Self-Driving Database Management Systems
- MySummary
ABSTRACT
之前的advisory tools来帮助DBA处理系统调优和物理设计的各个方面,都仍然需要人类对数据库的任何更改做出最终决定,并且是在问题发生后修复问题的反动措施reactionary measures 。
An truly “self-driving” database management system (DBMS)是针对autonomous operation(自主操作)设计的全新架构。系统的所有方面都是由一个integrated planning componen综合规划组件来控制。该组件不仅针对当前的工作负载优化系统,而且还预测未来的工作负载趋势,以便系统可以相应地做好准备。这样,DBMS就可以支持所有以前的调优技术,而不需要人工确定部署它们的正确方式和适当时间。
本文介绍了第一个自驱动DBMS Peloton的体系结构。由于深度学习算法的进步,以及硬件和自适应数据库架构的改进,Peloton的自主能力现在成为可能。
1. INTRODUCTION
其实SQL也是这种思路,关系模型和声明性查询语言就是使用DBMS来消除数据管理负担的想法。使用现有的自动调优工具是一项繁重的任务,因为它们需要费力地准备工作负载样本、分出一些硬件来测试提议的更新,最重要的是要放到DBMS的内部构件。如果DBMS可以自动做这些事情,那么它将消除掉调优过程中部署数据库所涉及的许多代价和成本。
以前的许多self-tuning系统工作都集中在仅针对数据库的单个方面的工具上,例如,一些工具能够选择数据库的最佳逻辑或物理设计,主要是索引、分区方案、数据组织、物化视图。其他工具能够为应用程序选择调优参数。这些工具中的大多数都以相同的方式操作:DBA提供样本数据库和工作负载Track,以指导搜索找到最佳或接近最优的配置。基于云的系统在service-level使用动态资源分配,但不调整单个数据库。
这些都不足以实现完全自主的系统,因为(1) external to the DBMS, (2) reactionary,(3) 无法一次考虑多个问题的整体视图。即:他们从系统外部观察 DBMS 的行为,并建议 DBA 如何进行修复已经发生的问题。Tunning tool是假设DBA能够在一个影响数据库性能的最小窗口来更新DBMS。但是现在DBMS非常复杂,所以如果有工具是自动化的,这样它们就可以单独部署优化。
在本文中,我们证明自动驾驶数据库系统现在是可以实现的。我们首先讨论使用这种系统的主要挑战。然后我们介绍了Peloton的架构,这是第一个为自主操作而设计的DBMS。我们总结了使用Peloton的集成深度学习框架进行工作量预测和行动部署的一些初步结果。
2. PROBLEM OVERVIEW
SFDB的第一个挑战是理解应用程序的工作负载。最基本的级别是将查询分类为 OLTP 或 OLAP。如果DBMS确定了应用程序属于这两个工作负载类中的哪一个,那么它就可以决定如何优化数据库。例如,如果是OLTP,那么DBMS应该将元组存储在面向行的布局中,该布局针对写进行了优化。如果是OLAP,那么DBMS应该使用面向列的布局,这种布局更适合访问表列子集的只读查询。最好是支持混合HTAP工作负载的单个DBMS。这样的系统会自动为不同的数据库段选择适当的OLTP或OLAP优化。
DBMS还需要预测资源利用趋势。要求它能够预测未来的需求,并在对性能影响最小的时候部署优化。不可否认,有一些工作负载异常是DBMS永远无法预料的(例如,“viral”content)。但是这些模型(self-driving?)提供了早期预警,使DBMS能够比外部监控系统更快地制定缓解措施。
有了这些预测模型,DBMS就可以识别出针对预期工作负载调优和优化数据库的潜在actions。
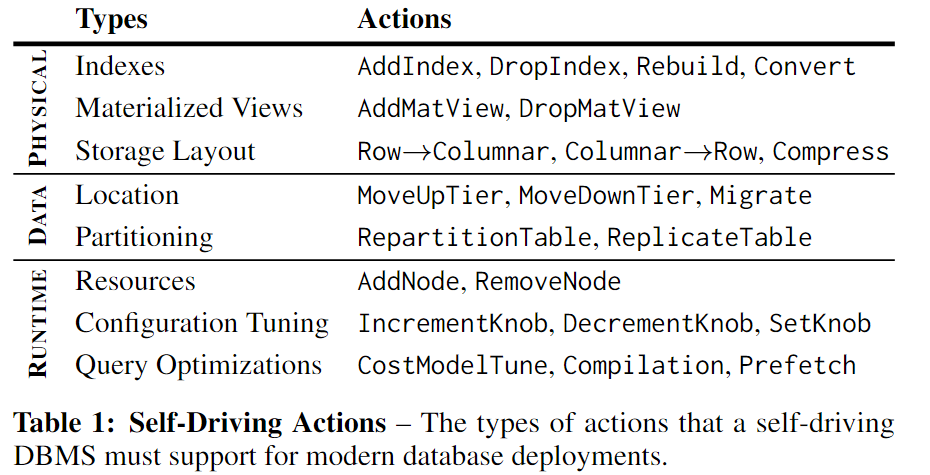
最好是不能支持需要系统外部信息的DBA任务,例如权限、数据清理和版本控制。主要支持上面的三种优化,数据库的物理设计、数据组织的变化、DBMS的runtime行为。对于每个优化操作,DBMS都需要估计它们对数据库的潜在影响。这些估计不仅包括操作部署后将消耗的资源,还包括DBMS将用于部署操作的资源。
还有一个挑战是:DBMS如何有效应用这些优化,不导致性能大幅下降,可以使系统快速适应变化。需要的是一个灵活的内存中的DBMS体系结构,它可以在部署过程中增量地应用优化,而不会对应用程序产生明显的影响。
最后,autonomous DBMS有两个附加的约束:1. 不能要求需要重构代码。2. 要求是它不能依赖于只支持特定编程环境的程序分析工具。确保普适性。
3. SELF-DRIVING ARCHITECTURE
现有的dbms对于自治操作来说过于笨拙,因为在进行更改时通常需要重新启动它们,而且表1中的许多操作太慢。因此,一个新的DBMS的体系结构是最好的,因为集成的self-driving 的 component能对系统更全面和细粒度的控制。
CMU自己的Peloton,使用的是MVCC的变种,另一个优点是它使用内存存储管理器,具有无锁的数据结构和灵活的布局,可以快速执行HTAP工作负载。
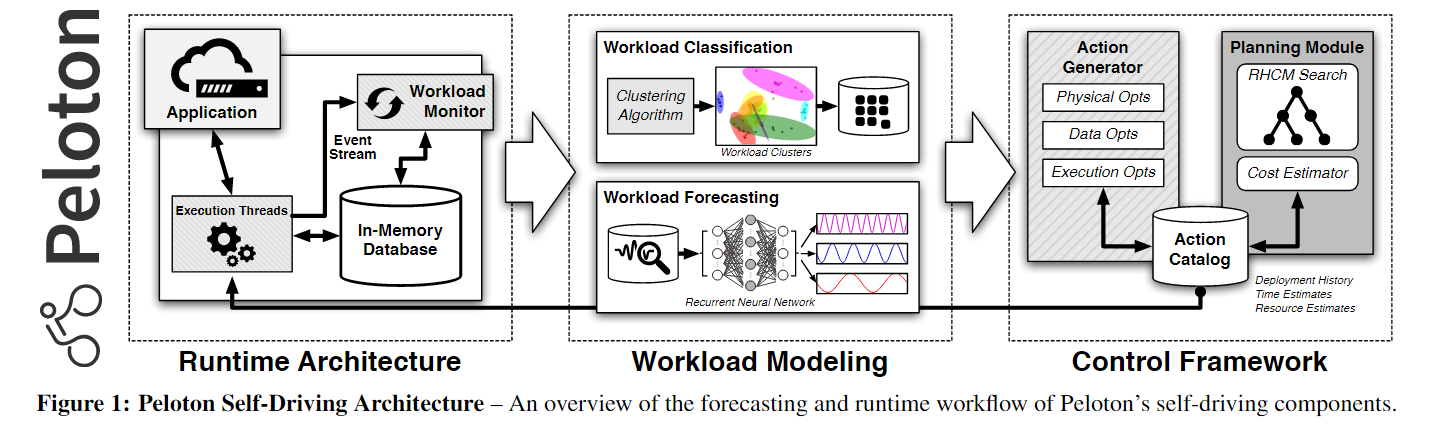
除了环境设置(例如内存阈值,目录路径)等,目标是Peloton在没有任何人为提供的指导信息的情况下有效地运行。系统自动学习如何改善应用程序查询和事务的延迟,这里假设系统延迟是最主要的优化目标,分布式下可以加service costs and energy来作为优化目标。
Peloton包含一个嵌入式的monitor,来follow系统的每条查询过程的数据流,包括监控资源利用率,会周期性地用(1)DBMS/OS检测道德数据和(2)开始/结束事件进行优化操作。DBMS根据这些监视数据为应用程序的预期工作负载构建预测模型。它使用这些模型来识别瓶颈和其他问题(例如,缺少索引、节点过载),然后选择最佳操作。系统在执行此操作的同时仍然处理应用程序的常规工作负载,并收集新的监视数据,以了解这些操作如何影响其性能。
3.1 Workload Classification
第一个组件是DBMS对工作负载进行聚类,使用无监督学习方法对具有相似特征的负载查询进行分组。聚类可以减少DBMS维护的预测模型的数量,从而使预测应用程序的行为变得更容易。Peloton的初始实现使用DBSCAN算法。这种方法已被用于聚类静态OLTP工作负载。
重点是使用查询的什么features来作为聚类的依据,主要有两大类features (1) 查询的运行时度量 (2) 查询的逻辑语义。虽然前者使DBMS能够在不了解其含义的情况下更好地聚类类似查询,但它们其实是对数据库内容或其物理设计的变化更敏感。另一种方法是根据逻辑执行计划的结构(例如,表、谓词)对查询进行分类。这些特性独立于数据库的内容及其物理设计。但是这种特征能否产生了能够生成良好预测模型的聚类以及使用runtime时候的指标,要经常重新训练是否代价太高?结果可能是runtime metrics使系统能够在更短的时间内收敛到稳定状态,因此系统不必经常重新训练其预测模型。或者,即使集群经常变化,硬件加速训练也可以使系统以最小的开销快速重建其模型。
下一个问题是:如何确定聚类何时不再正确?Peloton使用标准的交叉验证技术来确定集群的错误率何时超过阈值。当超过阈值的时候,DBMS必须重新构建它的聚类,会shuffle groups并且可能会需要重新训练之前的预测模型(因为相当于训练集变了)。此外,DBMS还可以利用actions对查询的影响来决定何时重建集群。
3.2 Workload Forecasting
下一个主要任务就是工作负载的预测模型训练,来预测每个workload的到达率(判断接下来是什么样的负载 来提前调整DB来适应),除了异常热点之外,这种预测使系统能够识别工作负载的周期性和数据增长趋势,从而为负载波动做好准备。在DBMS执行一个查询之后,tag每个query一个聚类标签然后填到相应的直方图中(收集数据),该直方图跟踪在一段时间内到达每个聚簇的查询数量。然后Peloton使用这些数据来训练预测模型,以估计app接下来要执行的每个类的查询数量。
之前有一些用ARMA模型来预测的 云场景下 web 服务的负载变化,ARMA可以捕获时间序列数据中的线性关系,缺点是1. 在使用自回归移动平均(ARMA)模型时,通常需要人类专家来决定两个关键参数:差分顺序和模型中的项数。差分顺序是指在数据预处理阶段,为了使时间序列数据稳定,需要进行多少次差分操作。而模型中的项数则指的是自回归项和移动平均项的数量。这两个参数对于模型的准确性和有效性至关重要,但它们的选择往往基于专业知识和经验判断,而非自动化过程。2. 自回归移动平均模型(ARMA)基于线性假设来预测时间序列数据,但这种假设可能不适用于许多数据库工作负载。数据库工作负载常受到外部因素的影响,这些因素可能包括不可预测的用户行为、网络流量、硬件性能变化等。这些外部因素使得数据库工作负载的行为呈现出非线性特征,因此,简单的线性模型(如ARMA)可能无法准确预测这些复杂和动态变化的工作负载。
RNN效果不错适合预测非线性的变化。RNN的准确性取决于训练数据集的大小,但追踪数据库中执行的每个查询会增加模型构建的计算成本。Peloton DBMS采用了一种策略,即维护每个群组的多个RNN,以在不同的时间范围和间隔粒度上预测工作负载。这些粗粒度的RNN虽然准确度较低,但减少了DBMS需要维护的训练数据量以及运行时的预测成本。通过结合多个RNN,DBMS能够既处理需要更高准确性的即时问题,又能适应长期规划,其中估算可以更宽泛。简而言之,这种方法平衡了准确性、数据量和计算成本,以适应不同的预测需求。
3.3 Action Planning & Execution
最后一部分是Peloton的control framework,主要就是监视系统+选择最优actions来改善性能,autonomous组件和DBMS紧密耦合可以相互反馈(RL?),可能能在并发控制和查询优化方面进行RL。
-
Action Generation Action生成
系统会search所有可能有优化作用的actions,然后peloton会记录action和对应action发生之后系统发生什么的history存到catalog里面,以便系统寻找将提供最大利益的行动。它还可以减少冗余actions以降低search的复杂性。每个actions都标注了DBMS在部署该actions的时候需要使用的CPU Cores,所以可以在low demand的时候使用更多的cores来部署actions。控制DBMS resources的knob(旋钮)设计成增量变化(delta changes)而不是绝对值,特定的actions也有相反的actions来取消,例如add index and drop index.
-
Action Planning Action计划(长短期)
有了catalog记录的actions,DBMS根据其预测、当前数据库配置和目标函数(即延迟)选择要部署的actions。这个过程的思想是:> Receding Horizon Control Model, RHCM(滚动时域控制模型可能是叫这个名字),是一种先进的控制策略,常用于管理复杂和动态的系统,例如自动驾驶汽车或高级数据库管理系统。它是一种优化基础的控制方法,也被称为模型预测控制(Model Predictive Control, MPC)RHCM的核心思想是在每个决策时刻,系统都会基于当前的状态和预测的未来状态,评估一系列可能的行动方案。这些行动方案是为了在未来的一个有限的时间范围内(即“滚动时域”)优化某个目标函数,比如最小化能耗或延迟。系统会选择一个最优的行动序列,但只执行序列中的第一个行动,然后在下一个决策时刻重新评估和调整行动计划。这种方法的关键优势在于它能够适应环境变化,并在不断变化的条件下做出最佳决策。它通过定期重新评估情况和调整行动计划,可以灵活地应对未来的不确定性。这使得RHCM非常适合于那些需要频繁调整和优化决策的场景,如动态数据库管理系统中的工作负载管理。
在每个时间点,系统使用预测来估计未来一段有限时间内的工作负载。然后,它寻找一系列操作,这些操作能够最小化目标函数。但是,系统只会应用序列中的第一个操作,并等待该操作完成后,再重复这个过程来处理下一个时间点的情况。这就是为什么使用高性能的DBMS至关重要的原因;如果操作在几分钟内完成,那么系统就不需要监控工作负载是否发生了变化,或决定是否中止正在进行的操作。总的来说,这个过程强调了在动态和变化的环境中,如何有效地规划和调整数据库的操作,以优化性能并应对预测到的工作负载变化。
在RHCM下,planning建模成tree,每一层包含在那个时刻DBMS可以调用的每个action,系统遍历树,根据cost-benefit来计算action的代价,选择一个有最佳结果的action序列,在某个时间点,模块也可能选择不执行任何操作。
为了降低这一过程的复杂性,一种方法是在搜索树的更深层随机选择要考虑的操作,而不是评估所有可能的操作。这种抽样是加权的,使得对于数据库当前状态及其预期工作负载最有益的操作更有可能被考虑。同时,它也避免了那些最近被调用但系统后来撤销其更改的操作。
action的cost是通过部署该操作所需时间的估计,以及在此期间DBMS的性能会下降多少来衡量的。由于以前没有部署过许多操作,因此不可能总是从以前的历史记录生成此信息。因此,系统使用分析模型来估计每个动作类型的成本,然后通过反馈机制自动优化它们。
action的benefit是执行这个action之后query的速度变化,这种benefit是从DBMS内部的query planner的cost model成本模型中得出的。它是install action后查询样本延迟改善的总和,这些改善按照预测模型预测的查询到达率进行加权。还可以考虑根据其时间范围进一步加权,使即时(可能更准确)模型在最终的成本效益分析中具有更大的影响力。
除了cost-benefit,系统还必须估计一个action随着时间的推移将如何影响Peloton的内存利用率。任何导致DBMS超过内存阈值的操作都被认为是不可行的,并被丢弃。
最重要的是系统在选择action时应该考虑到多远的未来,使用太短的水平将阻止DBMS及时准备即将到来的负载峰值,但使用太长的水平可能使它无法缓解突发问题,因为模型太慢了。
由于在每个时间点计算成本-收益是一项耗费资源的工作,文中提到了可能创建另一个深度神经网络来以一种价值函数的方式近似这些成本-收益计算。这意味着使用深度学习的方法来估计操作的潜在价值,而不是每次都进行昂贵的完整计算。通过这种方式,系统能够更高效地估算不同操作的成本和收益,从而快速做出决策,特别是在动态变化的环境中。
-
Deployment
Peloton支持以非阻塞方式部署actions。例如,重新组织表的布局或将其移动到不同的位置不会阻止查询访问该表。有些操作,如添加索引,需要特别考虑,以便DBMS不会因操作进行时数据被修改而产生任何假阴性/假阳性。DBMS还处理来自其集成机器学习组件的资源调度和争用问题。使用单独的协处理器或GPU来处理繁重的计算任务将避免降低DBMS的速度。否则,DBMS将不得不使用专门用于所有预测和计划组件的单独机器。这将使系统的设计复杂化,并由于协调而增加额外的开销。
3.4 Additional Considerations
一个重要非技术的方面是:DBA问题,DBA不愿意放弃对数据库的控制,转而使用自动化系统。考虑以人类可读的格式公开其决策制定过程,例如,如果它选择添加一个索引,它可以向DBA提供一个解释,说明它的模型显示当前的工作负载类似于过去的某个点,在这个点上索引是有帮助的。
还需要支持根据DBA的hints来该更多地优化在线事务处理(OLTP)还是在线分析处理(OLAP)部分的工作负载。
多租户场景下,系统需要能够区分不同数据库的重要性。这可能意味着某些数据库需要更多的资源和优化,而其他数据库则不那么重要
DBA的覆盖机制:系统可能需要提供一种机制,允许DBA覆盖自动决策。DBA的这些人工决策会被系统记录并评估,以确定它们是否有益。然而,系统不被允许自行撤销这些人工决策。
防止DBA做出永久性错误决策:为了防止DBA做出可能对系统有长期负面影响的决策,DBMS可以要求DBA为其手动操作提供一个过期时间。如果这个操作被证明是有效的,DBMS会保留它;否则,系统可以移除它并选择一个更好的方案。
4. PRELIMINARY RESULTS
场景:peloton集成了google tensorflow使用DBMS的内部遥测数据执行工作负载预测。在一个在线讨论网站一个月的流量数据中提取的5200万条查询来训练两个rnn,这些数据的75%用于训练模型,剩余的25%用于验证模型。模型的设计包括两层堆叠的长短期记忆网络(LSTM)层,后接一个线性回归层,并使用了10%的丢弃率来避免过拟合。
- 第一个模型:这个模型预测下一个小时内每分钟将到达的查询数量。它的输入是一个向量,代表过去两小时内每分钟的工作负载,而输出是一个标量,代表一个小时后预测的工作负载。简而言之,这个模型基于过去两小时的详细工作负载数据来预测下一个小时的工作负载。
- 第二个模型:这个模型使用24小时的时间范围,以一小时的粒度进行预测。其输入是代表前一天工作负载的向量,输出是代表一天后预测工作负载的标量。这意味着,基于过去一天的工作负载数据,这个模型预测下一天的总体工作负载。
总的来说,这两个模型分别提供了短期和长期的工作负载预测,使得数据库管理系统能够根据不同的时间尺度和精度需求来优化资源分配和管理策略。
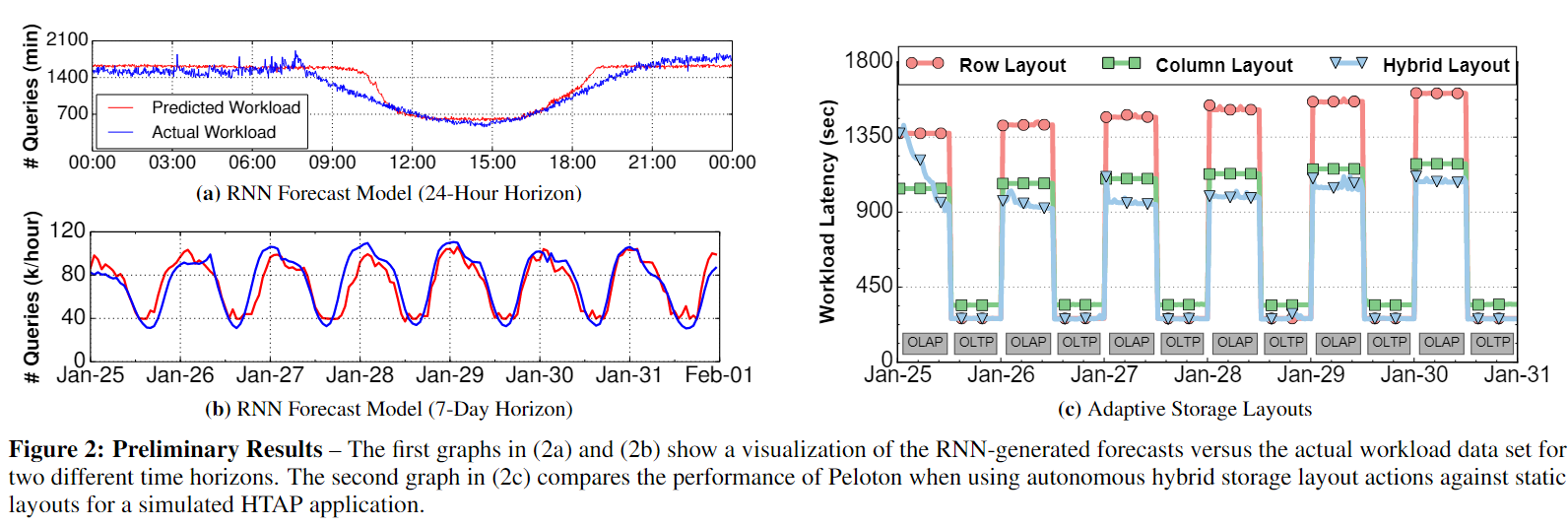
(2a)和(2b)第一个图表显示了两个不同时间范围内rnn生成的预测与实际工作负载数据集的可视化。(2c)中的第二张图比较了Peloton在模拟HTAP应用程序中使用自主混合存储布局操作和静态布局时的性能。
- 训练过程:使用Nvidia GeForce GTX 980 GPU运行Peloton和TensorFlow,第一个和第二个RNN的训练时间分别为11分钟和18分钟。由于所有计算都由GPU执行,因此在训练过程中几乎没有CPU开销。
- 预测准确性:两个模型能够以较低的错误率预测工作负载(1小时RNN的错误率为11.3%,24小时RNN的错误率为13.2%)。这些数据显示出这些模型对于预测工作负载的有效性。
- 运行时开销:研究人员还测量了RNN的存储和计算成本。每个模型大约占用2MB的存储空间。DBMS获取新预测的时间为2毫秒,向模型中添加新数据点的时间为5毫秒。后者时间较长,因为TensorFlow执行反向传播来更新模型的梯度。
- 数据优化操作:使用这些模型,Peloton启用了数据优化操作,根据访问它们的查询类型将表迁移到不同的布局。每个表的“热”元组存储在针对OLTP优化的行式布局中,而同一表中的其他“冷”元组存储在更适合OLAP查询的列式布局中。
- 实际工作负载测试:研究人员使用模拟的HTAP(混合事务/分析处理)工作负载进行测试,该工作负载在白天执行OLTP操作,晚上执行OLAP查询。他们在Peloton中执行
图2c看出:
- 工作负载适应性:Peloton随时间调整,逐渐转换到适合工作负载段的布局。在第一个工作负载段之后,DBMS将行式布局的元组迁移到更适合OLAP查询的列式布局。这导致延迟下降,并与纯列式系统的性能匹配。
- 工作负载变化应对:当工作负载转换到OLTP查询时,自驾系统比静态的列式布局表现得更好,因为它执行的内存写操作更少。
- 初步结果的应许性:这些初步结果显示出前景:
- RNNs准确预测了查询的预期到达率。
- 硬件加速训练对DBMS的CPU和内存资源影响较小。
- 系统部署操作时不会减慢应用程序的速度。
- 后续步骤:下一步是使用更多样化的数据库工作负载和支持更多操作来验证这种方法。
这些发现表明,Peloton项目在自动优化数据库布局和处理不同类型的工作负载方面取得了显著进展,显示了自驾数据库系统在实际应用中的潜力和有效性。
5. RELATED WORK
目前没有一个现有的系统能够结合所有这些技术来实现完全的操作独立性,而不需要人工监视、管理和调优DBMS。
-
Workload Modeling
马尔可夫模型用于工作负载状态:一些方法使用概率马尔可夫模型来表示应用程序的工作负载状态。利用这些模型来判断工作负载何时发生了显著变化,指示DBA需要更新数据库的物理设计。
预测下一个查询:其他研究生成马尔可夫模型,根据应用程序当前执行的查询来估计它接下来会执行的查询。这对于预取数据或应用其他优化措施很有用。
交易预测:构建马尔可夫模型,专门用于预测交易序列中的下一个交易。
系统调优的工作负载分类:识别样本工作负载是更适合OLTP(在线事务处理)还是OLAP(在线分析处理)风格的应用程序,并相应地调整系统配置。
OLAP查询的资源分配:使用决策树来调度和分配专门用于OLAP查询的资源。
从未标记的工作负载中提取查询序列:一些方法专注于从未标记的工作负载跟踪中提取查询序列。
OLTP交易分类:DBSeer根据查询的逻辑语义和它们访问的元组数量来分类OLTP交易。然后,它结合分析和学习的统计模型来预测并发工作负载下的DBMS利用率。
云计算系统的长期资源需求预测:大多数之前关于预测长期资源需求的研究都集中在云计算系统上,文献中提出基于ARMA的方法来预测未来资源利用趋势。
数据库即服务(DBaaS)平台中的预测模型:预测模型也用于DBaaS平台中的租户放置和负载均衡。
-
Automated Administration
微软AutoAdmin:微软的AutoAdmin是利用数据库管理系统(DBMS)内置的成本模型的先驱。它使用查询优化器的内置成本模型来估算物理设计变更的好处。这样做避免了工具选择的良好索引与系统用于查询优化的索引之间的不一致。这意味着AutoAdmin直接利用了DBMS内部的成本评估机制来指导其物理设计优化决策。
配置工具的限制:配置工具不能使用查询优化器的内置成本模型。这是因为这些模型是为了在固定的执行环境中比较替代执行策略而生成查询执行工作量的估算。换言之,这些模型专注于评估执行单个查询的成本,而不适用于评估整体的物理设计更改。各大DBMS厂商的工具:所有主要的DBMS厂商都有自己的专有工具,这些工具在支持的自动化程度上各不相同。这些工具通常专门针对各自DBMS的特性和优化策略进行设计。
iTuned工具:iTuned是一个通用工具,它在DBMS未充分利用时持续进行微小的配置更改。这表明iTuned旨在动态调整配置,以优化DBMS的性能和资源利用率
IBM的DB2 Performance Wizard:IBM发布了DB2 Performance Wizard工具,该工具向数据库管理员(DBA)询问有关其应用程序的问题,然后根据他们的回答提供配置设置(knob settings)。该工具使用DB2工程师手动创建的模型,因此可能无法准确反映实际的工作负载或运行环境。
自调整内存管理:IBM后来发布了带有自调整内存管理器的DB2版本,该管理器使用启发式方法来分配内存给DBMS的内部组件。类似地,Oracle开发了一个系统来识别由于配置错误导致的瓶颈。
Oracle的配置修改评估工具:Oracle的后续版本包括一个工具,用于估计配置修改的影响。Microsoft的SQL Server也使用了类似的方法。
DBSherlock:最近,DBSherlock工具帮助DBA通过比较性能追踪数据中系统运行缓慢的区域和正常行为的区域来诊断问题。
在线优化和数据库裂解技术:在线优化方面,最有影响的方法之一是MonetDB的数据库裂解技术,使得DBMS能够基于查询访问数据的方式增量地构建索引.
-
Autonomous DBMSs
IBM的DB2自动化尝试:IBM对DB2进行了一项完全自动化的概念验证。该系统使用了现有工具并结合了一个外部控制器和监视器。当资源阈值被超过时(例如,死锁的数量增加),该系统会触发变更。然而,这个原型仍然需要人类数据库管理员(DBA)来选择调优优化措施,并偶尔重启DBMS。与自驾式DBMS不同,这个系统只能在问题发生后做出反应,因为它缺乏预测功能。
云计算平台中的自动化:自动化在云计算平台中更为常见,因为云平台的规模和复杂性。例如,微软Azure使用遥测数据建模DBMS容器的资源利用率,并自动调整分配,以满足服务质量(QoS)和预算限制.
云中的黑盒控制器:还有一些控制器用于云中应用程序的黑盒配置。
使用RHCM的尝试:文献[Efficient Autoscaling in the Cloud Using Predictive Models for Workload Forecasting]中的作者使用与Peloton相同的滚动时域控制模型(RHCM),但他们只支持自驾式DBMS的一部分操作
6. CONCLUSION
随着big data的发展,autonomous数据库需求更加强烈,这样的系统将消除部署任何规模数据库的人力资本障碍,使组织更容易从数据驱动的决策制定应用中获得好处。本文概述了Peloton DBMS的self-driving架构。我们认为,由于深度神经网络、改进的硬件和高性能数据库架构的进步,使得这种系统现已可能。
原文地址:https://blog.csdn.net/qq_47865838/article/details/135608577
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_59206.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!