍
方法
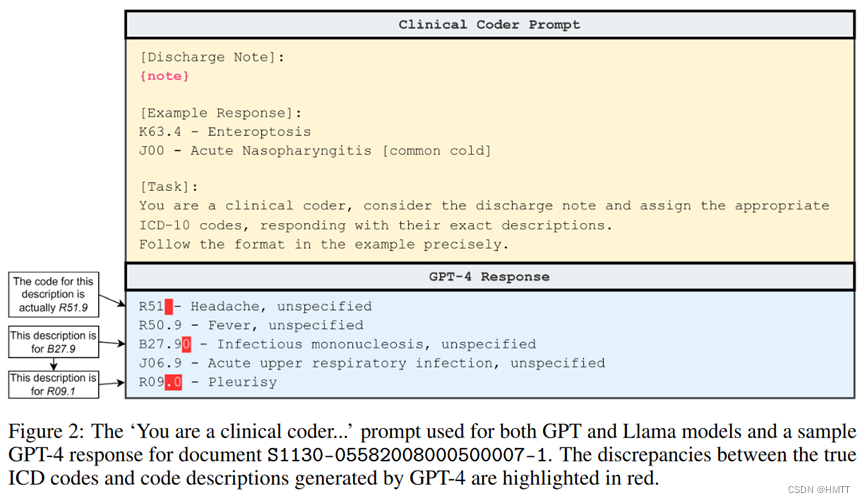
信息检索形式

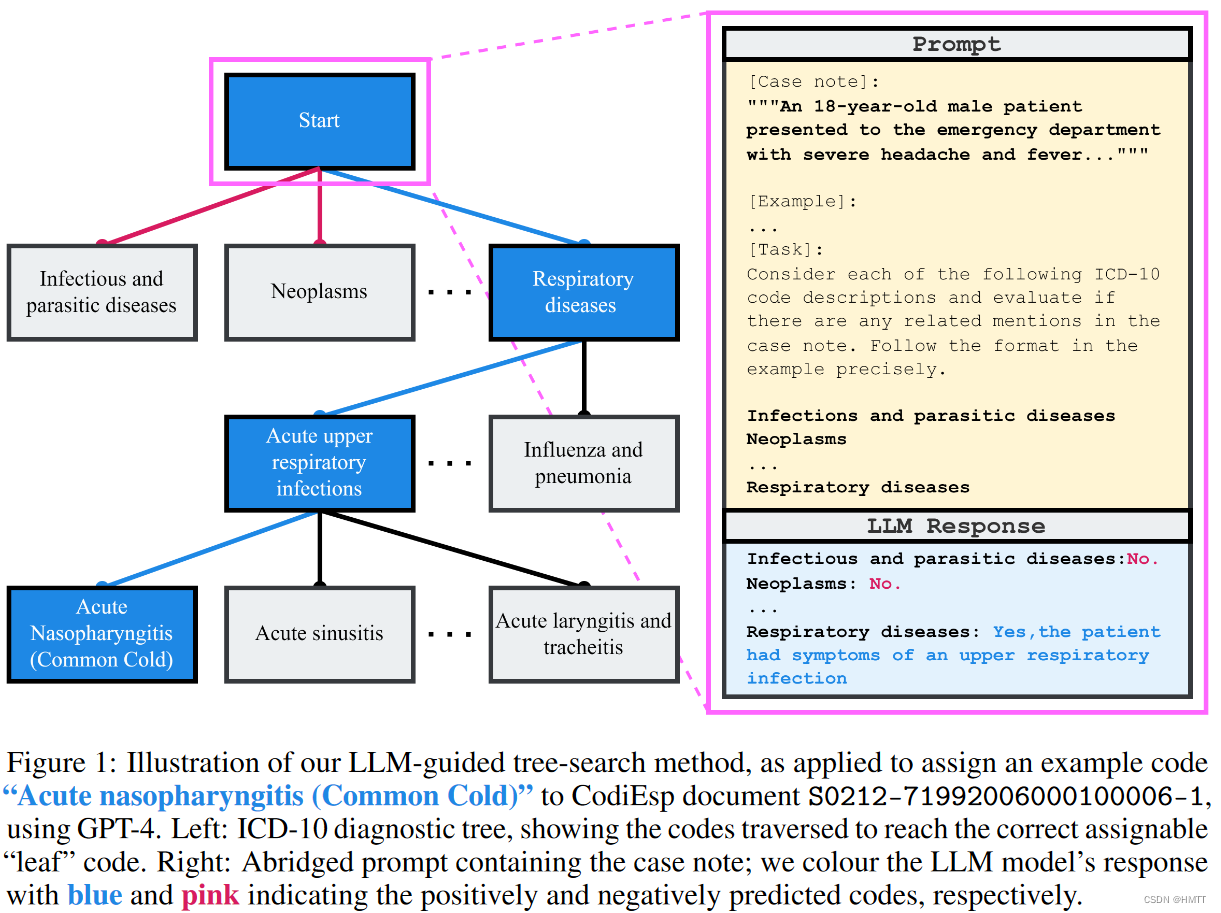
树形搜索
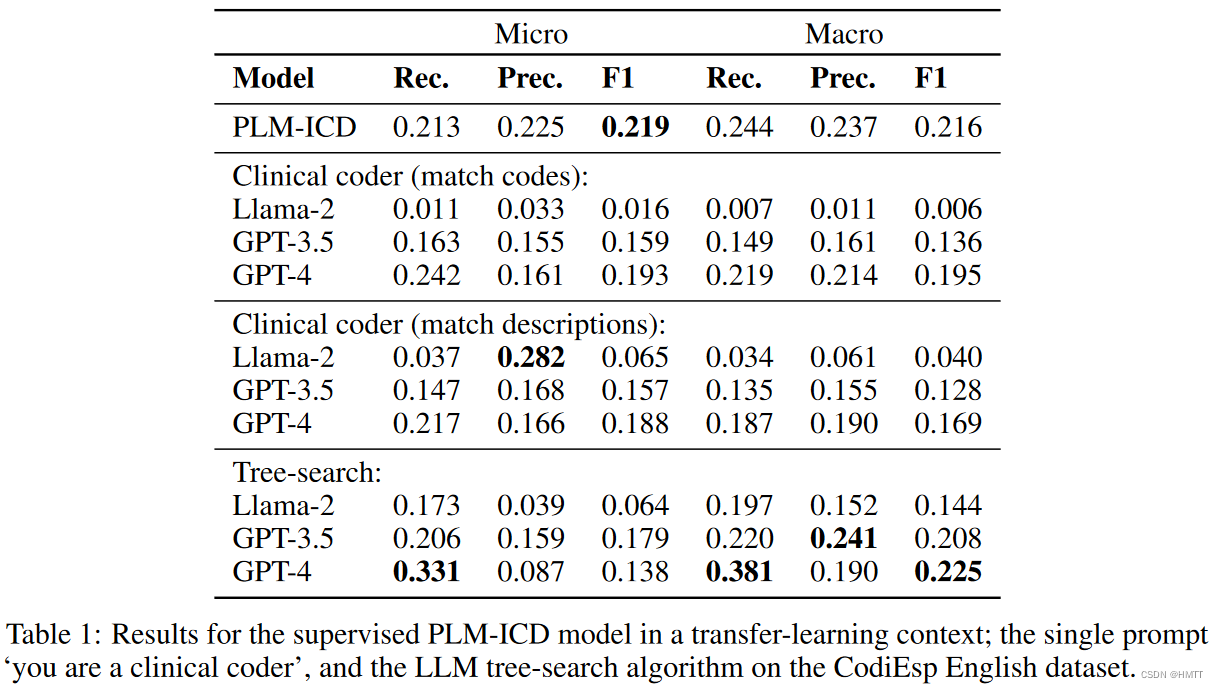
实验

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





