本文介绍: 前面的一些分析,都是本人使用Python,对数据一步步分析得出的一些经验,供大家参考,并不能完全保证是正确的。数学建模本身就是开放性问题,这里知识抛砖引玉。
1: 问题描述与要求
《纽约时报》要求您对本文件中的结果进行分析,以回答几个问题。
问题1:报告结果的数量每天都在变化。开发一个模型来解释这种变化,并使用您的模型为2023年3月1日报告的结果数量创建一个预测区间。这个词的任何属性是否会影响报告的在困难模式下播放的分数的百分比?如果是这样,如何?如果不是,为什么不呢?
问题2:对于未来日期的给定未来解决方案词,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期 (1, 2, 3, 4, 5, 6, X) 的相关百分比。哪些不确定性与您的模型和预测相关?举一个你对2023年3月1日EERIE这个词的预测的具体例子。你对你的模型的预测有多自信?
问题3:开发并总结一个模型来按难度对解决方案单词进行分类。识别与每个分类关联的给定词的属性。使用您的模型,EERIE这个词有多难?讨论分类模型的准确性。
问题4:列出并描述这个数据集的其他一些有趣的特征。
2: 解题思路和分析结果(详解版)
针对问题1
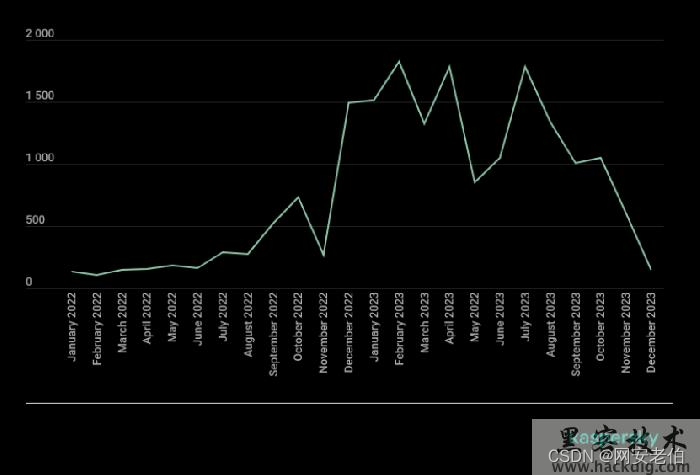
思路:该问题主要是预测一个序列的变化趋势,而且该数据的变化趋势是统计的每天的数据,所以可认为是一个时间序列。数据的波动如下:

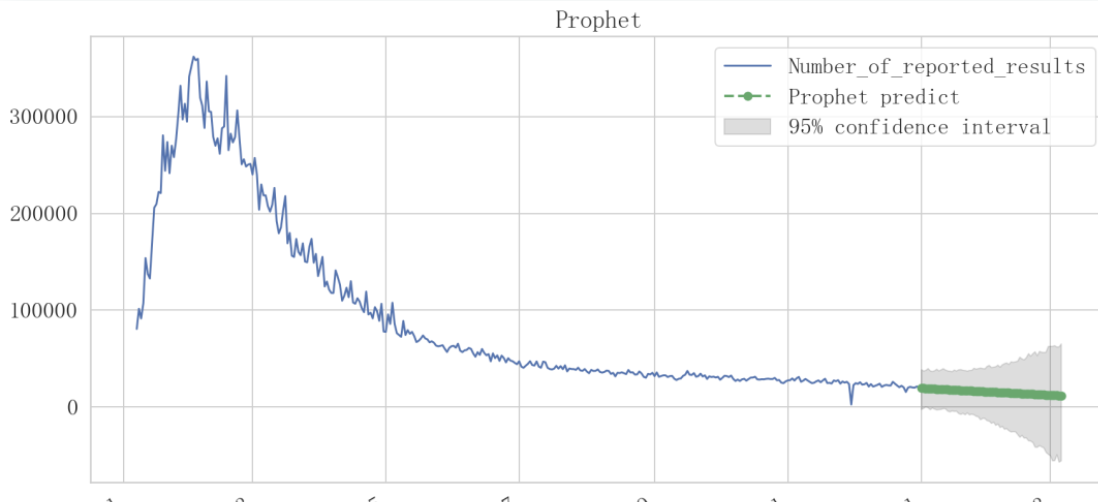

针对问题2
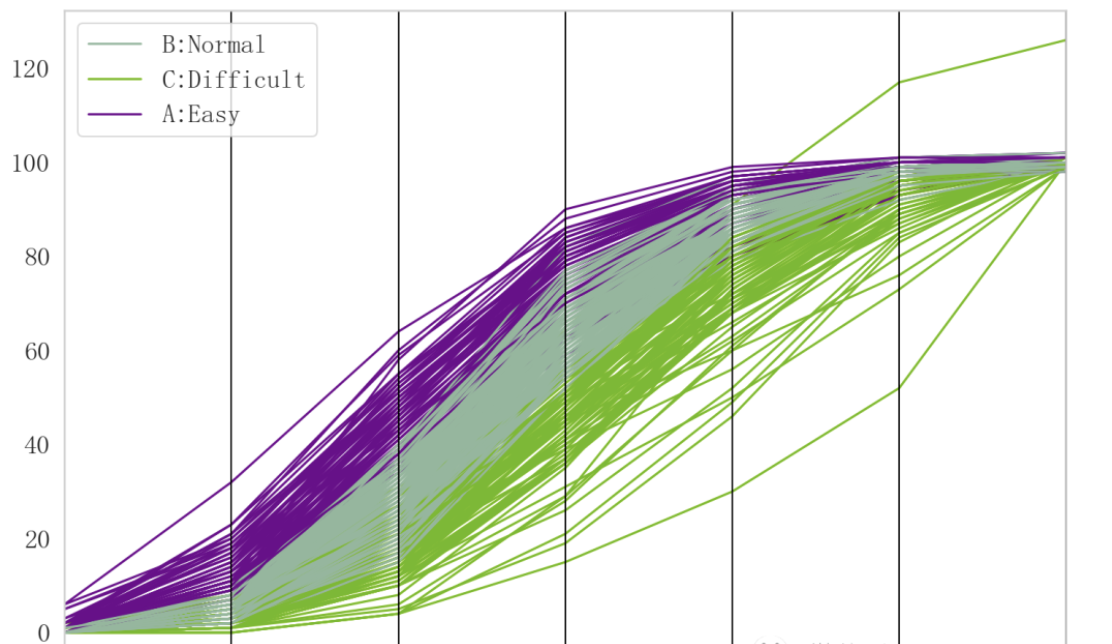
针对问题3

针对问题4
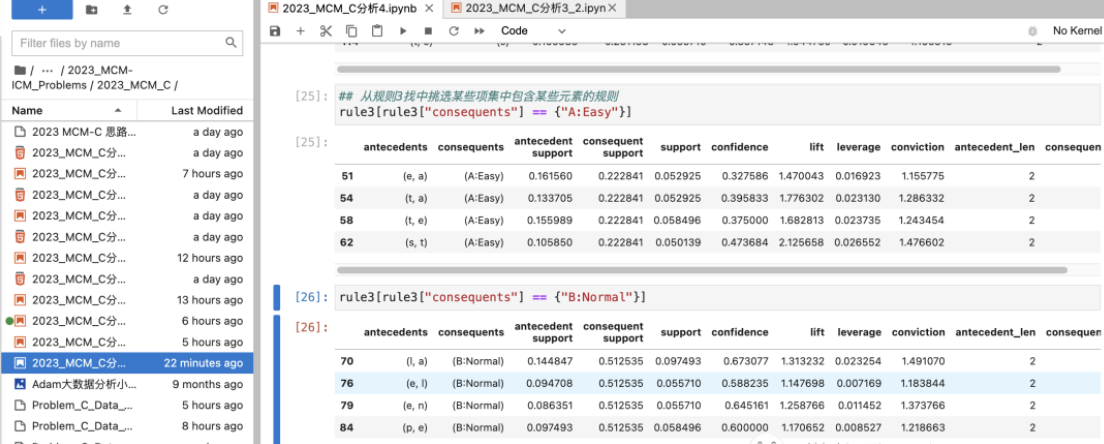
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。