本文介绍: 众所周知,随着时间的推移,算力成为了 AI 行业演进一个不可或缺的因素。在数据量日益庞大、模型体量不断增加的今天,企业对分布式算力和模型训练效率的需求成为了首要的任务。如何更好的、更高效率的以及更具性价比的利用算力,使用更低的成本来训练不断的迭代 AI 模型,变成了迫切需要解决的问题。而分布式训练的演进很好的体现了 AI 模型发展的过程。
作者:霍智鑫
众所周知,随着时间的推移,算力成为了 AI 行业演进一个不可或缺的因素。在数据量日益庞大、模型体量不断增加的今天,企业对分布式算力和模型训练效率的需求成为了首要的任务。如何更好的、更高效率的以及更具性价比的利用算力,使用更低的成本来训练不断的迭代 AI 模型,变成了迫切需要解决的问题。而分布式训练的演进很好的体现了 AI 模型发展的过程。
Distributed Training
分布式训练一般分为两种类型,数据并行和模型并行。数据并行是指每个训练 Worker 都保存有一份模型的副本,然后将大规模的数据进行切分,分布到每个训练 Worker 上进行计算,最后再进行集合通信统一计算结果的过程。在相当一段的时间内,该种模式是分布式训练的主流模式,因为模型的规模足以放进单个训练 Worker 之中,而数据的规模才是整体训练效率的瓶颈。利用分布式数据并行可以充分利用集群中的算力资源,并行处理庞大的数据集,以达到加速训练的效果。
而模型并行则是在模型非常庞大的情况下将模型进行切分,分布到不同的训练 Worker 中,然后训练数据按照模型的结构分布经过不同的训练 Worker,以达到用分布式的算力来训练大模型的效果。现在的大语言模型由于其体量的庞大,所以一般都是使用模型并行的模式来进行训练。
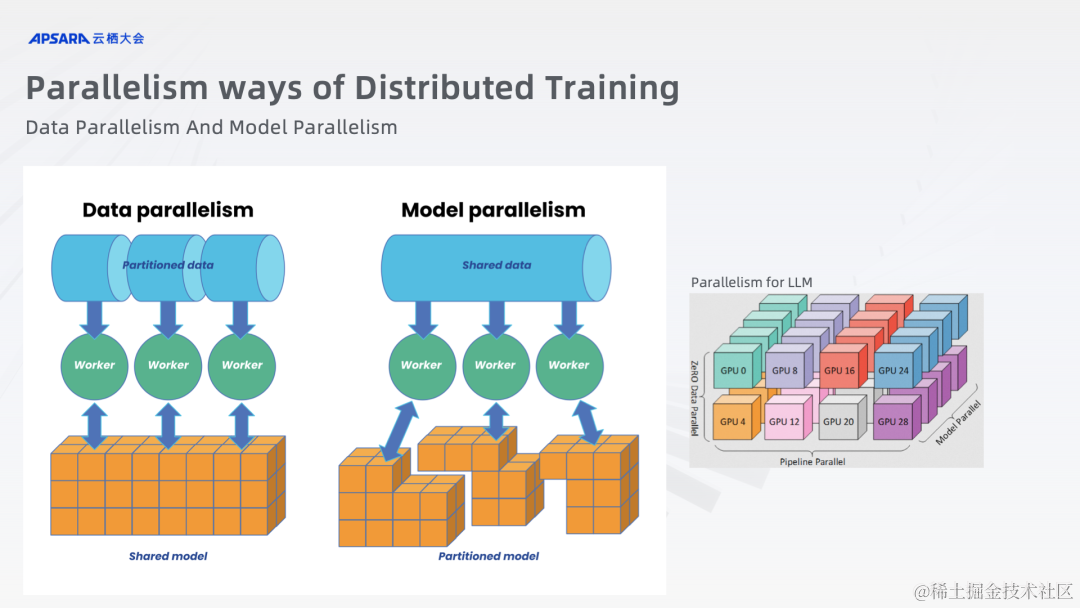
基于数据并行的分布式训练又分为两种不同的架构。
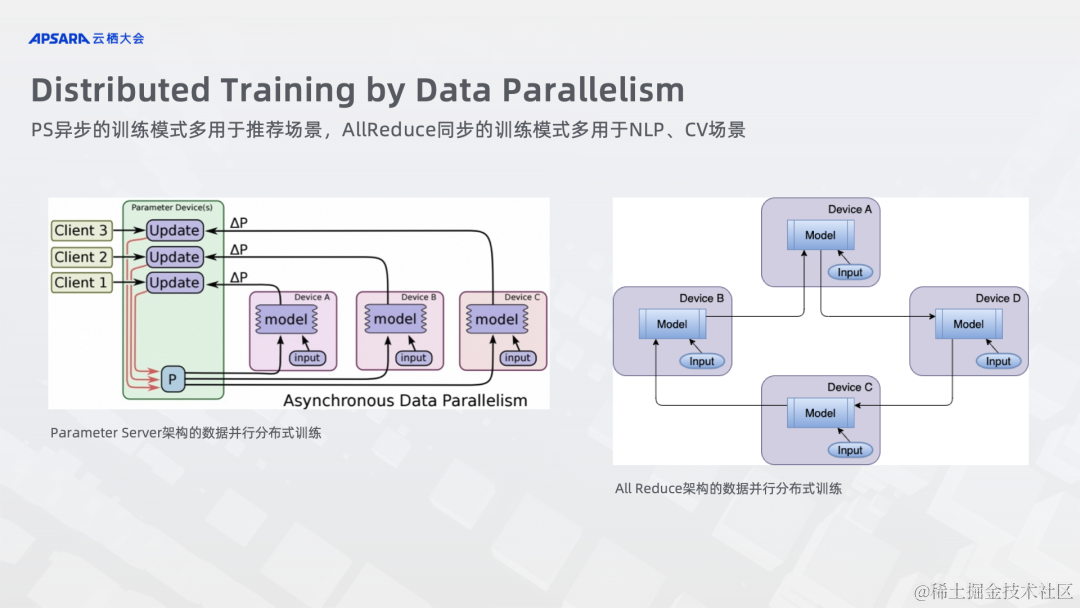
Elastic Training


PS Elastic Training
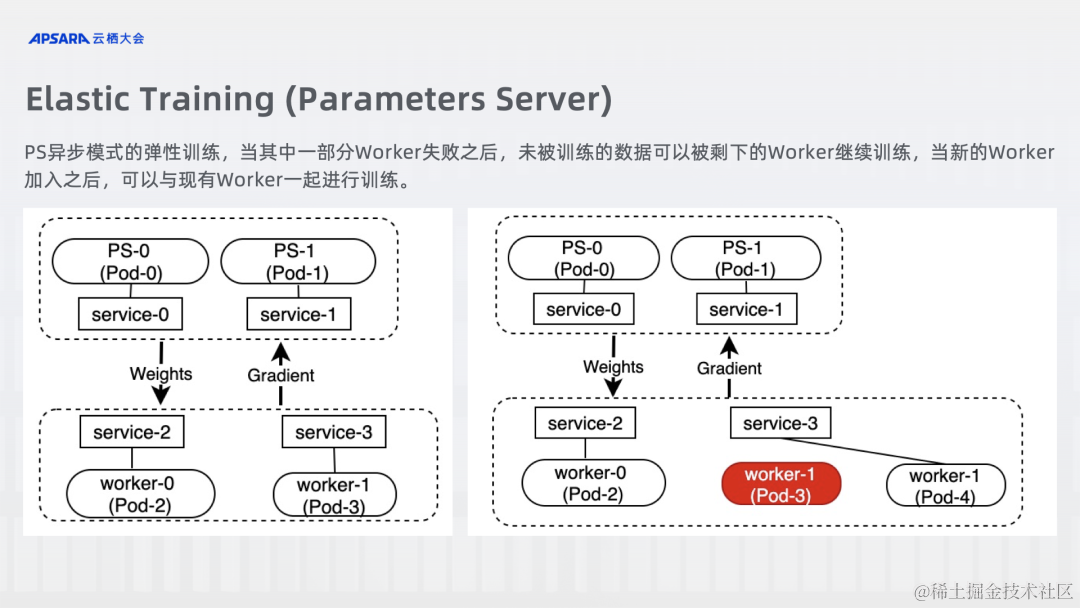
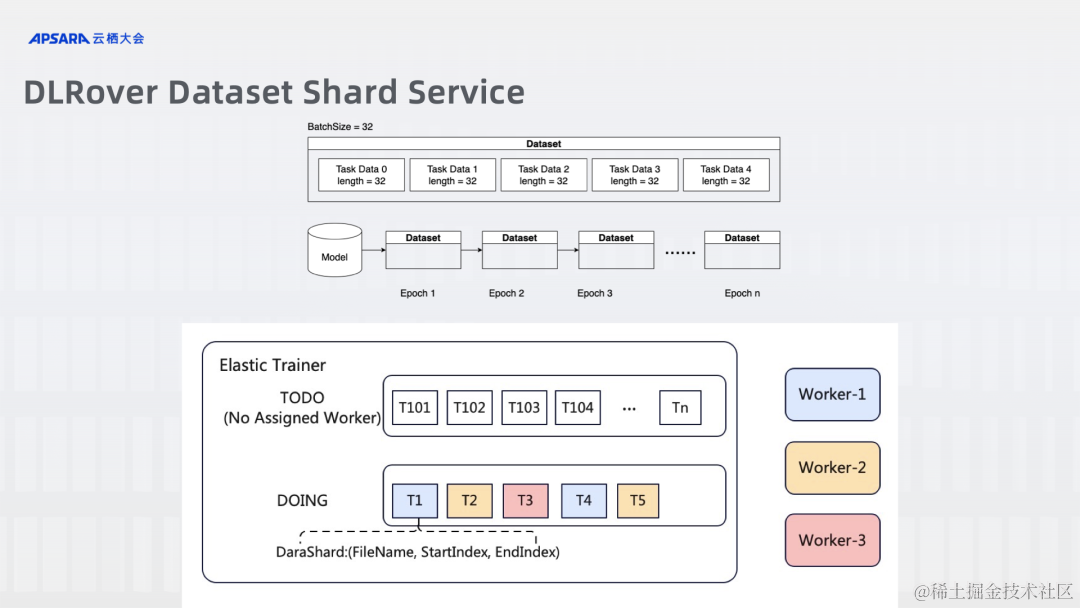
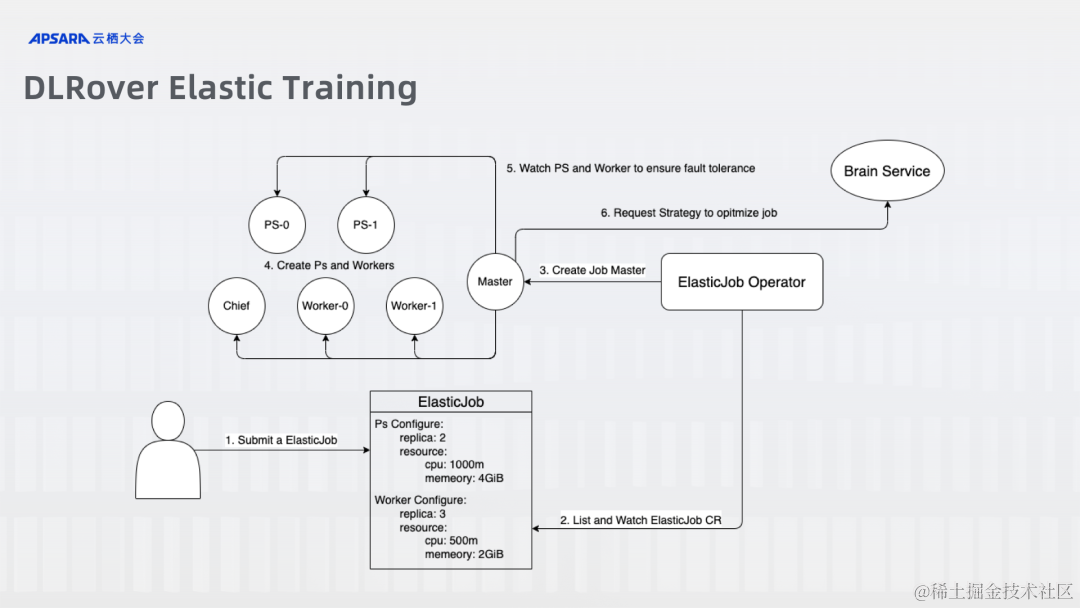
DLRover
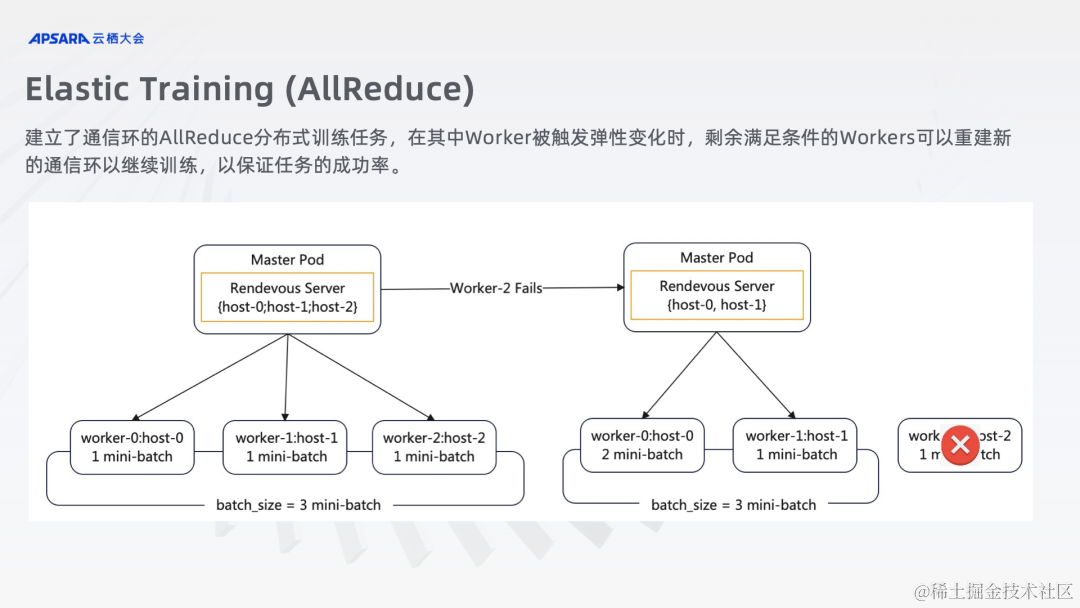
AllReduce Elastic Training
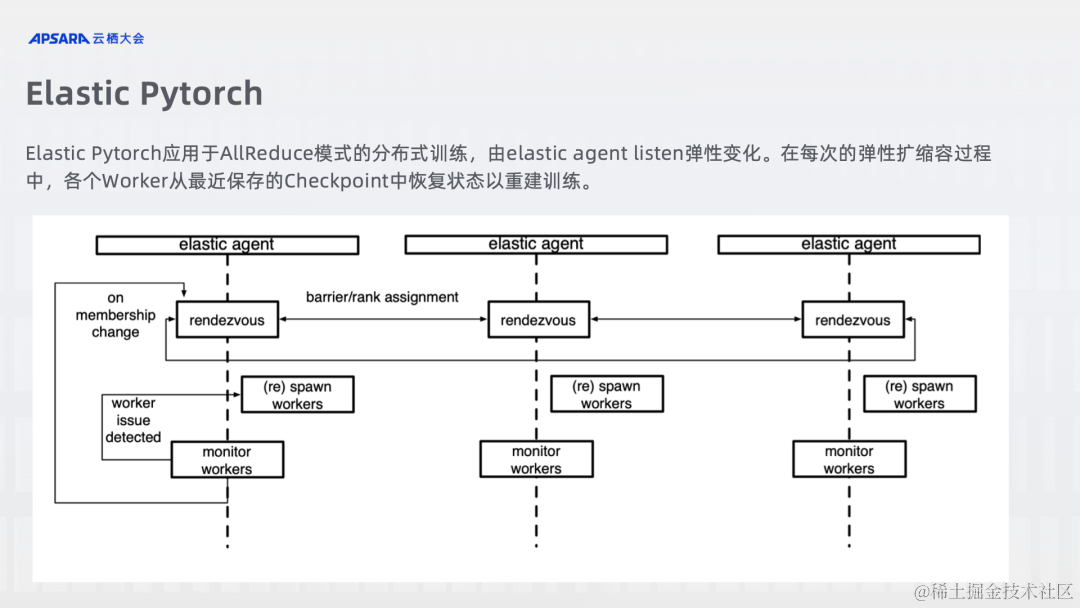
Elastic Pytorch
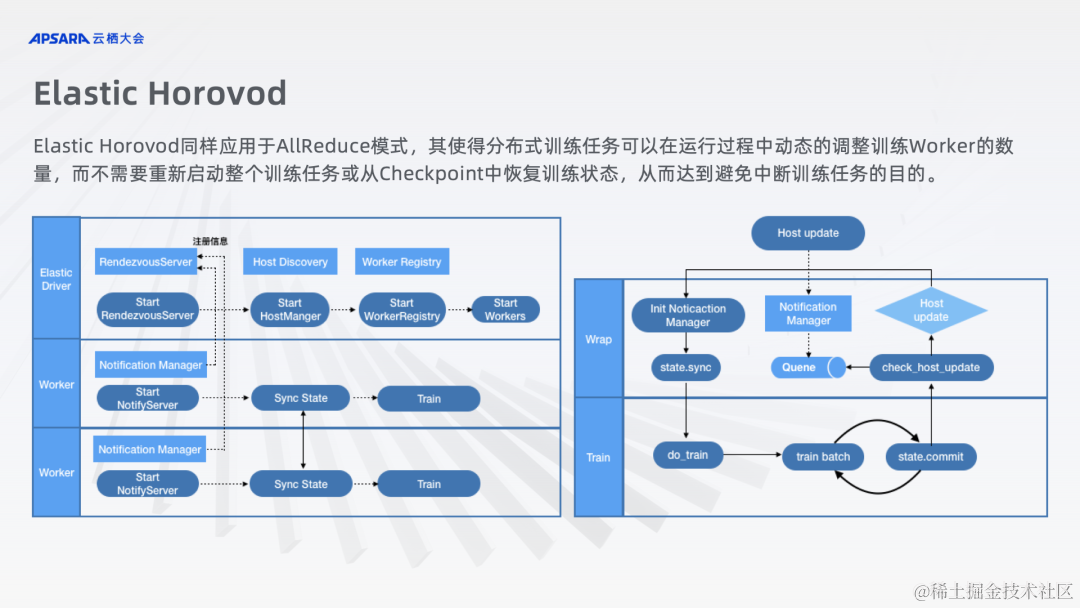
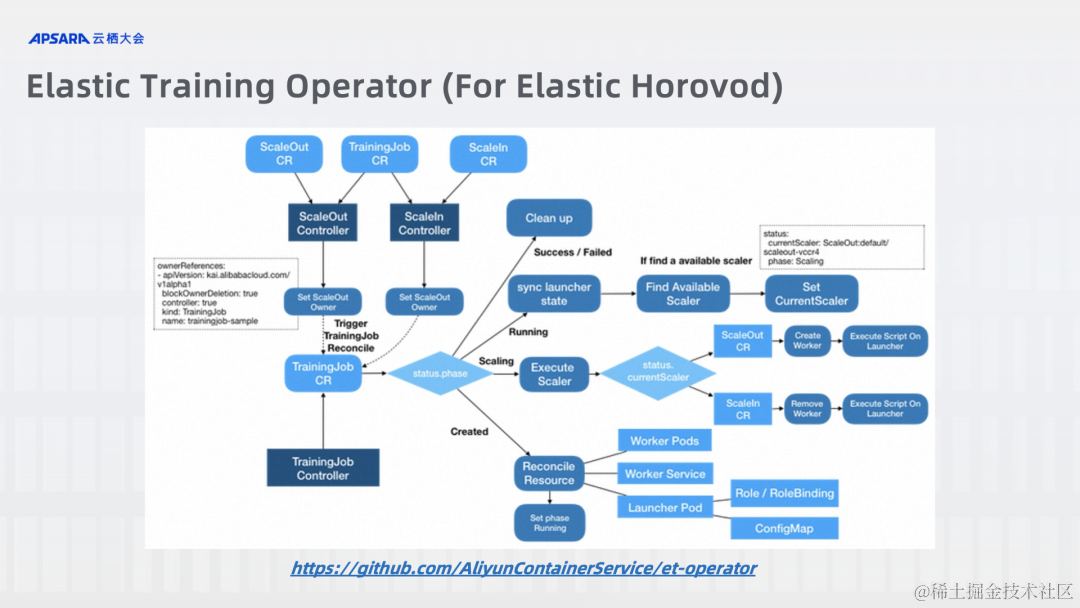
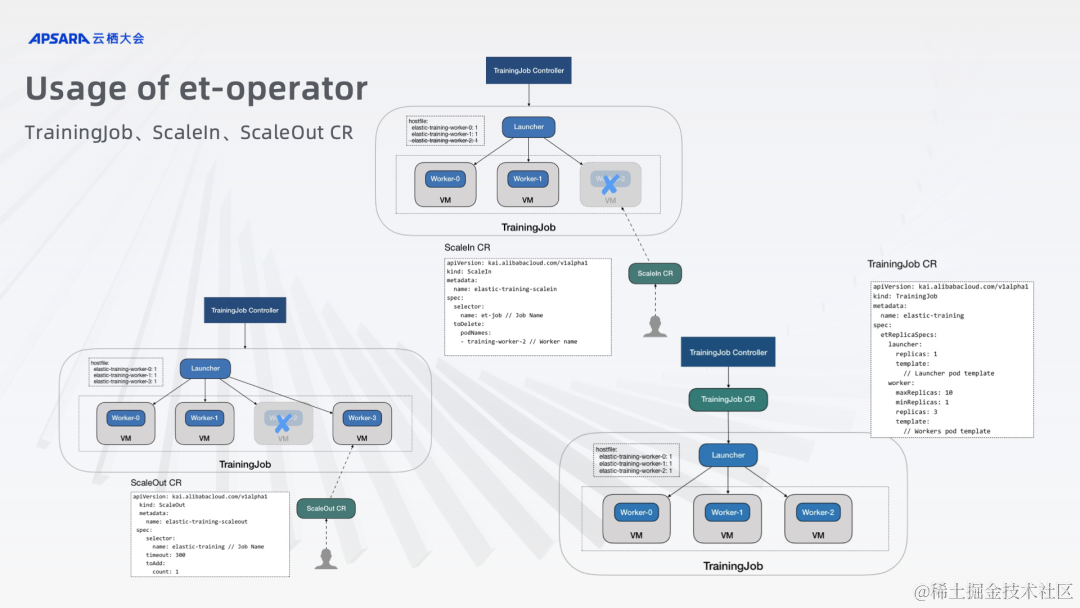
Elastric Horovod
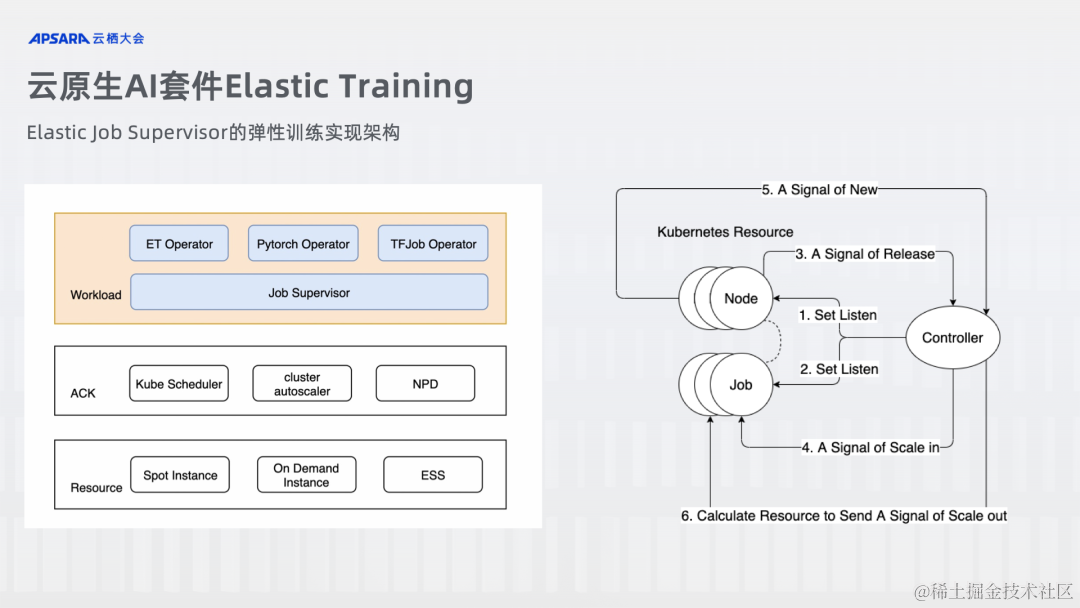
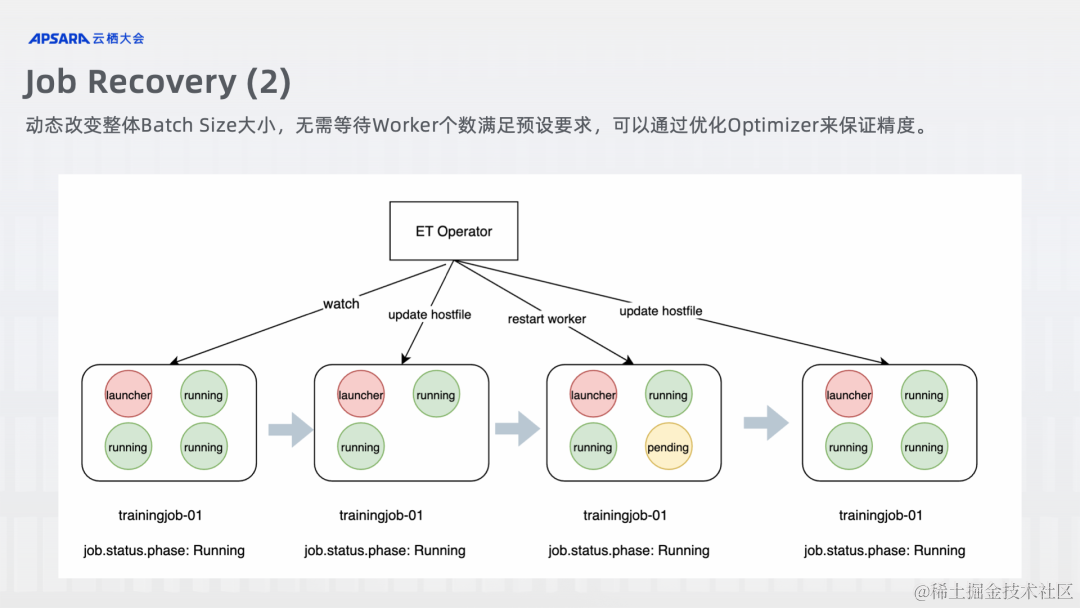
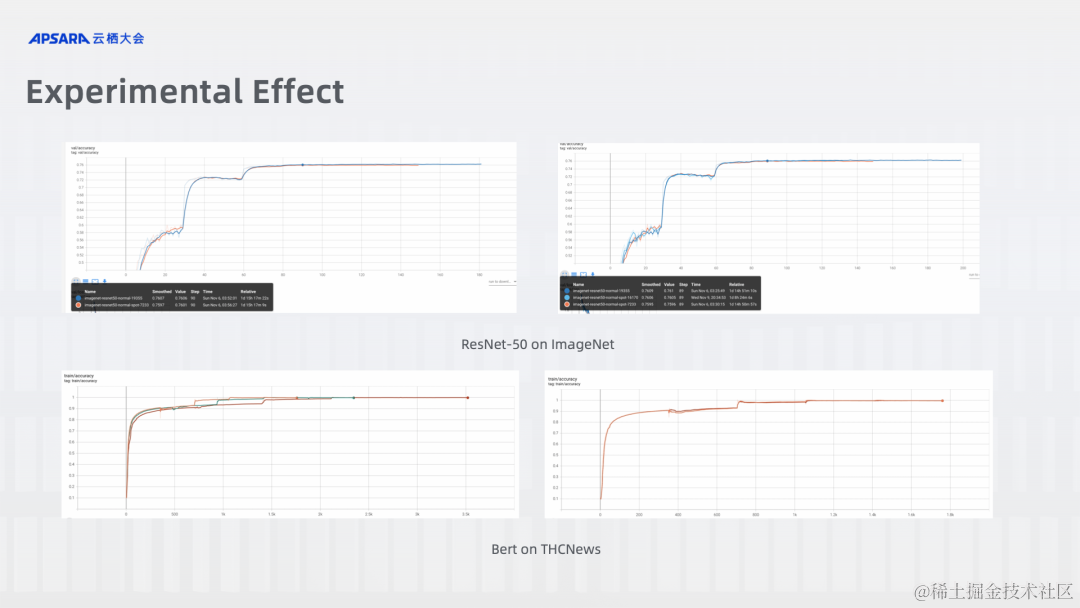
ACK 云原生 AI 套件 Elastic Training
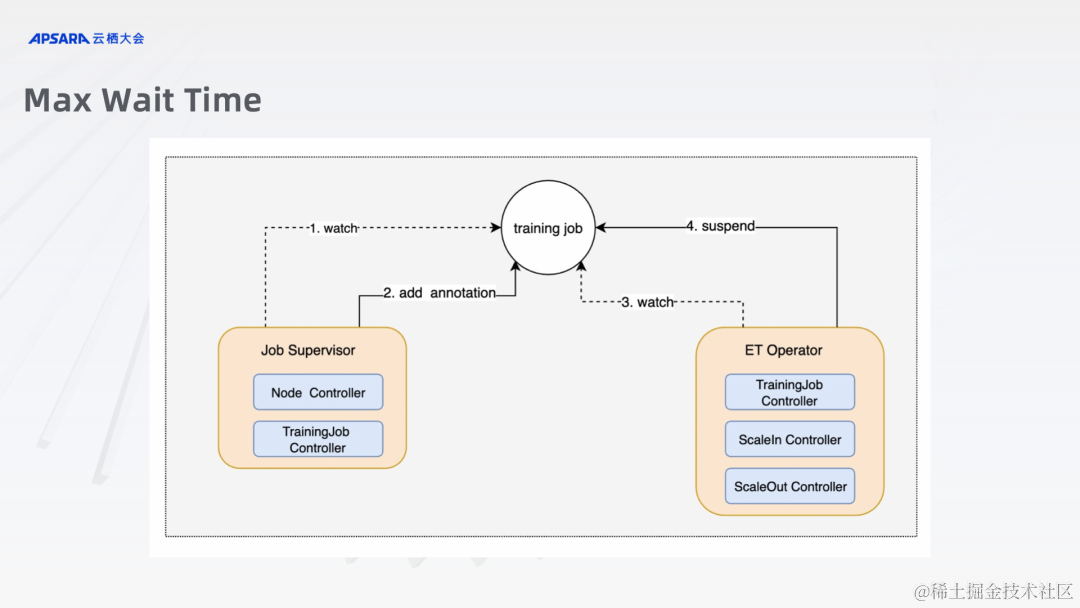
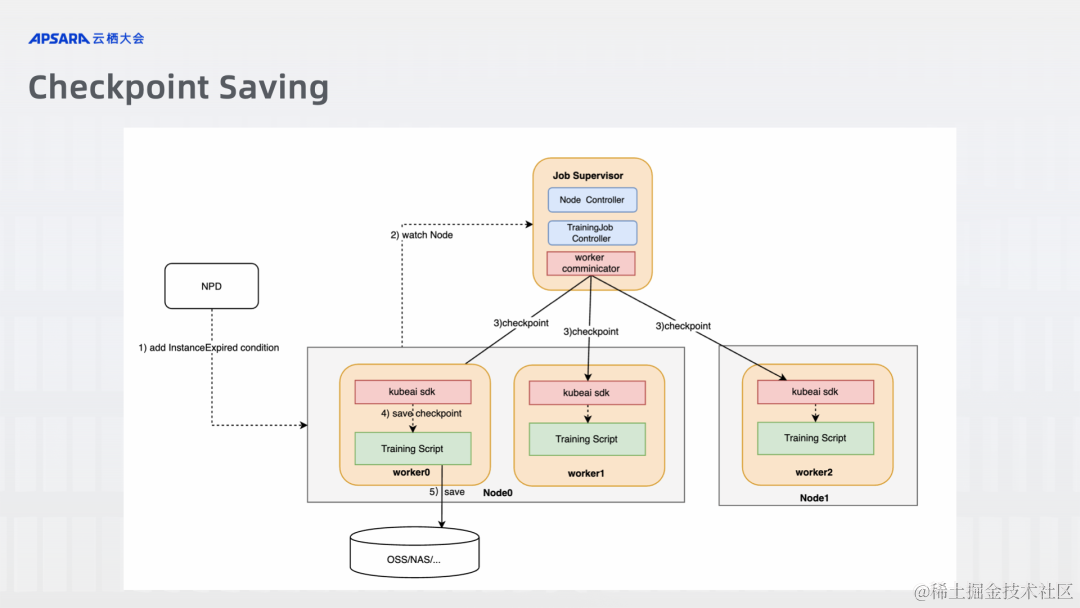
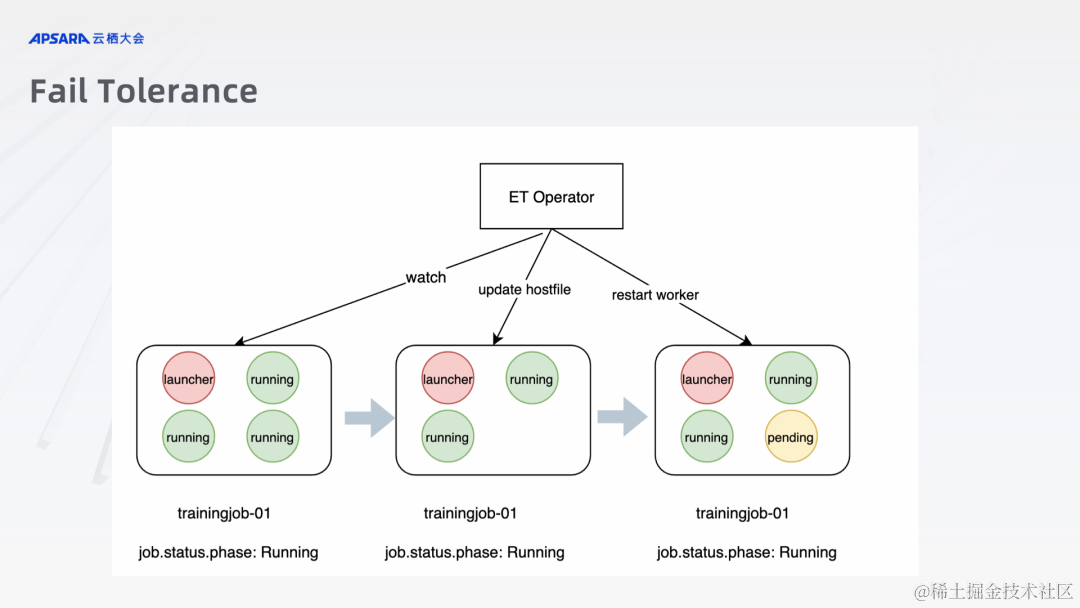
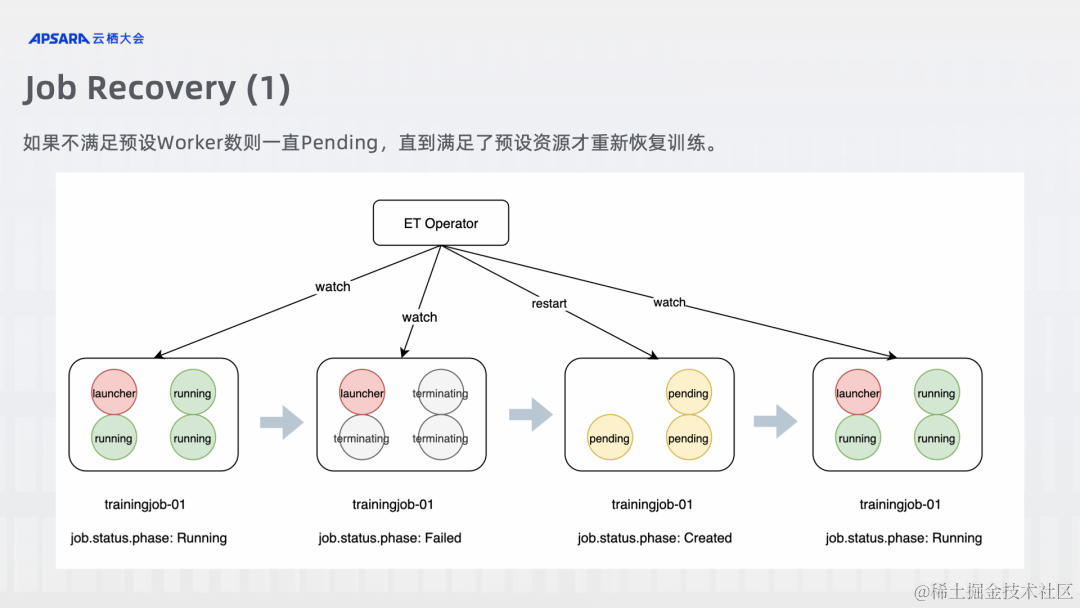

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。