本文介绍: 展示器、谦卑对象模式在软件架构边界设计中起到重要作用,通过划分系统行为提升可测试性。服务内部组件边界才是架构关键,而非服务本身。遵循依赖关系规则解决横跨型变更问题。
6 软件架构
6.9 展示器和谦卑对象
在《架构整洁之道-软件架构-策略与层次、业务逻辑、尖叫的软件架构、整洁架构》有我们提到了展示器(presenter),展示器实际上是采用谦卑对象(humble object)模式的一种形式,这种设计模式可以很好的帮助识别和保护系统架构的边界。
谦卑对象模式最初的设计目的是帮助单元测试的编写者区分容易测试的行为与难以测试的行为,并将它们隔离。其设计思路非常简单,就是将这两类行为拆分成两组模块或类。其中一组模块被称为谦卑(Humble)组,包含了系统中所有难以测试的行为,而这些行为已经被简化到不能再简化了。另一组模块则包含了所有不属于谦卑对象的行为。
例如,GUI通常是很难进行测试的,因为让计算机自行检视屏幕内容,并检查指定元素是否出现是非常困难的,然后,GUI中的大部分行为实际上是很容易被测试的。这时候,我们可以利用谦卑对象模式将GUI的这两种行为拆分成展示器与视图两部分。
视图部分属于难以测试的谦卑对象,这种对象的代码通常应该越简单越好,它只应负责将数据填充到GUI上,而不应该对数据进行任何变更。应用程序所能控制的、要在屏幕上显示的一切东西,都应该在视图模型中以字符串、布尔值或枚举值的形式存在,视图部分除了加载视图模型所需要的值,不应该再做任何其他的事情。因此,视图是谦卑对象。
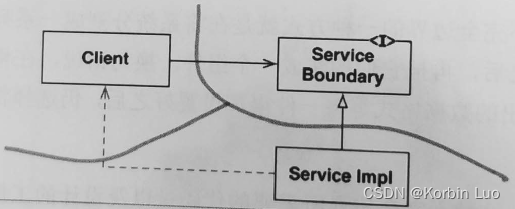
展示器则是可测试的对象,展示器的工作是负责从应用程序中接收数据,然后按视图的需要将这些数据格式化,以便视图将其呈现在屏幕上。
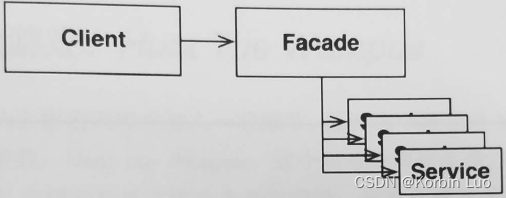
众所周知,强大的可测试性是一个架构的设计是否优秀的显著衡量标准之一。 谦卑对象模式就是这方面的一个非常好的例子。我们将系统分割成可测试和不可测试两部分的过程也就定义了系统的架构边界。展示器与视图之间的边界只是多种架构边界的一种,另外还有许多其他边界:
6.10 不完全边界
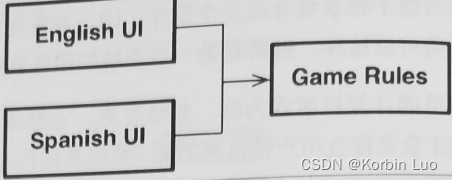
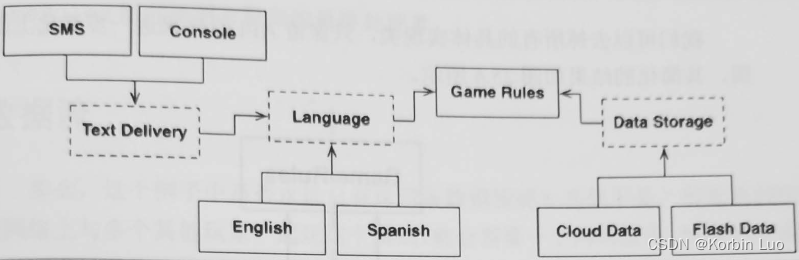
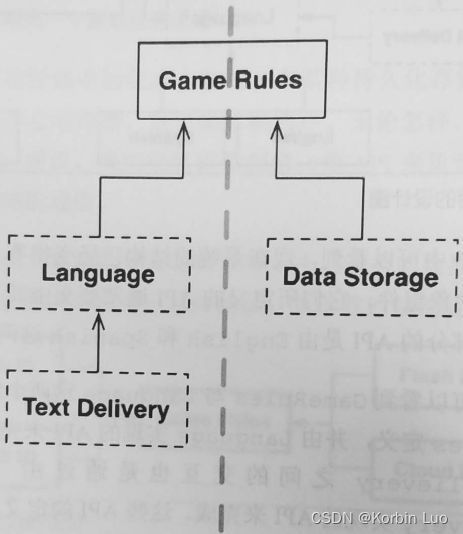
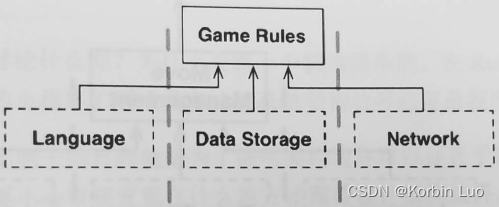
6.11 层次与边界

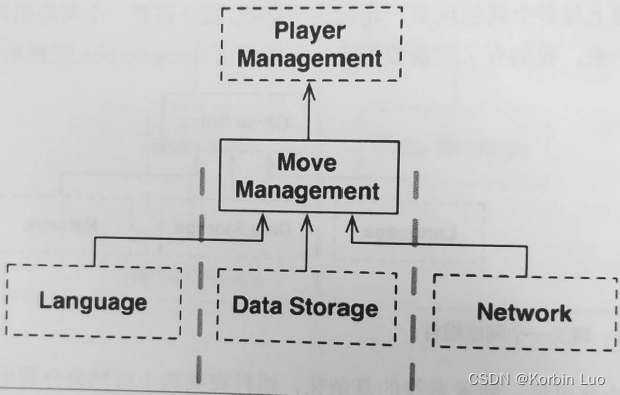
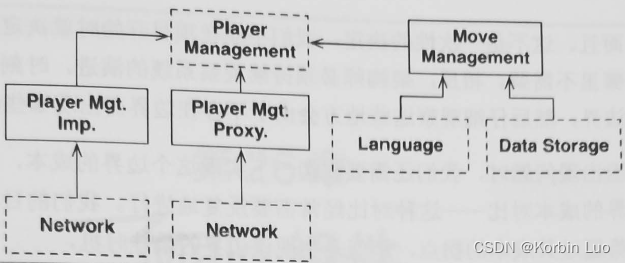
6.12 Main组件
6.13 服务:宏观与微观
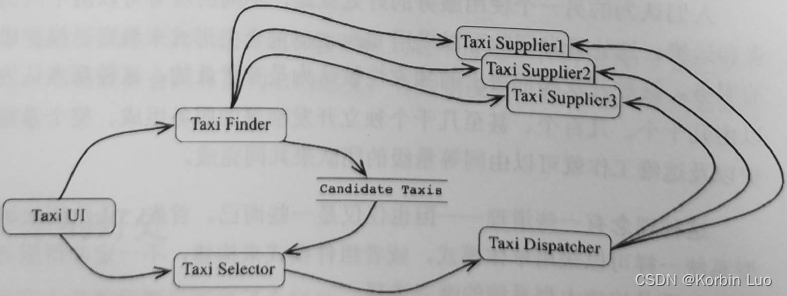
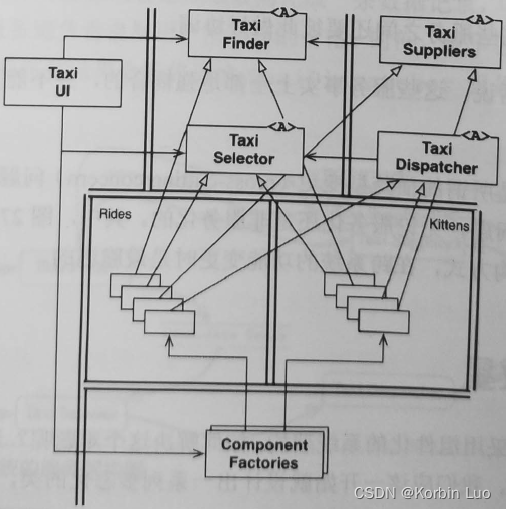
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。