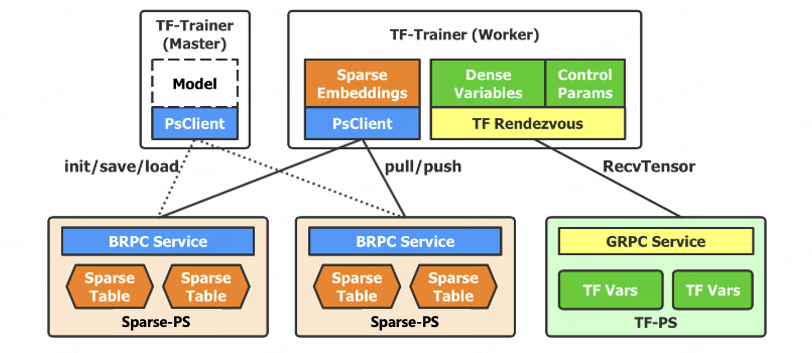
本文介绍: 本文主要使用的是方案(2),基于RND来计算给定状态对于一个skill的novelty为多少(方案(2)相对方案(1)更容易实现,因为在之前的NovelD方法中,就有使用过RND来计算novelty)。ReST不是并行地训练所有的技能,而是以一种循环的方式一个接一个地训练技能,并附带一个内在的奖励,以阻止覆盖其他技能的频繁访问状态。以往的无监督技能发现方法主要使用的是并行训练,文章作者发现,当不同技能访问的状态重叠时,并行训练过程有时会阻碍探索,这导致状态覆盖率低,限制了学习技能的多样性。
4、实验
5、结论
这篇文章主要基于recurrent+RND的方法解决了以往基于mutual information的技能发现方法中的探索退化问题。通过为每个skill分配一对RND网络,来计算给定的状态对于一个skill的新颖度。
作者提出ReST还有一些局限性:(1)样本训练效率更差,因为每个epoch只能训练一个skill。(2)intrinsic reward需要基于其他所有skill的RND网络的预测误差,这导致计算复杂度很高(这就限制了N的大小,并且本文方法好像无法动态扩展N的大小)。(3)ReST方法无法扩展到continuous latent上。
6、伪代码

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。