本文介绍: Python爬虫是一种通过编程自动化地获取互联网上的信息的技术。
python爬虫基础
前言
Python爬虫是一种通过编程自动化地获取互联网上的信息的技术。其原理可以分为以下几个步骤:
1、python相关库(BeautifulSoup)
今天主要介绍一下BeautifulSoup模块
BeautifulSoup是一个用于从HTML或XML文档中提取数据的Python库。它的主要作用是解析复杂的HTML或XML文档,并提供了一种简单的方式来浏览文档树、搜索特定的标签、提取数据等。BeautifulSoup的设计目标是让数据提取变得容易、直观,并且具有Pythonic的风格。
2、BeautifulSoup模块的安装
安装命令
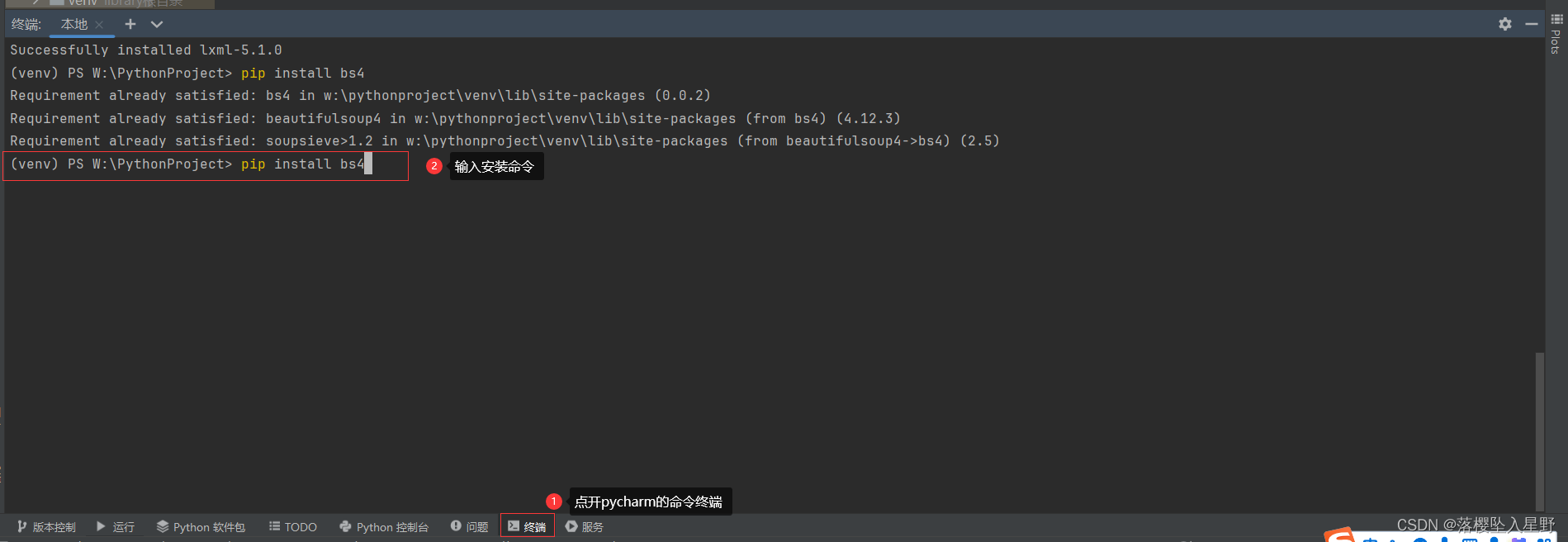
我这里是安装过了,第一次安装会出现suessful

3、BeautifulSoup的使用
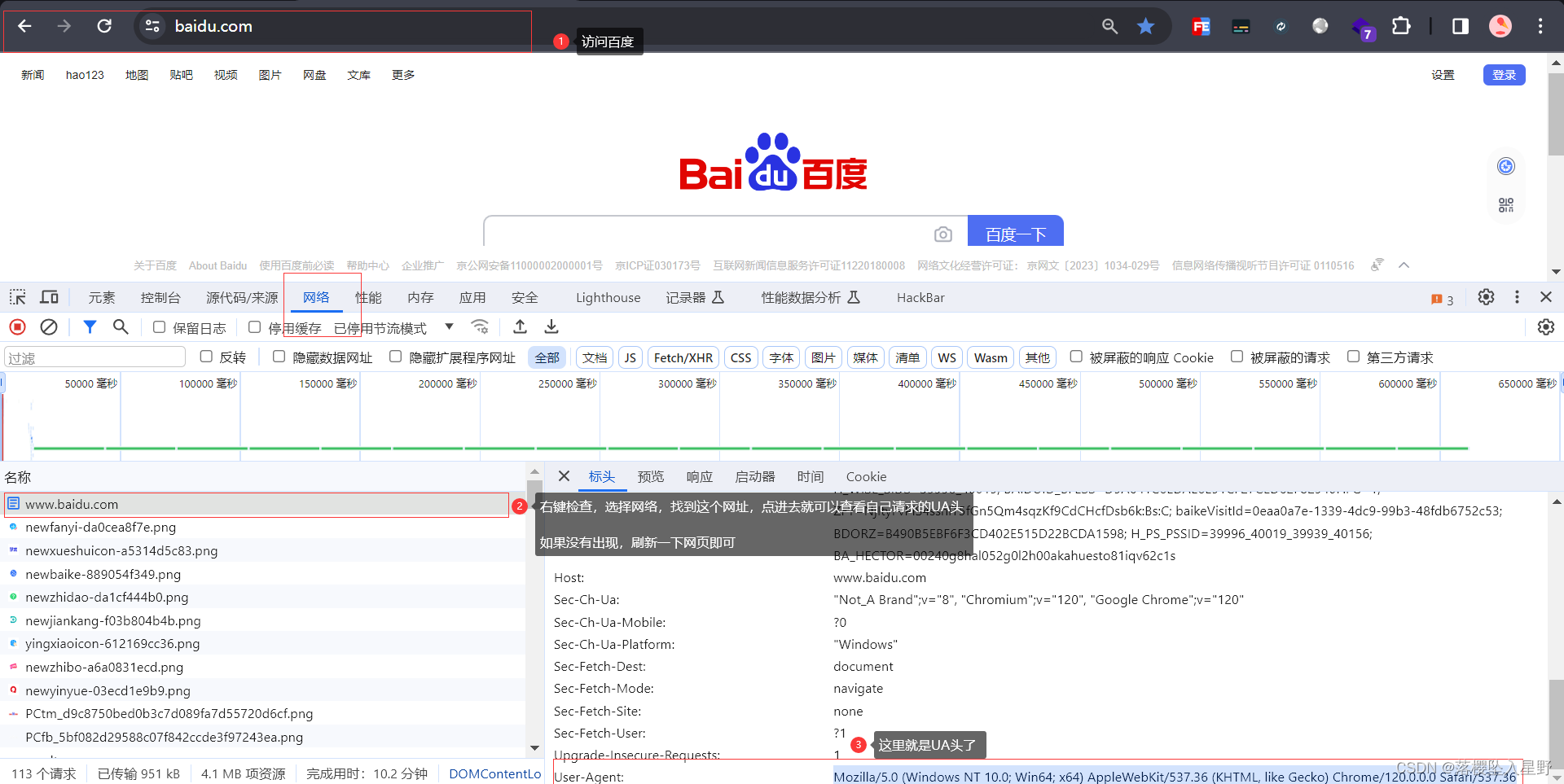
3.1 简单的使用(以百度为例)

3.2 soup.tagName的使用

3.3 soup.find

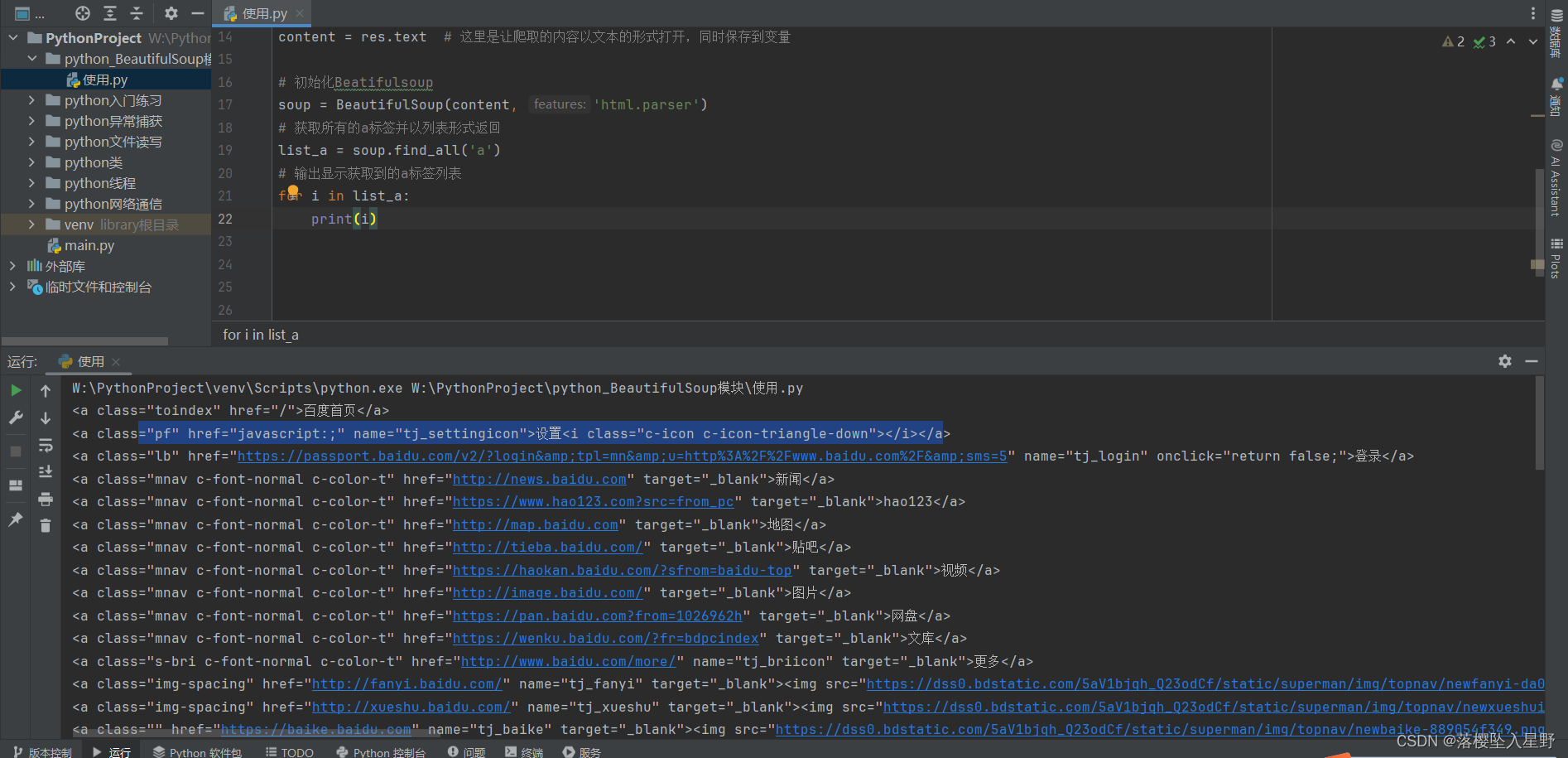
3.4 soup.find_all
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。