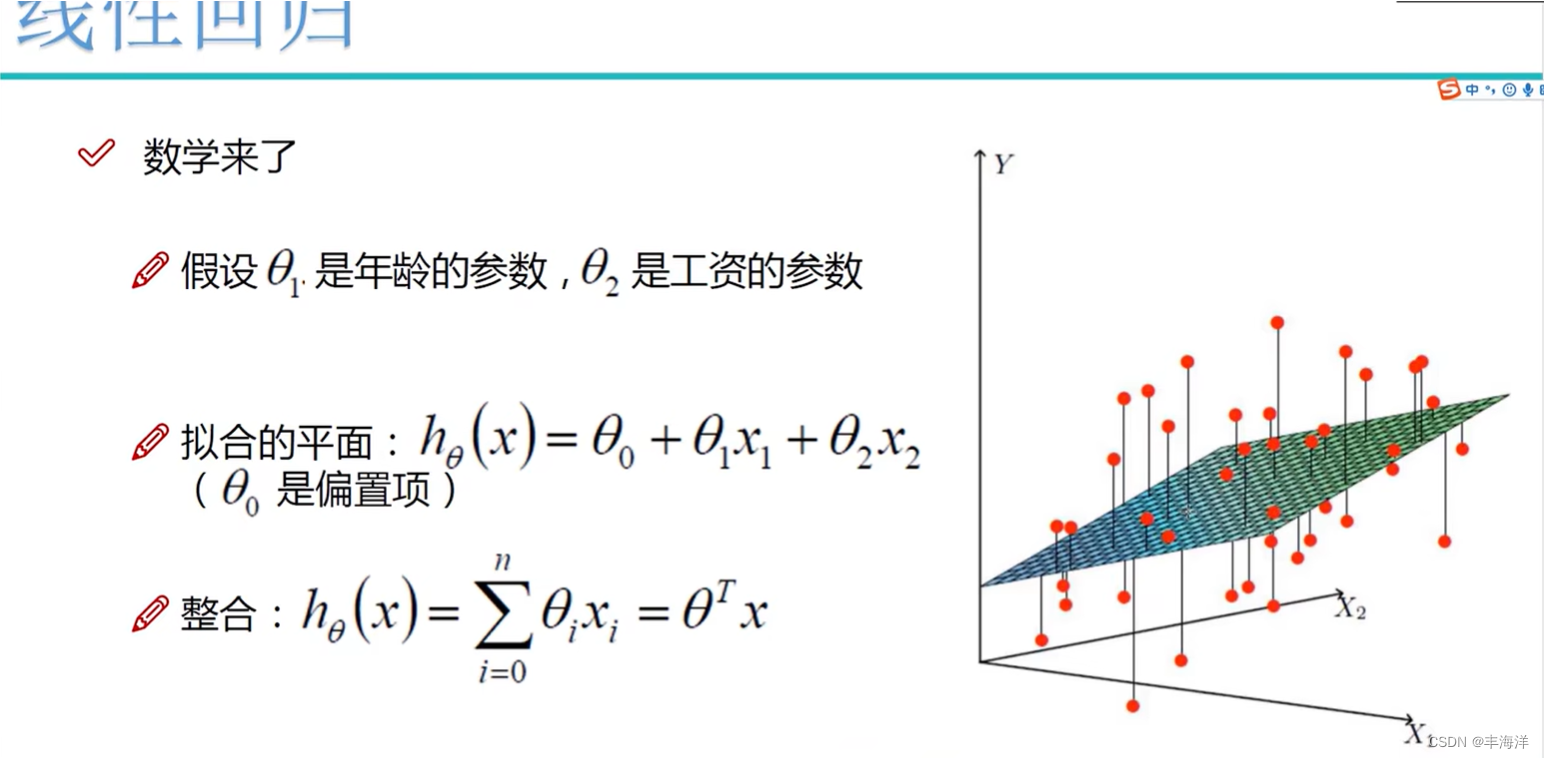
表示向量
v
=
[
v
1
,
v
2
,
⋯
,
v
p
]
T
v=[v_1,v_2,cdots,v_p]^T
v=[v1,v2,⋯,vp]T的
L
2
L_2
L2范式,
c
>
0
c>0
c>0表示正则化参数。
Eq.1中
∣
∣
x
−
x
0
∣
∣
2
2
||x-x_0||_2^2
∣∣x−x0∣∣22是正则化,用于强制对抗性示例
x
x
x和图像
x
0
x_0
x0在欧几里得距离的相似性;
c
⋅
f
(
x
,
t
)
ccdot f(x,t)
c⋅f(x,t)是反映不成功的对抗性攻击程度的损失函数,
t
t
t是目标类别。C&W比较了
f
(
x
,
t
)
f(x,t)
f(x,t)的几个候选者,并提出了以下形式进行有效的定向攻击(Eq.2):
f
(
x
,
t
)
=
max
{
max
i
≠
t
[
Z
(
x
)
]
i
−
[
Z
(
x
)
]
t
,
−
κ
}
(2)
f(x,t)=max {max_{ine t} [Z(x)]_i-[Z(x)]_t,-kappa}tag{2}
f(x,t)=max{i=tmax[Z(x)]i−[Z(x)]t,−κ}(2)
其中
Z
(
x
)
∈
R
K
Z(x)∈mathbb{R}^K
Z(x)∈RK是DNN中
x
x
x的logit表示,其中
[
Z
(
x
)
]
k
[Z(x)]_k
[Z(x)]k表示
x
∈
k
x∈k
x∈k的概率,
κ
>
0
kappa>0
κ>0是攻击可转移性的调整参数。
C&W设置
κ
=
0
kappa=0
κ=0来攻击目标DNN,并建议在执行转移攻击时使用较大的
κ
kappa
κ。Eq.2中使用损失函数的基本原理可以通过基于logit层表示的softmax分类规则来解释;DNN
F
(
x
)
F(x)
F(x)的输出(置信度得分)由softmax函数确定(Eq.3):
[
F
(
x
)
]
k
=
exp
(
[
Z
(
x
)
]
k
)
∑
i
=
1
k
exp
(
[
Z
(
x
)
]
i
)
,
∀
k
∈
{
1
,
⋯
,
K
}
(3)
[F(x)]_k=frac{exp([Z(x)]_k)}{sum_{i=1}^k exp([Z(x)]_i)}, forall k∈{1,cdots,K}tag{3}
[F(x)]k=∑i=1kexp([Z(x)]i)exp([Z(x)]k),∀k∈{1,⋯,K}(3)
因此,根据Eq.3中的softmax决策规则,
max
i
≠
t
[
Z
(
x
)
]
i
−
[
Z
(
x
)
]
t
≤
0
max_{ine t} [Z(x)]_i-[Z(x)]_tleq 0
maxi=t[Z(x)]i−[Z(x)]t≤0意味着对抗性示例
x
x
x获得了类别
t
t
t的最高置信度分数,因此针对性攻击成功,否则不成功。
κ
kappa
κ确保了
[
Z
(
x
)
]
t
[Z(x)]_t
[Z(x)]t和
max
i
≠
t
[
Z
(
x
)
]
i
max_{ine t} [Z(x)]_i
maxi=t[Z(x)]i之间的恒定差距,这解释了为什么设置大的
κ
kappa
κ在转移攻击中是有效的。
最后,框约束
x
∈
[
0
,
1
]
p
x∈[0,1]^p
x∈[0,1]p代表对抗性示例必须从有效的图像空间生成。实际上,每个图像都可以通过将每个像素值除以最大可获得像素值(如255)来满足此框架约束。C&W采用
1
+
tanh
w
2
frac{1+tanh w}{2}
21+tanhw代替
x
x
x来消除框约束,其中
w
∈
R
p
w∈mathbb{R}^p
w∈Rp。通过使用这种变量变化,Eq.1中的优化问题变成了以
w
w
w作为优化器的无约束最小化问题,并且可以应用DNN的典型优化工具(反向传播)来求解最优
w
w
w并获得对应的对抗性例子
x
x
x。
3.3 Proposed black-box attack via zeroth order stochastic coordinate descent
Eq.1-2的攻击公式是以白盒为基础的,因为logit层是DNN内部的状态信息,求解Eq.1也需要DNN的反向传播。我们通过提出以下方法来修改对黑盒设置的攻击:
- 修改Eq.1中的损失函数
f
(
x
,
t
)
f(x,t)
f(x,t),使其仅取决于DNN的输出F
F
F和所需的类别标签t
t
t。 - 使用有限差分法(finite difference method)而不是目标DNN上的实际反向传播来计算近似梯度,并通过零阶优化来解决优化问题。
3.3.1 Loss function f(x, t) based on F
受到Eq.2的启发,提出了基于DNN输出F的新的铰链式的损失函数,定义为Eq.4:
f
(
x
,
t
)
=
max
{
max
i
≠
t
log
[
F
(
x
)
]
i
−
log
[
F
(
x
)
]
t
,
−
κ
}
(4)
f(x,t)=max{max_{ine t} log[F(x)]_i-log [F(x)]_t,-kappa}tag{4}
f(x,t)=max{i=tmaxlog[F(x)]i−log[F(x)]t,−κ}(4)
其中
κ
≥
0
kappageq 0
κ≥0,
log
0
log 0
log0定义为
−
∞
-infty
−∞。
log
(
⋅
)
log(cdot)
log(⋅)是一个单调函数,
max
i
≠
t
log
[
F
(
x
)
]
i
−
log
[
F
(
x
)
]
t
≤
0
max_{ine t} log[F(x)]_i-log [F(x)]_t leq 0
maxi=tlog[F(x)]i−log[F(x)]t≤0意味着
x
x
x获得类别
t
t
t的最高置信度分数。
对数算子对于黑盒攻击至关重要,因为训练好的DNN通常会在其输出
F
(
x
)
F(x)
F(x)上产生倾斜的概率分布,使得一个类的置信度分数显著主导另一类的置信度分数。使用对数运算符可以减少显性效应,同时由于单调性而保留置信度分数的顺序。
和Eq.2相似,Eq.4中
κ
kappa
κ确保了
log
[
F
(
x
)
]
t
log[F(x)]_t
log[F(x)]t和
max
i
≠
t
log
[
F
(
x
)
]
i
max_{ine t} log[F(x)]_i
maxi=tlog[F(x)]i之间的恒定差距。
对于无目标攻击,当
x
x
x被分类为除原始类标签
t
0
t_0
t0之外的任何类时,对抗性攻击就会成功,可以使用类似的损失函数Eq.5:
f
(
x
)
=
max
{
log
[
F
(
x
)
]
t
0
−
max
i
≠
t
0
log
[
F
(
x
)
]
i
,
−
κ
}
(5)
f(x)=max{log[F(x)]_{t_0}-max_{ine t_0}log[F(x)]_i,-kappa}tag{5}
f(x)=max{log[F(x)]t0−i=t0maxlog[F(x)]i,−κ}(5)
其中
t
0
t_0
t0是
x
x
x的原始类别,
max
i
≠
t
0
log
[
F
(
x
)
]
i
max_{ine t_0} log[F(x)]_i
maxi=t0log[F(x)]i代表除了
t
0
t_0
t0以外最可能的预测类别。
3.3.2 ZOO on the loss function
讨论用于攻击的任何通用函数
f
f
f的优化技术(Eq.1中的正则化项可以作为
f
f
f的一部分)。使用对称差商(symmetric difference quotient)估计梯度Eq.6:
g
^
i
:
=
∂
f
(
x
)
∂
x
i
≈
f
(
x
+
h
e
i
)
−
f
(
x
−
h
e
i
)
2
h
(6)
hat{g}_i := frac{partial f(x)}{partial x_i}approx frac{f(x+he_i)-f(x-he_i)}{2h}tag{6}
g^i:=∂xi∂f(x)≈2hf(x+hei)−f(x−hei)(6)
其中
h
h
h是一个很小的常数,实验中均设置为
h
=
0.0001
h=0.0001
h=0.0001,
e
i
e_i
ei为只有第
i
i
i个元素是1,其他均为0的单位向量。估计误差是
O
(
h
2
)
O(h^2)
O(h2)量级的(?),成功进行对抗攻击并不必须要准确估计梯度。实验表明,就算没有准确估计,ZOO依旧有很好的攻击效果。
对于任何
x
∈
R
p
xin mathbb{R}^p
x∈Rp,我们需要评估目标函数
2
p
2p
2p次来估计全部
p
p
p个坐标轴。有趣的是,只对目标函数做一次变换,就可以得到与坐标有关的Hessian估计(定义为
h
^
i
hat{h}_i
h^i):
h
^
i
:
=
∂
2
f
(
x
)
∂
x
i
i
2
≈
f
(
x
+
h
e
i
)
−
2
f
(
x
)
+
f
(
x
−
h
e
i
)
h
2
(7)
hat{h}_i:=frac{partial^2f(x)}{partial x_{ii}^2}approx frac{f(x+he_i)-2f(x)+f(x-he_i)}{h^2}tag{7}
h^i:=∂xii2∂2f(x)≈h2f(x+hei)−2f(x)+f(x−hei)(7)
由于
f
(
x
)
f(x)
f(x)只需要对各个坐标进行一次评估,因此无需其他的评估函数即可获得Hessian估计。
由于黑盒设置,网络结构不明,梯度反向传播被禁止,一个初步的想法是用Eq.6来估计梯度,这需要
2
p
2p
2p次函数估计。但是这个方法实现起来代价很大。
3.3.3 Stochastic coordinate descent
坐标下降方法(Coordinate descent methods)被广泛使用在优化研究中。
每次迭代中,随机选择一个坐标,沿着这个坐标通过近似最小化目标函数
f
(
x
+
δ
e
i
)
f(x+delta e_i)
f(x+δei)更新
δ
delta
δ。
![![[Pasted image 20240110221608.png]]](https://img-blog.csdnimg.cn/direct/8391753686654c5084cd23b578b005c1.png)
最难的一步就是Algorithm 1中的第3步,计算最优坐标更新。
估计完
x
i
x_i
xi的梯度和Hessian后,可以使用一阶或二阶方法近似求解最优的
δ
delta
δ。
一阶的方法中,ADAM明显更优,所以本文使用零阶坐标ADAM:
![![[Pasted image 20240110223102.png]]](https://img-blog.csdnimg.cn/direct/3fecc531b4f94a4291b2b5f9fa03865d.png)
注:每次迭代更新只更新一个坐标。
实践中为了达到GPU的最高效率,通常会逐批量评估目标,估计一个批量的
g
^
i
hat{g}_i
g^i和
h
^
i
hat{h}_i
h^i。一个批量估计128个像素的
g
^
i
hat{g}_i
g^i和
h
^
i
hat{h}_i
h^i,然后一次迭代更新128个坐标。
3.4 Attack-space dimension reduction
定义
Δ
x
=
x
−
x
0
Delta x=x-x_0
Δx=x−x0,
Δ
x
∈
R
p
Delta xinmathbb{R}^p
Δx∈Rp是加在
x
0
x_0
x0上的噪声。起初
Δ
x
=
0
Delta x=0
Δx=0,由于网络输入的
p
p
p很大,使用零阶方法会比较慢,因为估计时要计算大量的梯度。
这里介绍一种减少维度的转换
D
(
y
)
D(y)
D(y)来代替直接优化
Δ
x
∈
R
p
Delta xinmathbb{R}^p
Δx∈Rp的做法,其中
y
∈
R
m
yin mathbb{R}^m
y∈Rm,
range
(
D
)
∈
R
p
text{range}(D)inmathbb{R}^p
range(D)∈Rp,
m
<
p
m<p
m<p。这种转换可以是线性的,可以是非线性的。然后可以用
D
(
y
)
D(y)
D(y)来代替Eq.1中的
Δ
x
=
x
−
x
0
Delta x=x-x_0
Δx=x−x0:
minimize
y
∣
∣
D
(
y
)
∣
∣
2
2
+
c
⋅
f
(
x
0
+
D
(
y
)
,
t
)
,
subject to
x
∈
[
0
,
1
]
p
(8)
begin{aligned} & text{minimize}_y ||D(y)||_2^2+ccdot f(x_0+D(y),t), \& text{subject} text{to} x∈[0,1]^ptag{8} end{aligned}
minimizey∣∣D(y)∣∣22+c⋅f(x0+D(y),t),subject to x∈[0,1]p(8)
D
(
y
)
D(y)
D(y)的使用有效地将攻击空间从
p
p
p降到了
m
m
m,并不修改输入图像的维度,只是减少对抗性噪声的允许维度。
一种简单的变换是将
D
(
y
)
D(y)
D(y)变换为放大操作,将
y
y
y调整为大小为
p
p
p的图像,如双线性插值法。
在Inception-v3网络中,
y
y
y可以是
m
=
32
×
32
×
3
m=32times 32times 3
m=32×32×3维度的小噪声图像,原图是
p
=
299
×
299
×
3
p=299times 299times 3
p=299×299×3的原石图像。
3.5 Hierarchical attack
压缩搜索空间可以提升计算效率,但由于空间的缩小会导致找不到一个较优的结果。如果使用一个较大的
m
m
m,可以搜到较好的结果,但会花费很长的时间。
因此对于大图像和困难的攻击,本文提出了分层攻击(hierarchical attack),使用一系列转换
D
1
,
D
2
,
⋯
D_1,D_2,cdots
D1,D2,⋯转换
m
1
,
m
2
,
⋯
m_1,m_2,cdots
m1,m2,⋯,在优化过程中逐步增加
m
m
m。换句话说,在特定的迭代
j
j
j中,设置
y
j
=
D
i
−
1
(
D
i
−
1
(
y
j
−
1
)
)
y_j=D_i^{-1}(D_{i-1}(y_{j-1}))
yj=Di−1(Di−1(yj−1)),将
y
y
y的维度从
m
i
−
1
m_{i-1}
mi−1增加到
m
i
m_i
mi(
D
−
1
D^{-1}
D−1是
D
D
D的逆操作)。
举例说明:使用
D
1
D_1
D1放大将维度
m
1
m_1
m1从
32
×
32
×
3
32times 32times 3
32×32×3变为
299
×
299
×
3
299times 299times 3
299×299×3,
D
2
D_2
D2放大将维度
m
2
m_2
m2将维度
64
×
64
×
3
64times 64times 3
64×64×3变为
299
×
299
×
3
299times 299times 3
299×299×3。
我们从
m
1
=
32
×
32
×
3
m_1=32times 32times 3
m1=32×32×3开始优化,使用
D
1
D_1
D1作为变换,然后经过一定数量的迭代后(损失函数下降趋势很小后),将
y
y
y从
32
×
32
×
3
32times 32times 3
32×32×3放大到
64
×
64
×
3
64times 64times 3
64×64×3,然后在接下来的几轮迭代中使用
D
2
D_2
D2。
![![[Pasted image 20240111115525.png]]](https://img-blog.csdnimg.cn/direct/749843a37fd840d59b98e4d71b4e70b2.png)
图3:
第一行:RGB通道中,被攻击图像在关键的地方中有明显的变化,其中R通道的变化显著大于其他通道。此处攻击空间为
32
×
32
×
3
32times 32times 3
32×32×3,即使这个空间的攻击会失败,其噪声也会提供关于像素重要性的关键线索。在提升至更大维度的攻击空间后,使用原来小的攻击空间中的噪声去采样重要的像素。
第二行:
64
×
64
×
3
64times 64times 3
64×64×3攻击空间中的重要性可能分布采样。这个重要性是通过像素值变化的绝对值计算的,对每个通道进行
4
×
4
4times 4
4×4的最大值池化,上采样到
64
×
64
×
3
64times 64times 3
64×64×3的维度,然后对所有值进行标准化。
3.6 Optimize the important pixels first
使用坐标下降方法的好处是我们可以主动选择更新的坐标。
在黑盒设置下估计每个像素的梯度和Hessian计算代价很大,于是提出可以有选择性地更新重要的像素(通过重要性采样选择)。
举例来说,对于一次成功的攻击,图像边界的像素通常没什么用,中心的像素通常至关重要。所以在攻击中,对靠近对抗噪声指示的更多像素进行采样。
本文提出将图像划分为
8
×
8
8times 8
8×8的区域,根据区域内像素的变化绝对值分配采样概率。首先对每个区域的绝对值变化进行最大值池化,上采样成期望的维度,然后将所有的值标准化,使其和加起来为1。每几次迭代,根据近几次发生的变化重新更新采样频率。
当攻击空间较小时(如
32
×
32
×
3
32times 32times 3
32×32×3),不会为了提高搜索效率而进行重要性采样。随着维度的不断提升,重要性采样会变得越来越重要。
原文地址:https://blog.csdn.net/xhyu61/article/details/135539131
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56988.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!

![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)