本文介绍: 本文详细介绍了C语言中结构体字节对齐的规则,并根据该规则拓展了一些CPU读取系统内存的一些知识,联系到实际开发中,鼓励读者对提高自己编程能力的思考
C语言结构体的字节对齐
什么是字节对齐
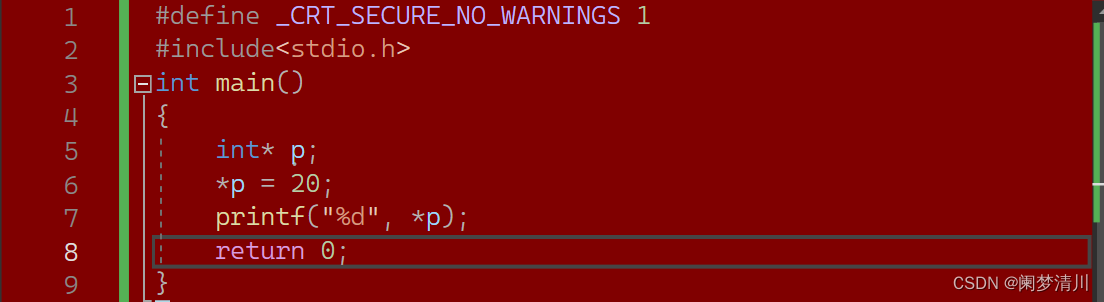
首先来看下面的程序:
如图:

明明结构体中的成员类型数量都是一样的,为什么会出现存储他们的结构体大小不一样的情况呢?
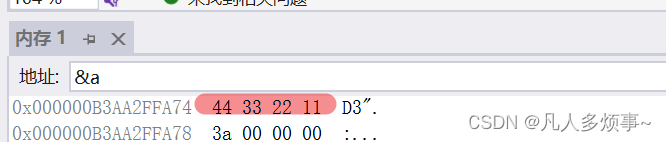
原因是这样的,下面是这两个结构体在内存中的存储结构:
n1:
n2:
ps:在上面的表格中,“-”表示被使用,“/”表示被空置或者跳过
为什么要字节对齐
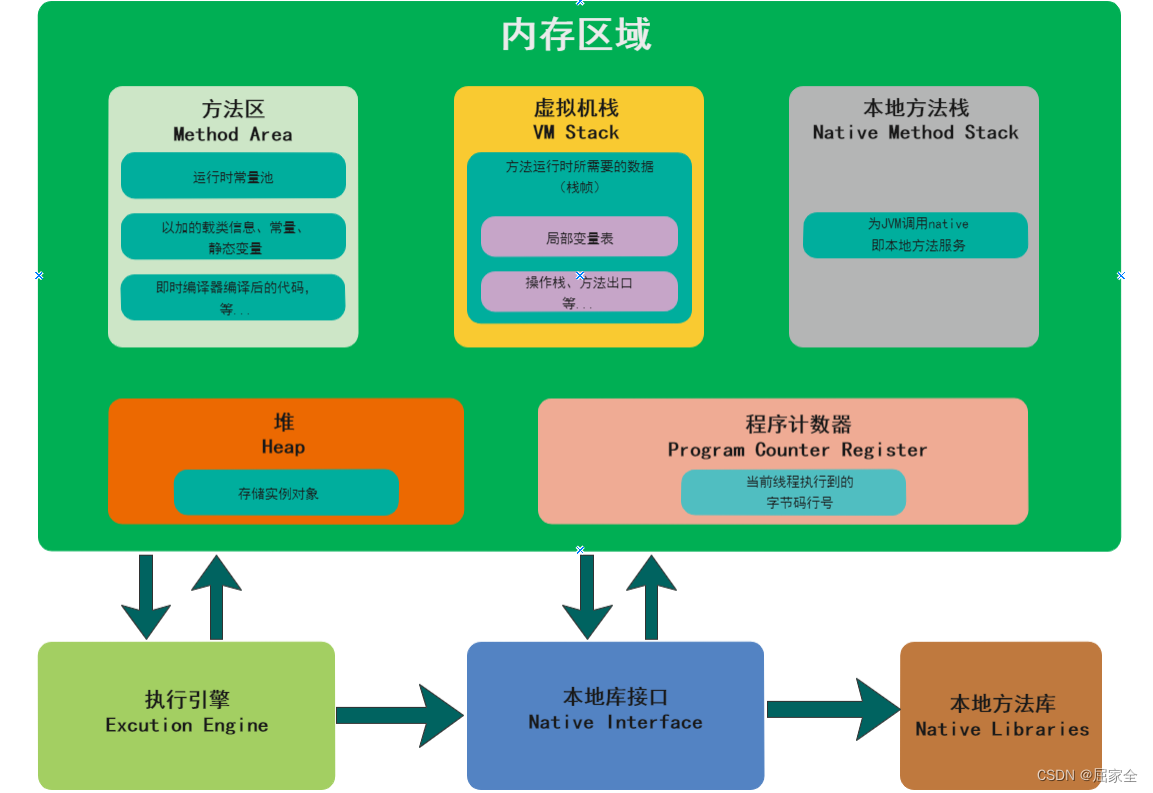
操作系统位数与信息处理
CPU读取数据的格式
如何用利用系统字节对齐的特性提高自己的编程水平?
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。