本文介绍: 在本文中,作者通过利用静态摄像机记录的视频序列中可用的时间上下文,解决了实时监控应用中微小物体检测的问题。作者**提出了一个基于YOLOv5的时空深度学习模型**,该模型通过一次处理帧序列来利用时间上下文。此外,提出了一种使用帧差作为显式运动信息的双流架构,进一步提高了对大小为4 × 4像素的运动物体的检测

Abstract
在监视应用中,微小、低分辨率物体的检测仍然是一项具有挑战性的任务。大多数深度学习目标检测方法依赖于从静止图像中提取的外观特征,难以准确检测微小物体。
在本文中,作者通过利用静态摄像机记录的视频序列中可用的时间上下文,解决了实时监控应用中微小物体检测的问题。
作者提出了一个基于YOLOv5的时空深度学习模型,该模型通过一次处理帧序列来利用时间上下文。此外,提出了一种使用帧差作为显式运动信息的双流架构,进一步提高了对大小为4 × 4像素的运动物体的检测。
作者的方法在准确性和推理速度上超过了以前在公共WPAFB WAMI数据集上的工作,也超过了以前在嵌入式NVIDIA Jet- son Nano部署上的工作。作者得出结论,在深度学习目标检测器中添加时间上下文是一种有效的方法,可以大大提高静态视频中微小运动物体的检测。
Introduction
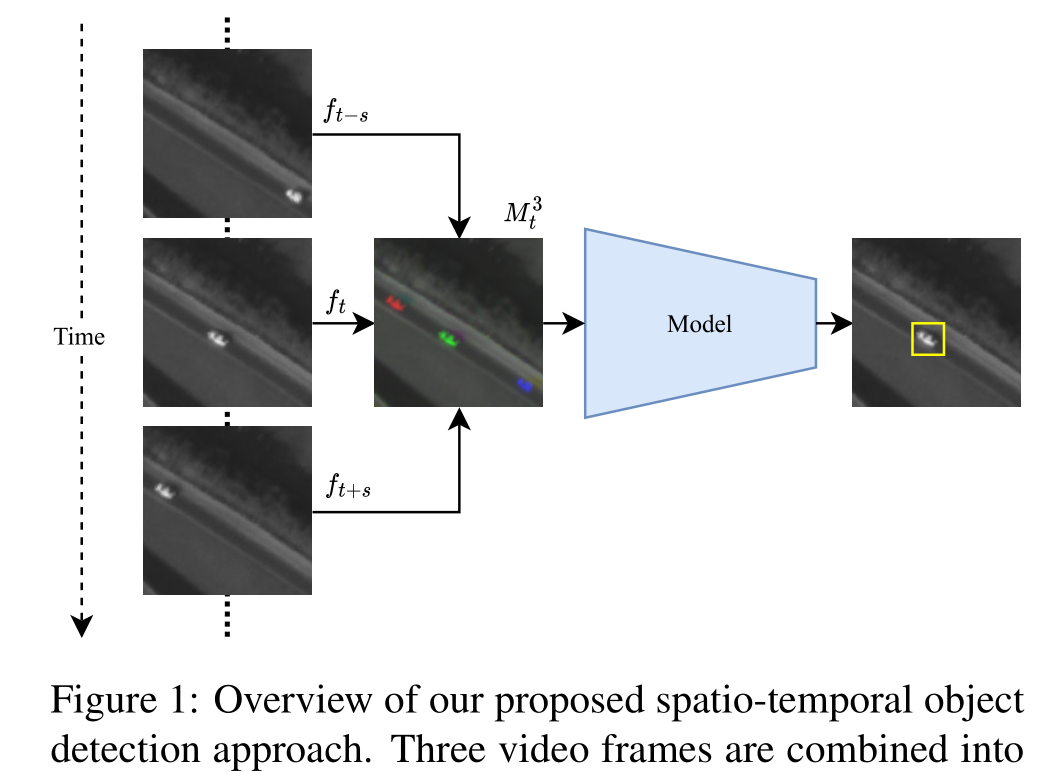
Contribution
Related Work
Methods
YOLOv5 Overview
T-YOLOv5: Exploit Temporal Context
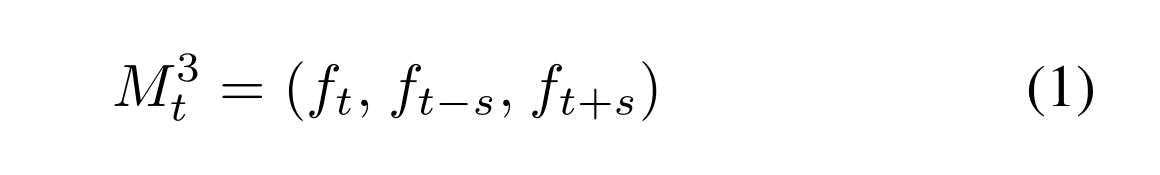
T2-YOLOv5: Two-Stream Approach
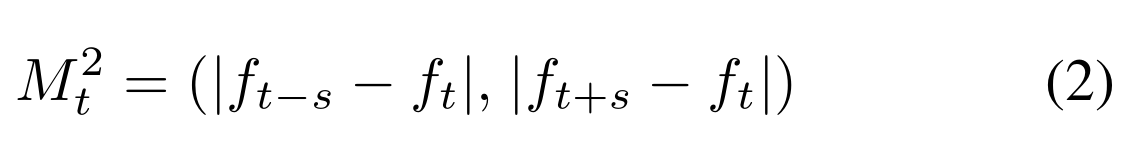

Conclusion
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




![[C#]winform部署yolov7+CRNN实现车牌颜色识别车牌号检测识别](https://img-blog.csdnimg.cn/direct/c12aefab36e342e7a127f6e953ac3905.jpeg)
