诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:How Context Affects Language Models’ Factual Predictions
ArXiv网址:https://arxiv.org/abs/2005.04611
2020年AKBC论文,作者来自脸书和UCL。
本文主要关注zero-shot cloze-style question answering任务,使用LM+无监督检索,考察需要检索出什么样的上下文。
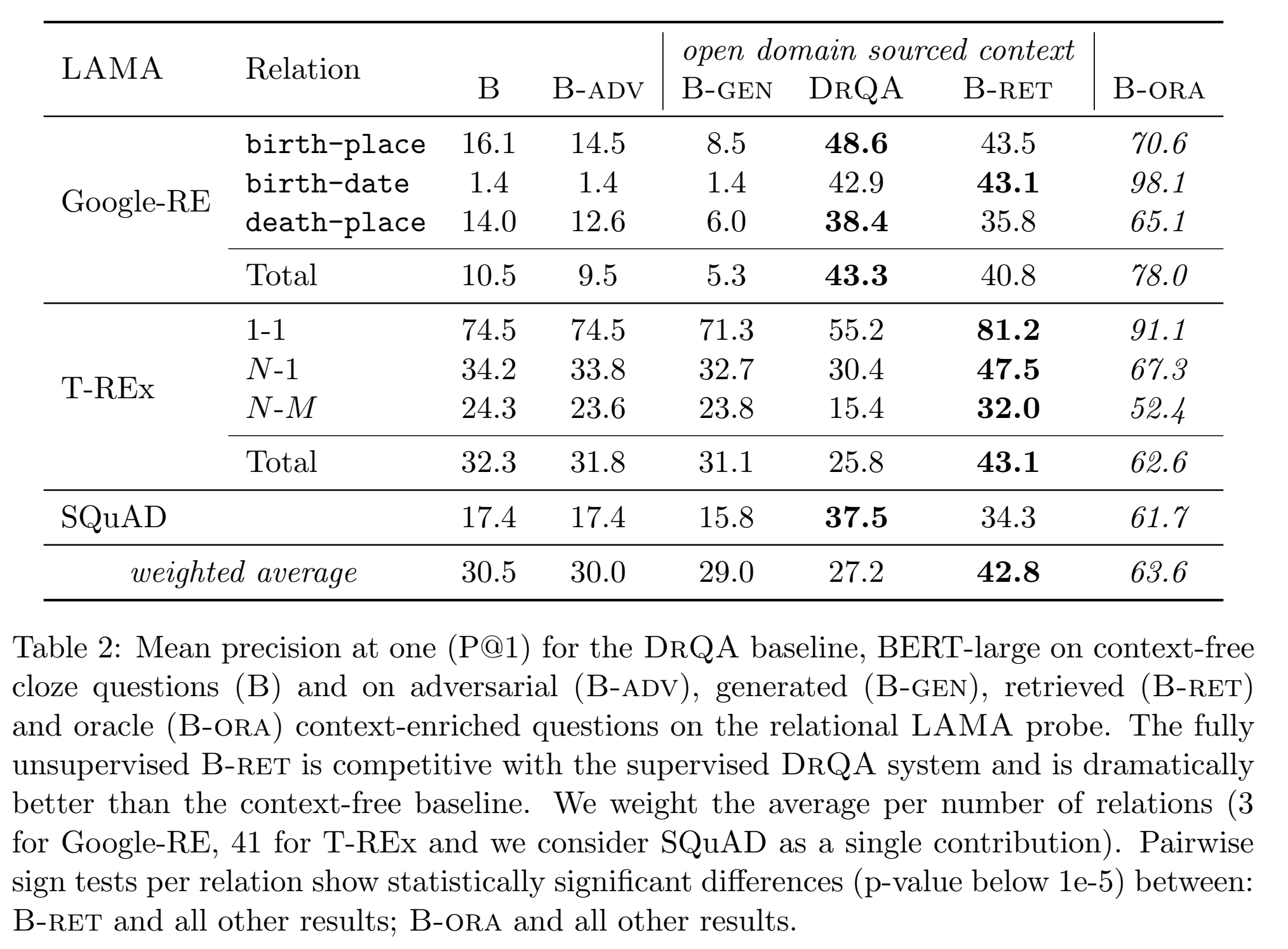
用DrQA检索器(TF-IDF检索维基百科)检索的结果,LM在QA上的指标就能和无监督场景相媲美。
1. 数据集
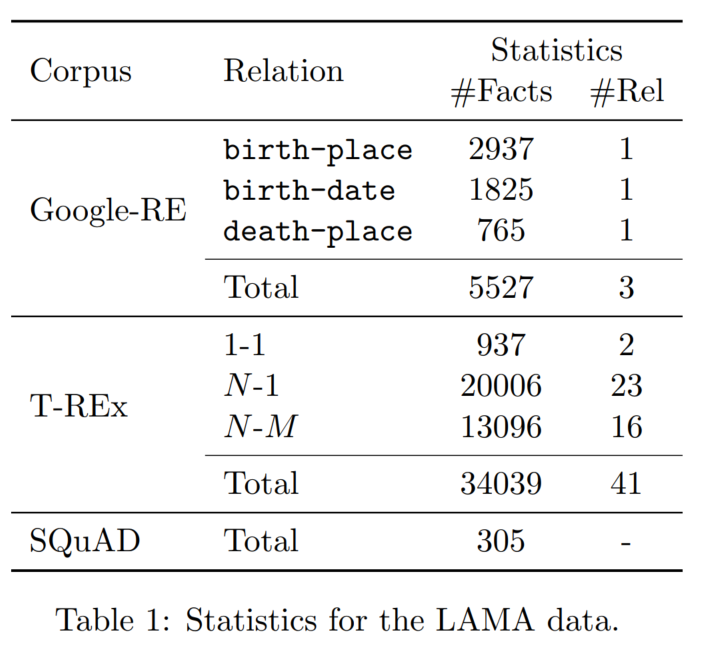
2. LM
3. baseline
4. 上下文设置
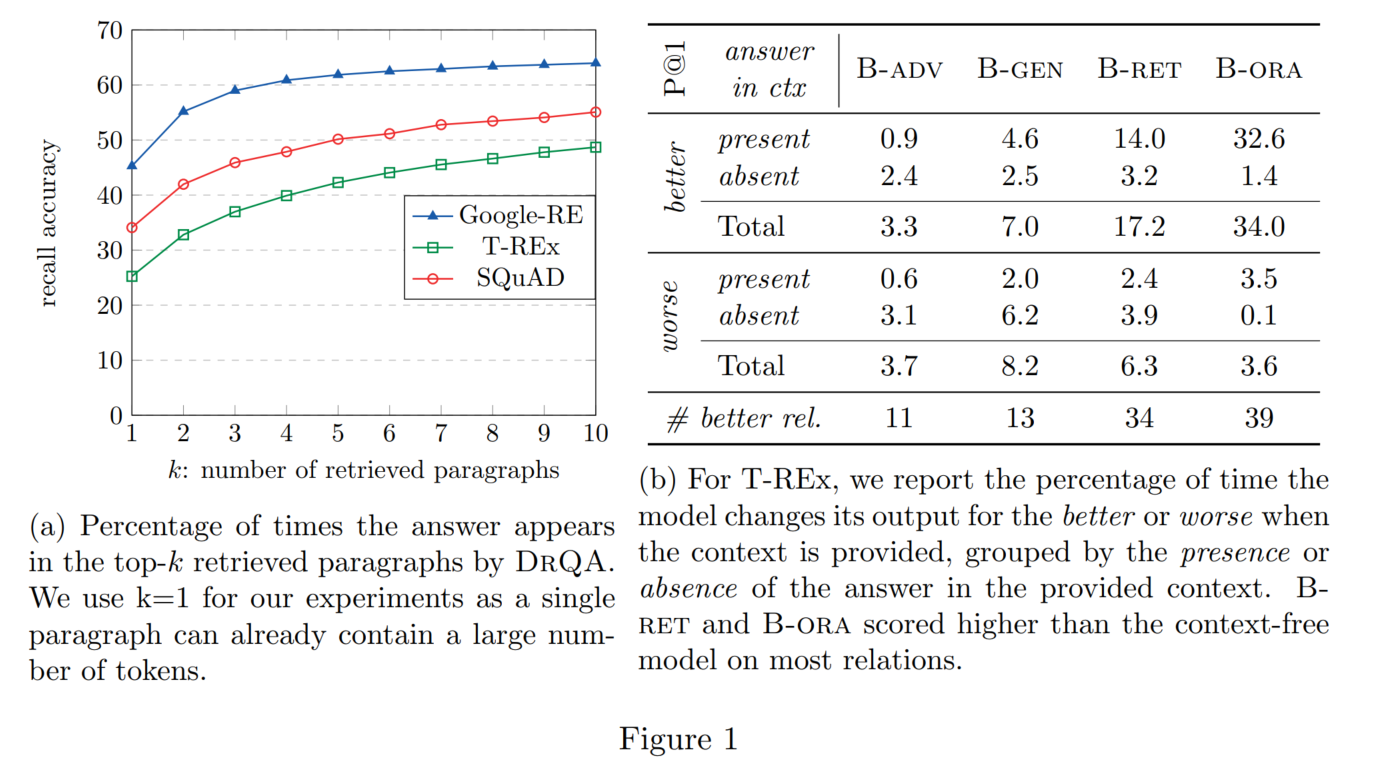
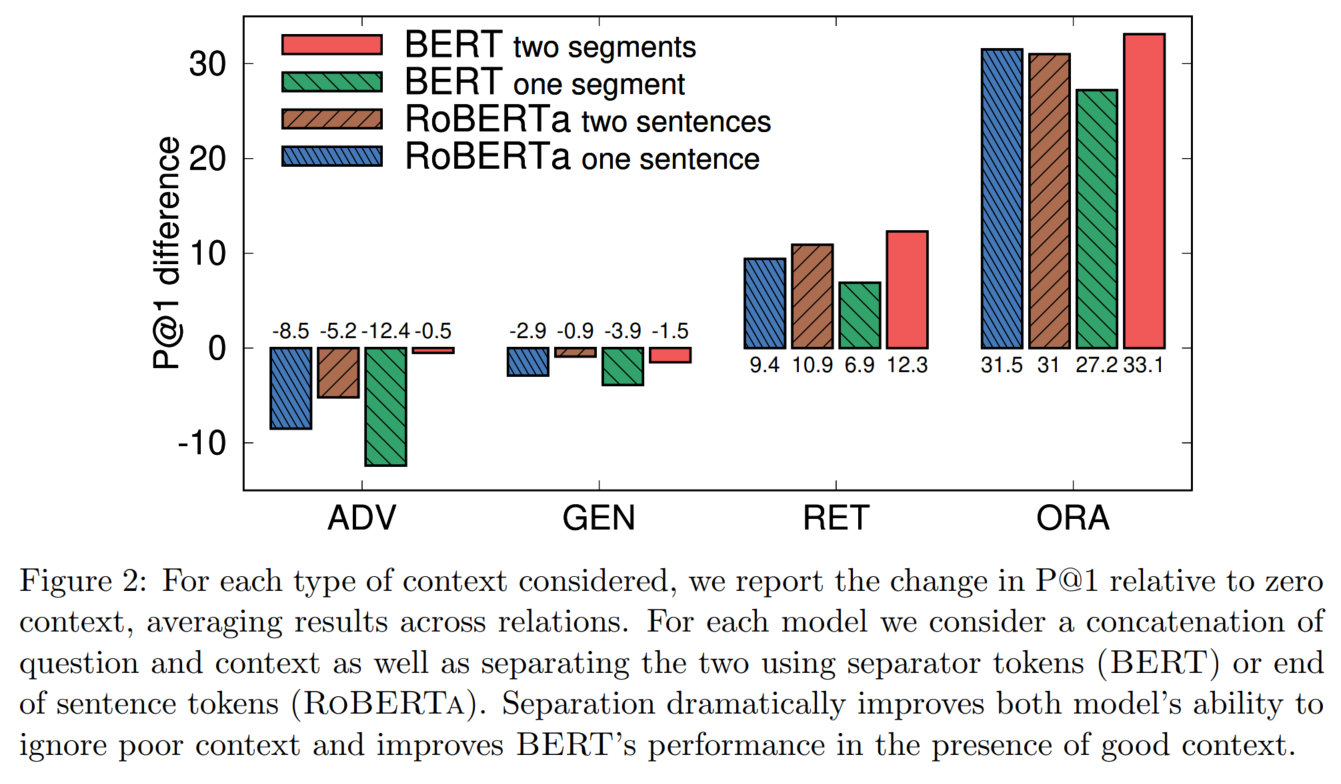
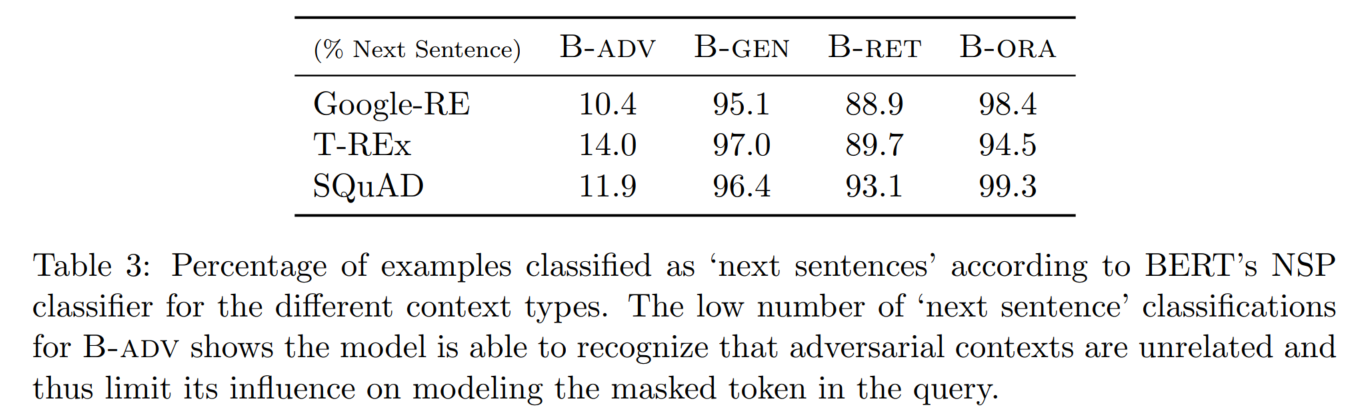
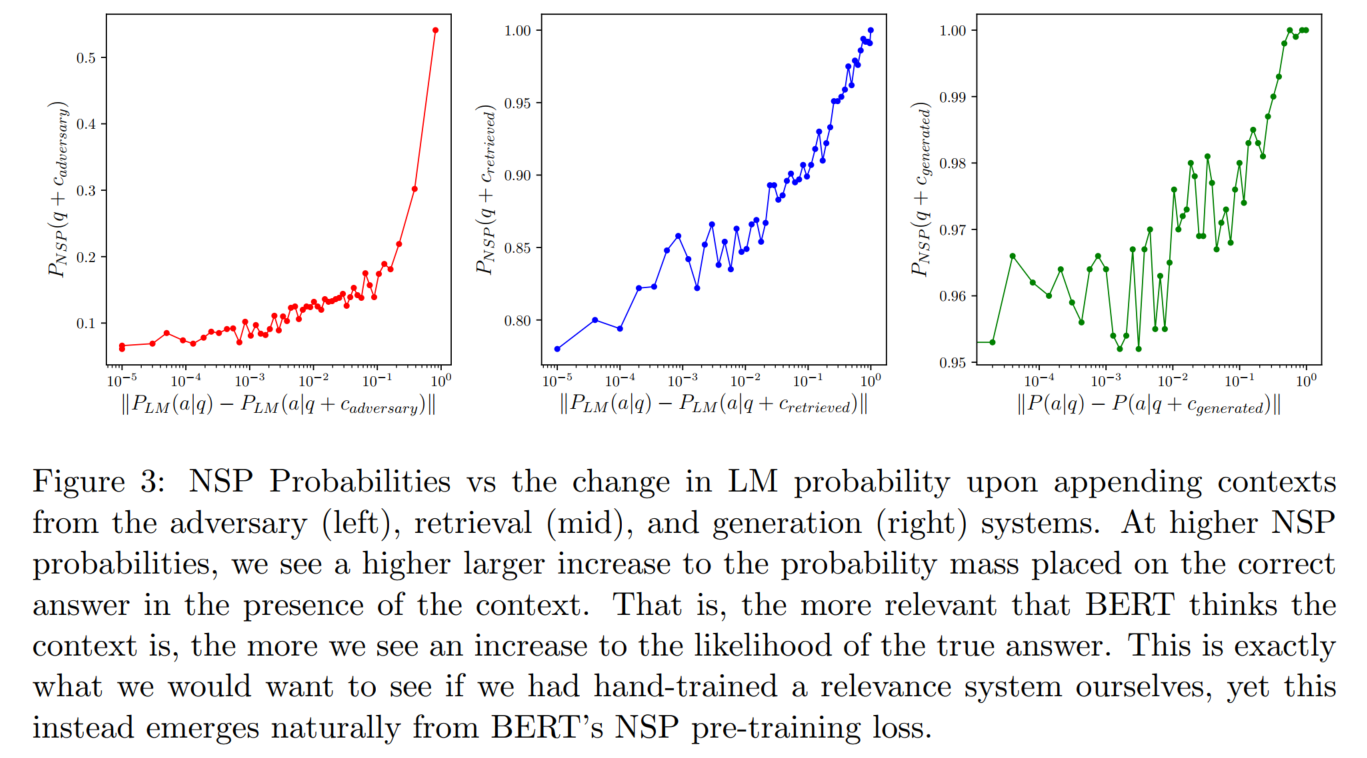
5. 主实验结果

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





