摘要
预测是一项常见的数据科学任务,能够帮助组织进行容量规划、目标设定和异常检测。尽管其重要性不言而喻,但在生产可靠且高质量的预测时面临着严峻挑战,特别是当涉及到多样的时间序列且具有时间序列建模专业知识的分析师相对稀缺时。为了解决这些挑战,我们描述了一种实用的、可扩展的预测方法,将可配置的模型与分析师参与的性能分析相结合。我们提出了一个模块化回归模型,具有可解释的参数,可以由对时间序列具有领域知识的分析师直观地调整。我们描述了性能分析来比较和评估预测过程,并自动标记需要人工审查和调整的预测。帮助分析师最有效地利用其专业知识的工具能够可靠地、实践地预测业务时间序列。
1、介绍
预测是数据科学中的一项核心任务,对组织内的许多活动都至关重要。例如,各行业的组织必须进行容量规划,以有效地分配有限资源,并进行目标设定,以衡量相对基准的绩效。然而,对于机器和大多数分析师来说,生成高质量的预测并不容易。我们观察到在创建业务预测的实践中存在两个主要问题。首先,完全自动化的预测技术往往难以调整,并且往往过于僵化,无法纳入有用的假设或启发式方法。其次,负责组织内数据科学任务的分析师通常对所支持的特定产品或服务具有深入的领域专业知识,但往往没有时间序列预测的培训。因此,能够产生高质量预测的分析师非常罕见,因为预测是一项需要丰富经验的专业技能。
结果是,对高质量预测的需求往往远远超过了它们的生产速度。这一观察结果是我们进行研究的动机,我们打算为在不同规模下产生预测提供一些有用的指导。
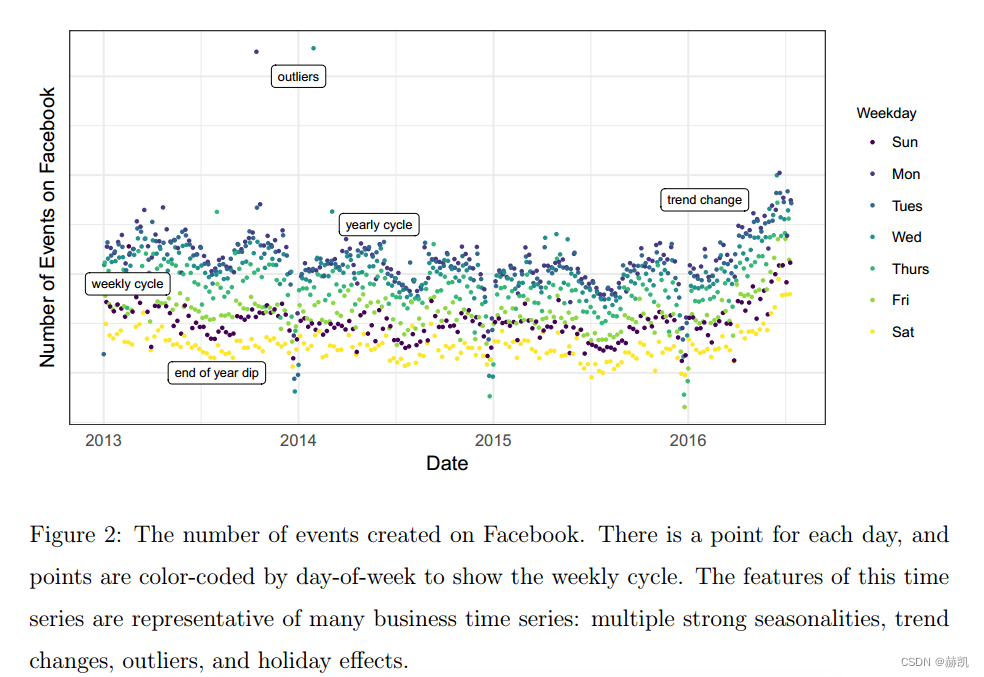
我们首先考虑的两种规模是:1)适用于大量进行预测的人员,可能没有时间序列方法的培训;2)适用于各种可能具有特殊特征的预测问题。在第3节中,我们提出了一个时间序列模型,它足够灵活,适用于各种业务时间序列,同时可以由非专家配置,这些非专家可能对数据生成过程具有领域知识,但对时间序列模型和方法了解有限。
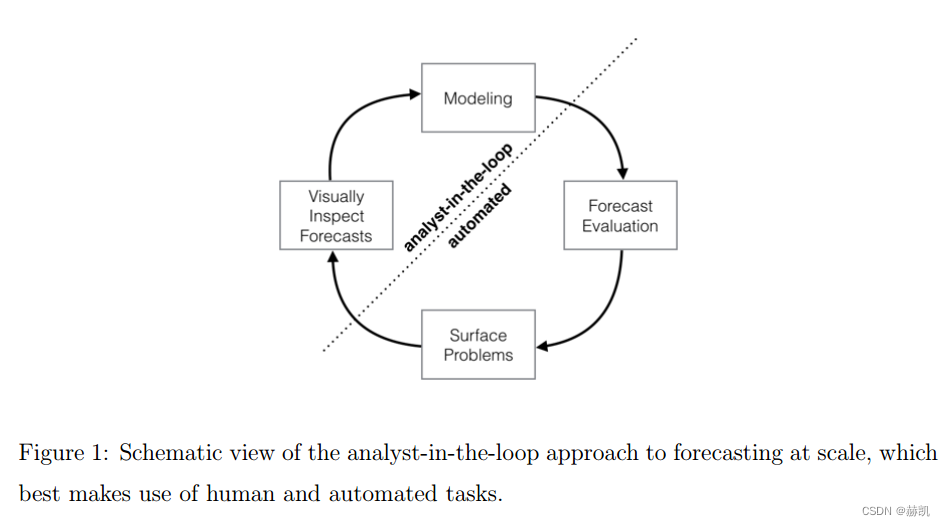
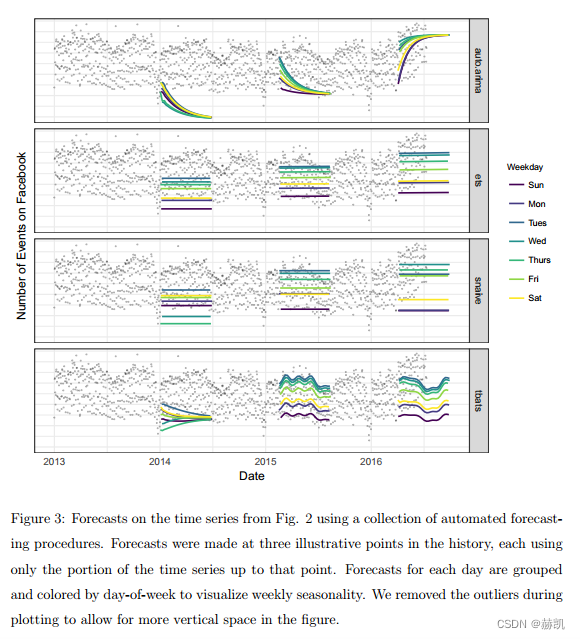
我们所讨论的第三种规模是在大多数实际情况下,将会创建大量的预测,因此需要高效自动的方式来评估和比较它们,并在性能较差时及时发现。当进行数百甚至数千个预测时,让机器来进行模型评估和比较的工作变得非常重要,同时还要有效地利用人类反馈来解决性能问题。在第4节中,我们描述了一个预测评估系统,该系统利用模拟的历史预测来估计样本外性能,并识别存在问题的预测,供人类分析人员了解出了什么问题并进行必要的模型调整。