本文介绍: 大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用33零门槛实现模型在多个GPU的分布式流水线训练的应用技巧,本文将帮助大家零门槛的实现模型在多个GPU的并行训练,如果你手头上没有GPU资源,根据本文的介绍也可实现模型的并行,让大家了解模型的并行是怎么实现的,揭开模型分布式训练的神秘面纱,提升自己的模型训练水平。在大规模语言模型训练领域迈进自己的脚步。
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用33零门槛实现模型在多个GPU的分布式流水线训练的应用技巧,本文将帮助大家零门槛的实现模型在多个GPU的并行训练,如果你手头上没有GPU资源,根据本文的介绍也可实现模型的并行,让大家了解模型的并行是怎么实现的,揭开模型分布式训练的神秘面纱,提升自己的模型训练水平。在大规模语言模型训练领域迈进自己的脚步。

一、 神经网络模型并行的介绍
神经网络模型并行广泛应用于分布式训练技术中,本文展示了如何通过使用模型并行来解决多个GPU训练的问题,与DataParallel不同,模型并行将单个模型分割到不同的GPU上,而不是将整个模型复制到每个GPU上(假设一个模型M包含10层:使用DataParallel时,每个GPU将拥有这10层的副本,而在使用模型并行在两个GPU上时,每个GPU可能托管5层)。
模型并行的思想是将模型的不同子网络放置到不同的设备上,并相应地实现前向方法以跨设备移动中间输出。由于只有模型的某部分在单个设备上运行,因此一组设备可以共同服务于更大的模型。本文的的重点是将模型并行的思路展示给大家。
分布式流水线模型训练
分布式模型训练通常指的是在多个计算节点上并行地训练机器学习模型。这种训练方式可以提高模型训练的速度,尤其是在处理大规模数据集和复杂模型时。分布式训练可以通过不同的并行策略来实现,例如数据并行、模型并行、流水线并行等。以下是这些并行策略的一些基本数学原理:
1.数据并行(Data Parallelism):
数据并行是最常见的并行策略。在这种策略中,训练数据被分成多个部分,每个计算节点(或设备)独立地在自己的数据部分上训练完整的模型,并定期同步参数更新。
假设我们有一个损失函数
L
(
二、构建两个GPU的环境
三、将模型并行应用于现有模块
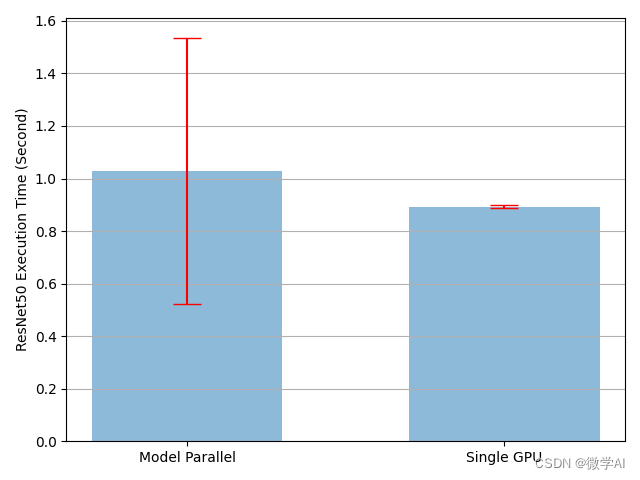
单个模型训练与并行模型时间比较
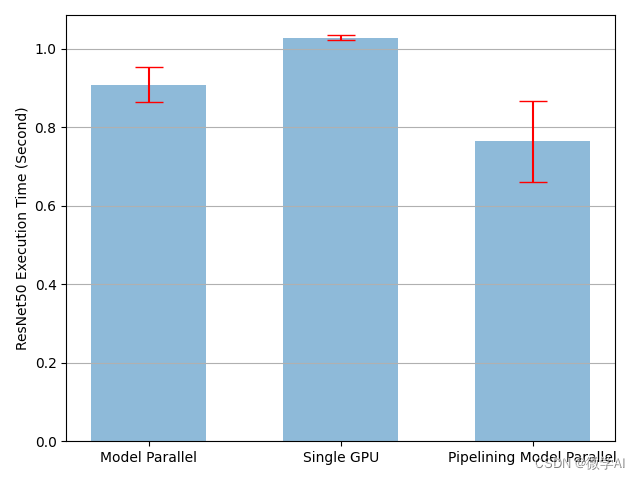
通过流水线输入加速的比较
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






