Impala和Hive的关系
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
与Hive的关系
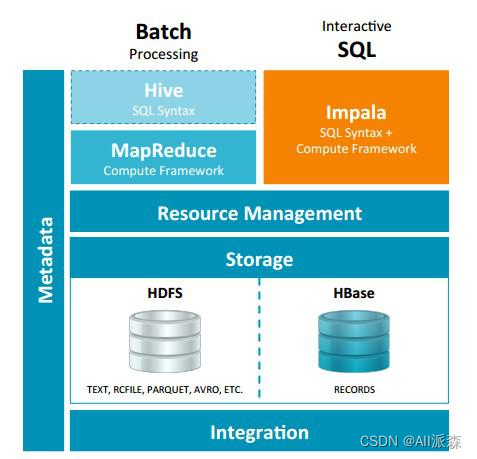
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数 据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
Impala相对于Hive所使用的优化技术
1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
3、充分利用可用的硬件指令(SSE4.2)。
4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
Impala与Hive的异同
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:两者使用相同的元数据。
SQL解释处理:比较相似都是通过词法分析生成执行计划。