本文介绍: 基于一些公开数据,像 GPT-4 这类千亿级别的大模型需要数万张 GPU 并行训练,当然还有配套的分布式存储和高速网络,这么复杂的系统可以平稳运行本身就是一个挑战,同时如何在故障发生时能快速精准定位,可以更快速的恢复,都是需要解决的核心问题。大模型参数多计算量大,听起来似乎和敏捷并没有太大关联,但是基于刚才介绍的大模型训练新范式,一方面模型本身的设计成本更低,另外一方面整个行业都在高速迭代中,所以需要基础设施具备快速构建能力,同时有比较低的学习成本,可以快速和开源生态对接,利用开源生态已有的能力。
今天的分享是百度智能云在 23 年夏季推出的「云智公开课 — AI 大底座系列」第 8 期,也是本次活动的最后一期。前面 7 期的内容,我的同事对大模型场景涉及到的各个模块,从网络、计算、存储、向量数据库、AI 框架、LMOps 等维度,为大家做了一个全景的展示,分享了百度智能云在这些领域的技术积累和项目实践。
本次我的分享主题在技术上算是对前面内容的综合,将围绕百舸在大模型训练过程的稳定性设计和加速实践展开,包括以下 3 个部分:
1. 大模型时代的百舸异构计算平台
下图列举了众多国产大模型,里面有通用的大模型,也有面向行业的垂类大模型,「百模大战」可见一斑。
为什么会在短期内出现这么多的大模型呢?这和大模型新的训练范式以及开源模型生态快速发展有极大关系。我列举了三种大模型的训练方式,从上往下看,成本由低到高变化。
首先是高效参数调优,也就是基于一个已有的通用大模型,使用少量有标注的数据,调整部分模型参数,得到符合面向特定场景的模型,具体的细分方法包括 Prefix-tuning,Prompt-tuning,LoRA 等。在第 7 期的公开课中已经给大家做了较为详细的介绍。
其次是 SFT 指令微调,也就是使用少量或者中量的有标注数据,对通用大模型做全量参数的调整。由于市面上有比较多的像 Llama、GLM 等优秀的开源大模型以及像百度文心系列商业大模型,所以很多客户会选择这种方案来构建自己的行业大模型。


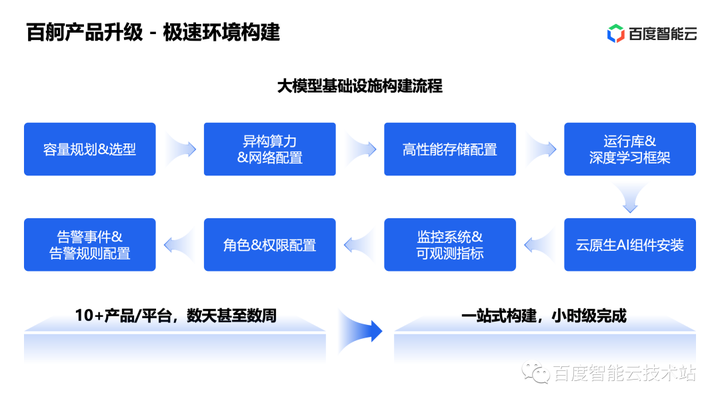


2. 大模型训练稳定性实践


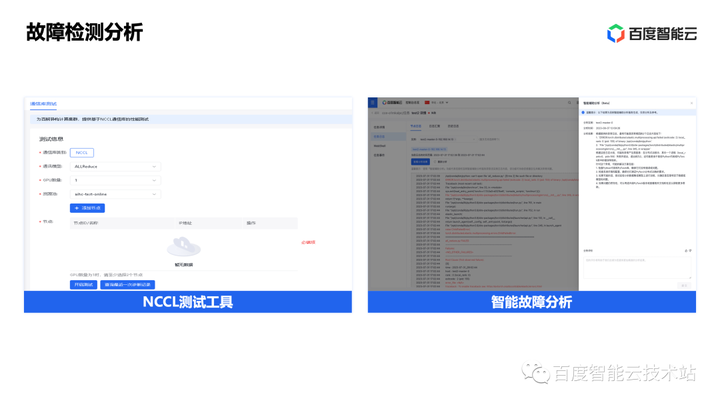
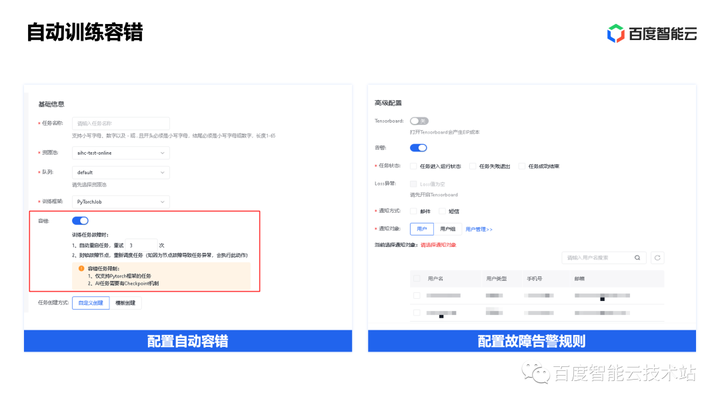

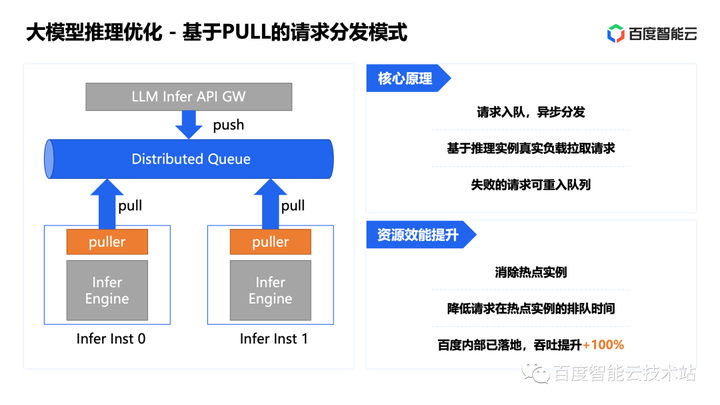
3. 大模型训推加速实践





声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






