本文介绍: 在这个掩码中,对角线以下和对角线上的元素被设置为负无穷和零,以确保在自注意力机制中,模型只能关注当前位置之前的信息。是一个上三角矩阵,其中对角线及其以下的元素为负无穷,而对角线以上的元素为0。这样的矩阵在自注意力机制中被用作掩码,确保模型在生成每个位置时只关注之前的位置,而不会使用未来的信息。这样,在计算注意力权重时,这些位置的值经过 softmax 函数后将保持为。通常用于在自注意力机制中,确保模型在生成序列时只能注意到当前位置之前的信息,而。的上三角矩阵,其中上三角的元素为1,下三角的元素为0。
“no–peek“掩码通常用于在自注意力机制中,确保模型在生成序列时只能注意到当前位置之前的信息,而不能“窥视”未来的信息。
最终,mask 是一个上三角矩阵,其中对角线及其以下的元素为负无穷,而对角线以上的元素为0。这样的矩阵在自注意力机制中被用作掩码,确保模型在生成每个位置时只关注之前的位置,而不会使用未来的信息。
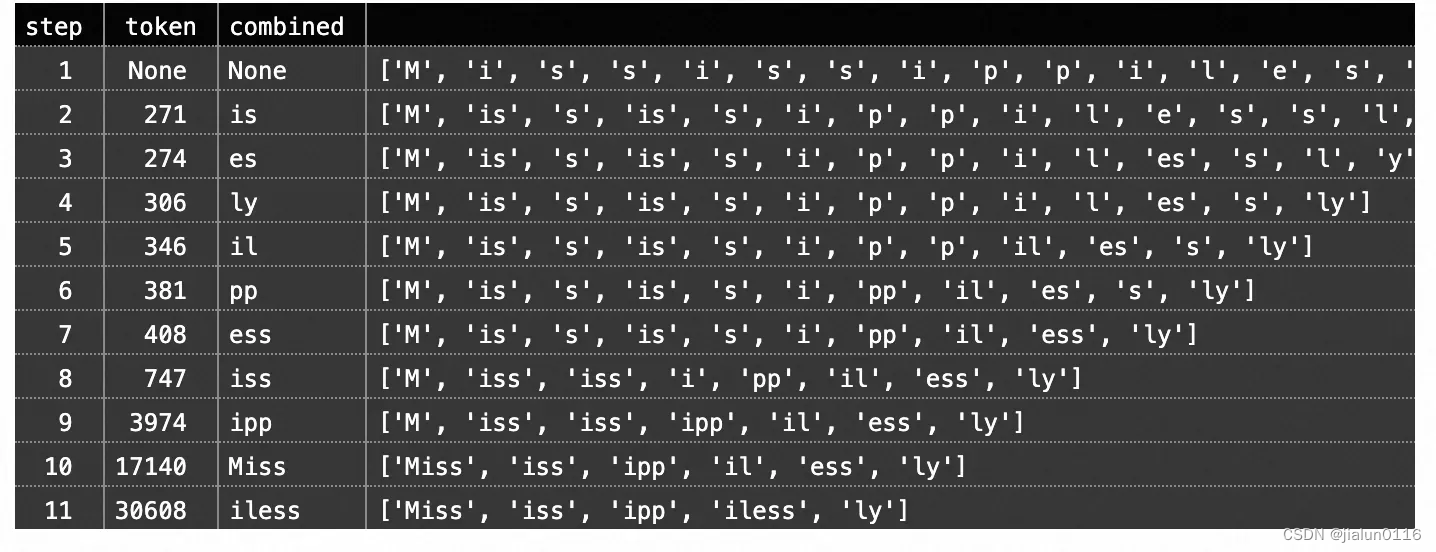
让我们使用一个具体的长度来演示 gen_nopeek_mask 函数,比如 length = 4。以下是运行这个函数的示例:
这个矩阵是一个示例的 “no–peek” 掩码。在这个掩码中,对角线以下和对角线上的元素被设置为负无穷和零,以确保在自注意力机制中,模型只能关注当前位置之前的信息。这种掩码通常在 Transformer 模型中的解码器中使用。
将矩阵中值为0的位置用负无穷(-∞)填充。这样,在计算注意力权重时,这些位置的值经过 softmax 函数后将趋近于0,表示模型在这些位置不应该关注。
将矩阵中值为1的位置用0填充。这样,在计算注意力权重时,这些位置的值经过 softmax 函数后将保持为1,表示模型在这些位置应该关注。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。