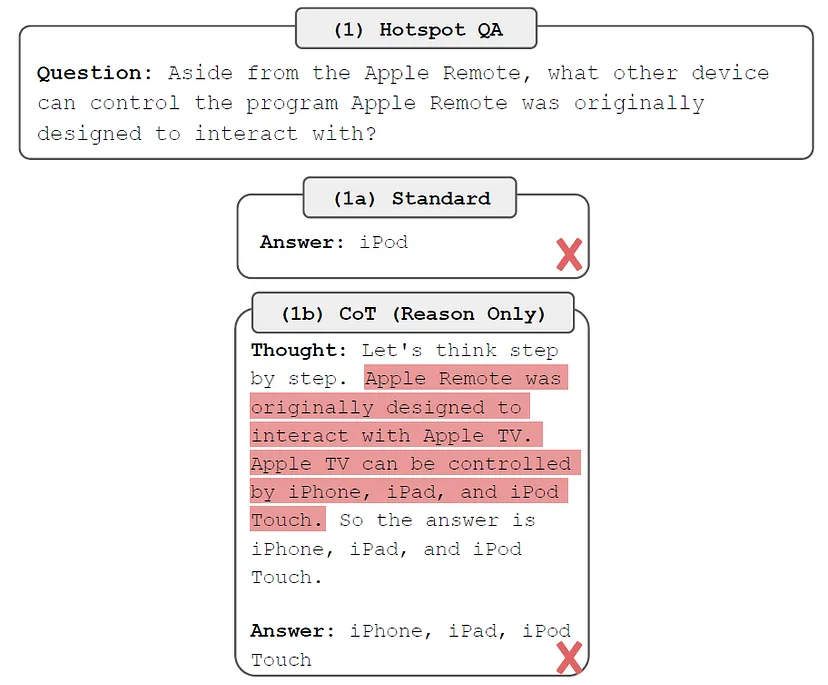
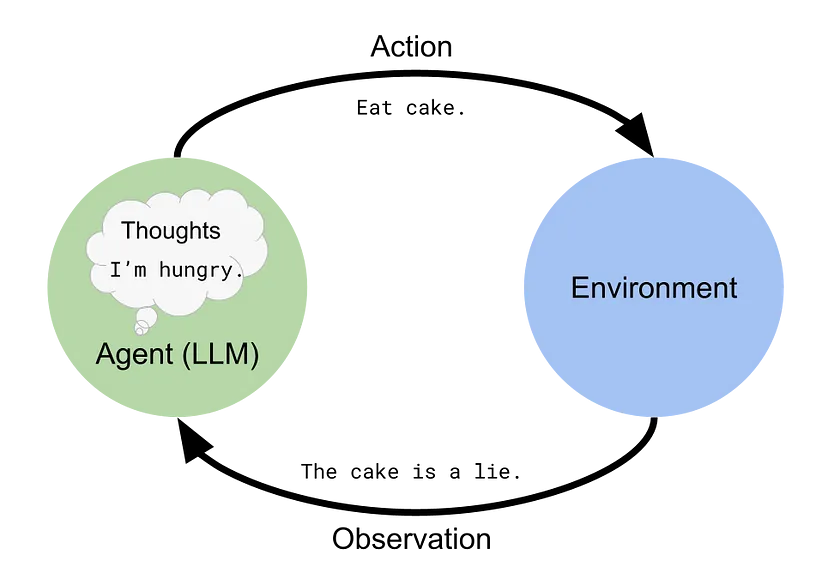
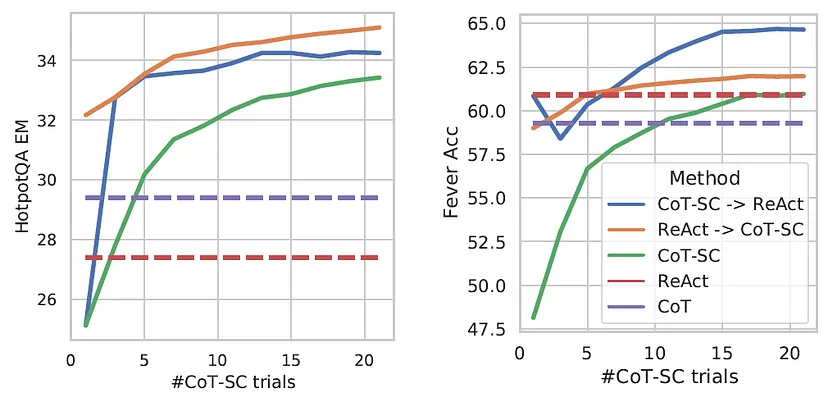
普林斯顿大学的教授和谷歌的研究人员最近发表了一篇论文,描述了一种新颖的提示工程方法,该方法使大型语言模型(例如 ChatGPT)能够在模拟环境中智能地推理和行动。 这种 ReAct 方法模仿了人类在现实世界中的运作方式,即我们通过口头推理并采取行动来获取信息。 人们发现,与各个领域的其他提示工程(和模仿学习)方法相比,ReAct 表现良好。 这标志着朝着通用人工智能(AGI)和具体语言模型(像人类一样思考的机器人)迈出了重要一步。
1、背景
在本节中,我将讨论大型语言模型、提示工程和思维链推理。
1.1 大型语言模型
大型语言模型 (LLM) 是一种机器学习 Transformer 模型,已在巨大的语料库或文本数据集(例如互联网上的大多数网页)上进行训练。 在训练过程中,需要大量时间(和/或 GPU)、能源和水(用于冷却),采用梯度下降来优化模型参数,使其能够很好地预测训练数据。
本质上,LLM学习在给定一系列先前单词的情况下预测最可能的下一个单词。 这可用于执行推理(查找模型生成某些文本的可能性)或文本生成,ChatGPT 等LLM用它来与人交谈。 一旦 LLM 完成训练,它就会被冻结,这意味着它的参数被保存,并且不会向其训练数据添加输入或重新训练 – 这样做是不可行的,正如我们从 Microsoft 的 Tay 聊天机器人成为纳粹分子中了解到的那样 ,无论如何,最好不要向用户学习。
值得注意的是,LLM仍然从他们的训练数据中学习到偏见,而 ChatGPT 背后的 OpenAI 必须添加保护措施——使用来自人类反馈的强化学习 (RLHF)——试图防止模型生成有问题的内容。 此外,由于LLM默认情况下只是根据他们所看到的内容生成最有可能的下一个单词,而不进行任何类型的事实检查或推理,因此他们很容易产生幻觉,或编造事实和推理错误(例如在做时) 简单的数学)。