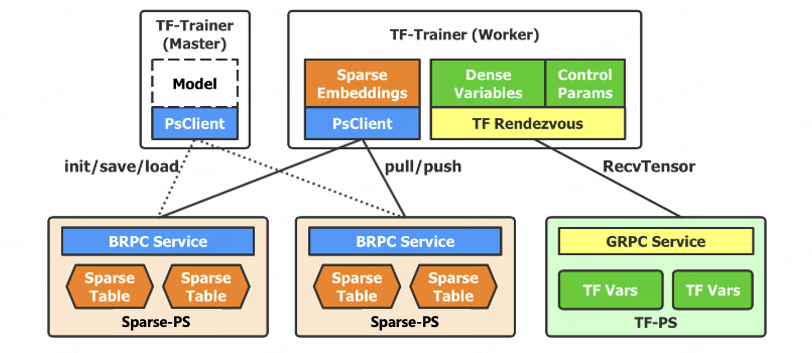
本文介绍: 强化学习表现出相当复杂度、对超参数的敏感性、在训练过程中的不稳定性,并需要在奖励模型和价值网络中进行额外的训练,导致了较大的计算成本。为了解决RL方法带来的上述挑战,提出了几种计算上轻量级的替代方案,在这些替代方案中,两个突出的范例包括对比学习和Hindsight指令重新标记(HIR),然而,无奖励微调容易受到训练集中包含的偏好注释响应对的嘈杂数据或不正确标签的影响。

1、写作动机:
强化学习表现出相当复杂度、对超参数的敏感性、在训练过程中的不稳定性,并需要在奖励模型和价值网络中进行额外的训练,导致了较大的计算成本。为了解决RL方法带来的上述挑战,提出了几种计算上轻量级的替代方案,在这些替代方案中,两个突出的范例包括对比学习和Hindsight指令重新标记(HIR),然而,无奖励微调容易受到训练集中包含的偏好注释响应对的嘈杂数据或不正确标签的影响。
几种方法的比较如下图:

2、主要贡献:
本研究从新兴的表示工程(RepE)领域汲取灵感,旨在识别嵌入在LLM活动模式中的高级人类偏好的相关表示,并通过转换其表示实现对模型行为的精确控制。这种新颖的方法,称为从人类反馈中的表示对齐(RAHF),被证明是有效的、计算高效的,并且易于实施。
3、方法:
通过一组偏好标注的响应对对LLMs进行人类偏好的指导。其次,我们收集LLMs在接收到偏好或不偏好的刺激时的活动模式。使用了两种新方法,用于对LLMs进行人类偏好的指导和提取它们的活动模式:一种涉及单个LLM(训练其区分响应相对质量的能力),另一种采用双LLMs(”好人”和”坏人”)。最后,通过训练一个低秩适配器来适应活动模式的差异,构建最终模型。
3.1单模型指导:
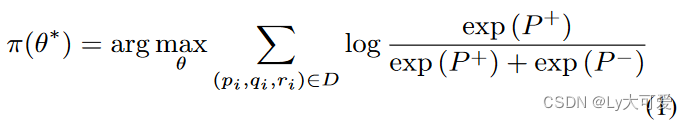

3.2双模型中的偏好指令:

3.3收集活动模式和构建最终模型:

4、实验:
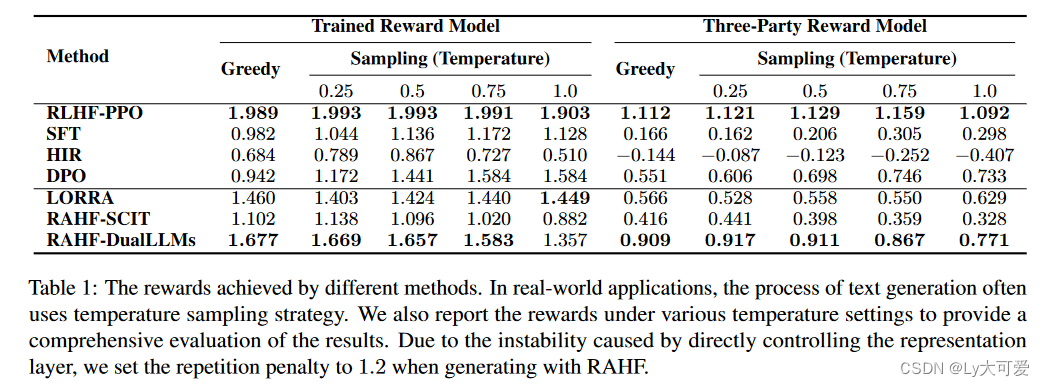
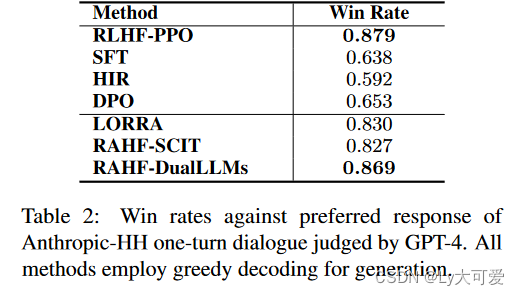
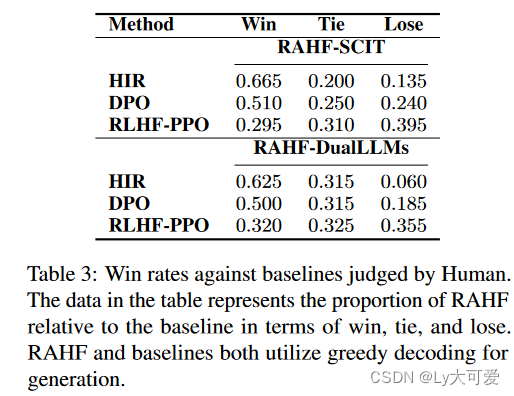
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。