前面我们说了mybatis的缓存设计体系,这里我们来正式看一下这玩意到底是咋个用法。
首先我们是知道的,Mybatis中存在两级缓存。分别是一级缓存(会话级),和二级缓存(全局级)。
下面我们就来看看这两级缓存。
一、准备工作
1、准备数据库
在此之前我们先来准备一个数据库,并且设计一个表user用户表,加几条数据进去。
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(32) NOT NULL COMMENT '主键id',
`name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '名字',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, '张飞');
INSERT INTO `user` VALUES (2, '关羽');
INSERT INTO `user` VALUES (3, '孙权');
SET FOREIGN_KEY_CHECKS = 1;
2、然后我们创建一个mybatis中的DAO接口。
public interface IUserDao {
// 查询所有用户
List<User> findAll();
}
3、创建UserMapper.xml文件
<mapper namespace="com.yx.dao.IUserDao">
<select id="findAll" resultType="com.yx.domain.User" statementType="CALLABLE">
SELECT * FROM `user`
</select
</mapper>
4、创建Mybatis核心配置文件
<configuration>
<!--加载外部properties文件,位置必须在第一个-->
<properties resource="jdbc.properties"/>
<settings>
<!-- 控制台输出sql语句 -->
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
<typeAliases>
<!--给单独的实体类取别名-->
<!--<typeAlias type="com.lwq.domain.User" alias="user"/>-->
<!--批量给实体类取别名:指定包下面所有的类的别名默认为其类名,不区分大小写-->
<package name="com.yx.domain"/>
</typeAliases>
<environments default="development">
<!--开发环境,可以配置多套环境,default指定用哪个-->
<environment id="development">
<!--當前事務交給jdbc處理-->
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="UserMapper.xml"/>
</mappers>
</configuration>
5、创建jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql:///mybatis22
jdbc.username=root
jdbc.password=root
好了,我们现在可以使用mybatis来操作数据库了。
二、一级缓存
1、验证
一级缓存在mybatis中是默认开启的,我们先来测试一下,他到底存在不存在,并且是不是能用,是不是默认开启的。我们来做一个测试代码。
@Test
public void test1() throws IOException {
// 读取配置文件转化为流
InputStream inputStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = factory.openSession();
//这⾥不调⽤SqlSession的api,⽽是获得了接⼝对象,调⽤接⼝中的⽅法。使用JDK动态代理产生代理
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
// 第一次执行查询
List<User> userList = userDao.findAll();
userList.forEach(user -> {
System.out.println(user.toString());
});
System.out.println("*************************************************");
// 第二次执行相同的查询
List<User> userList2 = userDao.findAll();
userList2.forEach(user -> {
System.out.println(user.toString());
});
}
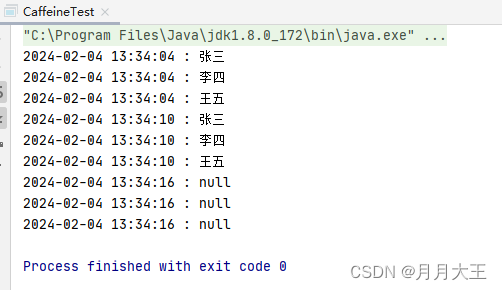
这里我们做了两次查询,第一次和第二次的查询是一模一样的,如果存在缓存,那它一定第二次就不会去查数据库
了,下面我们来验证一下。
输出如下:
Opening JDBC Connection
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Created connection 1011044643.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@3c435123]
==> Preparing: SELECT * FROM `user`
==> Parameters:
<== Columns: id, name
<== Row: 1, 张飞
<== Row: 2, 关羽
<== Row: 3, 孙权
<== Total: 3
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
*************************************************
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
我们看到第一次调用进行了创建connection连接,下面执行了sql,然后输出,但是第二次再执行,他就不会再去查库了,而是直接输出了缓存,这就说明了这个缓存是存在并且开启的。
2、注意
2.1、注意点1
一级缓存只在当前sqlsession中生效,也就是他是会话级别的,每一次连接内的多次相同查询可以共享这次缓存,如果你换了sqlsession,新的sqlsession和其他的sqlsession的查询是不能共享缓存使用的。下面我们来验证一下。
@Test
public void test2() throws IOException {
// 读取配置文件转化为流
InputStream inputStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = factory.openSession();
SqlSession sqlSession2 = factory.openSession();
//这⾥不调⽤SqlSession的api,⽽是获得了接⼝对象,调⽤接⼝中的⽅法。使用JDK动态代理产生代理对象
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
IUserDao userDao2 = sqlSession2.getMapper(IUserDao.class);
// 第一次执行查询
List<User> userList = userDao.findAll();
userList.forEach(user -> {
System.out.println(user.toString());
});
System.out.println("*************************************************");
// 第二次执行相同的查询
List<User> userList2 = userDao2.findAll();
userList2.forEach(user -> {
System.out.println(user.toString());
});
}
我们开启创建了两个不同的sqlSession分别是sqlSession和sqlSession2,然后执行相同的查询。
输出如下:
Opening JDBC Connection
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Created connection 1011044643.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@3c435123]
==> Preparing: SELECT * FROM `user`
==> Parameters:
<== Columns: id, name
<== Row: 1, 张飞
<== Row: 2, 关羽
<== Row: 3, 孙权
<== Total: 3
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
*************************************************
Opening JDBC Connection
Created connection 156199931.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@94f6bfb]
==> Preparing: SELECT * FROM `user`
==> Parameters:
<== Columns: id, name
<== Row: 1, 张飞
<== Row: 2, 关羽
<== Row: 3, 孙权
<== Total: 3
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
此时我们就看到,第二次查询并没有利用到缓存,而是又开始了一次新的查询。所以这种跨sqlsession是不能使用缓存的。不是不存在,而是使用不到。
2.2、注意点2
我们既然知道了在sqlseeion不同的时候,缓存是不能利用的,那么问题来了,你的以后的日常开发中这个sqlsession他会经常变吗,如果变了,那岂不是走不了缓存了。
实际上就是经常变的,比如你页面上有一个按钮就是搜索,每次都会查询数据库,实际上你每次点击都会建立新的sqlsession,因为这玩意是伴随着连接的。你每次请求都会创建新的连接,那你的缓存就没用,除非你在你的service里面连着调用了两次一样的查询,这个,,,你没事吧。
所以你的一级缓存大部分情况下,没卵用。
那你为啥说每次请求都是单独的sqlSession或者单独的jdbc connection呢,因为这里牵扯到要控制事务,不同请求必须是独立隔离的连接,这样才能独立控制事务,如果共享事务,可能会造成混乱。比如请求1,请求2开启一个连接,那请求1还没完呢,你请求2就提交了事务,这不就寄了。
2.3、注意点3
那么查询是不是不需要事务呢,查询是不是就可以共享连接了,不对,查询也需要,select后面可以加锁。需要事务。
后面的二级缓存,这里也是需要的。后面我们再说,而且设计的时候肯定是统一处理的,不会说为了你一个加锁或者二级缓存就去区分开代码处理。
所以基于一级缓存的苛刻条件,我们知道这个一级缓存其实在使用者层面,他用处不大,实际上他也是在内部他自己的使用的。
既然我们说了他没啥用,那他设计出来干嘛呢,必然是有用处,下面我们来看下源码来分析一下他的用处。但是在进入源码之前,我们先来看一个设计模式,就是适配器设计模式。
3、适配器设计模式
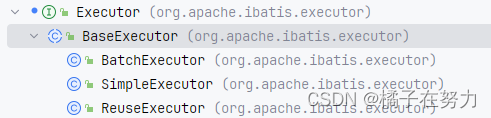
我们在前面看到了mybatis的设计结构,大致如下。

我们看到首先他是一个Executor的接口,然后下面一个BaseExecutor来实现了这个接口,下面又是三个子类继承了BaseExecutor这个类,这其实就是一个适配器模式。我们看下他的类结构。
1、什么是适配器。
这个玩意一般资料都会拿出一个电压的例子,比如中国的常规电压是220伏特,人能承受的大概是36伏特,那我们要是碰到220伏特就寄了,于是我们可以使用一个变压器,放在中间。

这个变压器的作用就是适配器,这个例子你是不是在无数地方都看吐了,我们还是直接在代码说吧。
比如此时有一个Servlet的接口,里面有五个接口(我简化了一下)。
public interface Servlet {
void init();
void service();
void destory();
String getServletInfo();
void getServletConfig();
}
此时我想实现一个自己的Servlet就叫做MyServlet,其中我只想实现 String getServletInfo();这个方法,但是java的语法就是我只要实现这个接口,就得实现他所有的方法,这个压力太大,等于直接把220V的电压给我了,我不想这么整,所以此时需要一个变压器。也就是适配器登场。
此时我们在创建一个类,去实现这个接口,如下:
public abstract class MyServletAdapter implements Servlet{
@Override
public void init() {}
@Override
public void service() {}
@Override
public void destory() {}
@Override
public String getServletInfo() {return null;}
public abstract void getServletConfig();
}
你看到我们此时实现了这个接口,并且实现了其中四个方法,最后一个我们做成了抽象方法,其他四个你想不想实现看你。最后一个我们做成抽象的,给我们自己的那个servlet去实现。
于是就变为这样、
public class MyServlet extends MyServletAdapter{
@Override
public void getServletConfig() {
System.out.println("我自己的servlet实现单独的一个方法");
}
}
此时我们的这个类就完成了变压器到达终端,此时就只需要实现一个即可,而因为这个在变压器里面是抽象方法,所以这里是存在必须实现的约束的。还是有接口的作用。这就是适配器模式。
2、mybatis中的适配器
这样我们知道了适配器模式,那么其实上面那张图中的BaseExecutor就是适配器了。

BaseExecutor把接口中的一部分方法实现了,没实现的最后交个那三个子类各自实现各自定制化的东西,而公共的则由适配器里面去实现了。子类里面的还能用这些公共的,节省了代码量。这和模板设计模式很像。但虽然像,只是他们实现过程中表现出来的抽象,因为设计模式都是为了复用,抽象,扩展这些特点的,而适配器模式实际上出发点他是为了”变压”。
4、一级缓存的静态源码分析
我们说其实不管你哪个Excutor子类都是有这个缓存的,所以我么能猜出来,这个缓存功能其实是放在适配器里面的公共部分让子类使用的,我们看下这个适配器BaseExecutor。
public abstract class BaseExecutor implements Executor {
......
protected PerpetualCache localCache;// 一级缓存
protected PerpetualCache localOutputParameterCache;// 存储过程的,一般不用
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 根据你传进来的参数,动态生成sql,返回的boundSql就有这个sql
BoundSql boundSql = ms.getBoundSql(parameter);
// 为本次查询创建缓存的key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
//重载方法,实现查询
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
// 在这里重载
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
// 判断执行器是不是被关闭,关闭直接抛出异常
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空本地缓存,如果queryStack为0,就要清空本地缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// localCache.getObject(key)取出一级缓存里面的查询结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 如果缓存中有,就直接返回缓存的
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//如果缓存中没有本次查找的值,那么queryFromDatabase方法从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 执行延迟加载
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 在缓存中添加占位对象,此处的占位符和延迟加载有关,见DeferredLoad#canLoad()
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//doQuery是真正的最后的去执行读操作
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 从缓存中溢出占位对象
localCache.removeObject(key);
}
// 查询完把结果添加到缓存中
localCache.putObject(key, list);
// 暂时忽略,存储过程相关
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
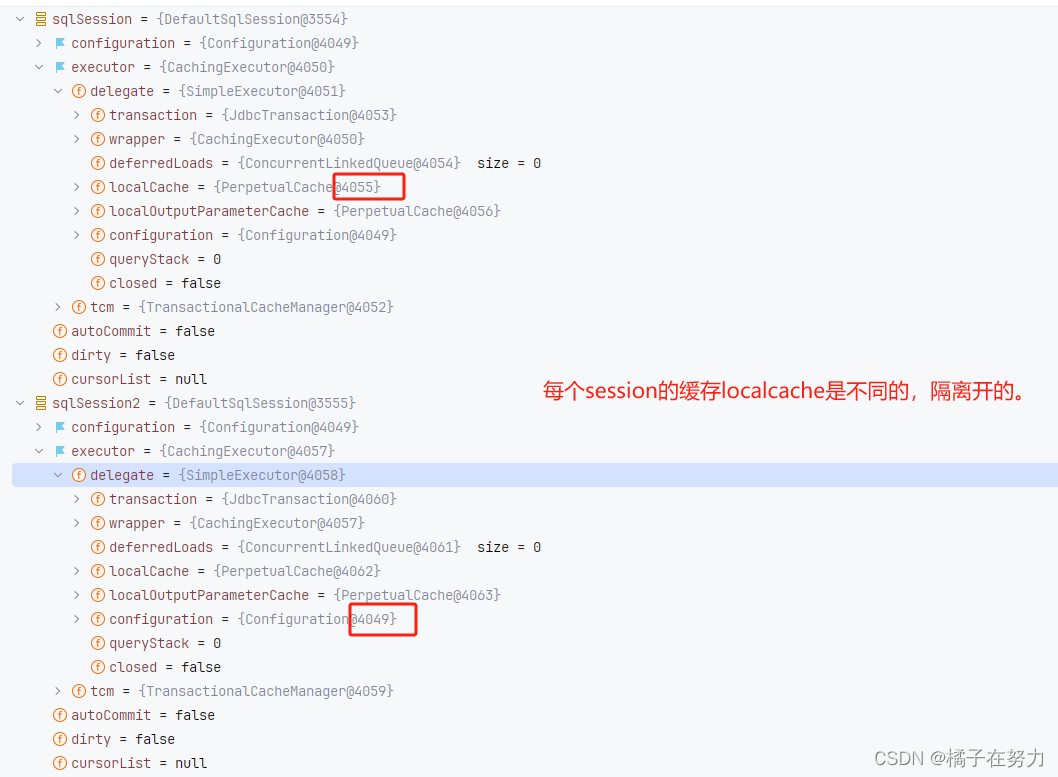
所以这里大致你能看到这个过程,就是他会读取缓存,没有缓存就去读取数据库,并且设置缓存,这是我们基于代码看到的效果,实际上的过程我们需要debug来看一下,就能看到如何读取,并且跨sqlSession是如何不生效的,这个可以直接在debug看到,每个sqlsession下面有不同的localCache,实现了缓存隔离。这个我们下面再来debug追踪源码。这里先简单贴个图。
原文地址:https://blog.csdn.net/liuwenqiang1314/article/details/135831384
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_61831.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!