01 正则表达式(Regular expressions)
《Python数据分析技术栈》第03章 01 正则表达式(Regular expressions)
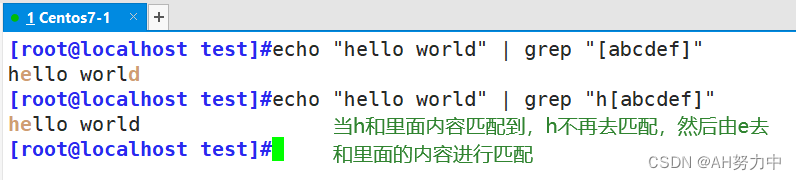
A regular expression is a pattern containing both characters (like letters and digits) and metacharacters (like the * and $ symbols). Regular expressions can be used whenever we want to search, replace, or extract data with an identifiable pattern, for example, dates, postal codes, HTML tags, phone numbers, and so on. They can also be used to validate fields like passwords and email addresses, by ensuring that the input from the user is in the correct format.
正则表达式是一种包含字符(如字母和数字)和元字符(如 * 和 $ 符号)的模式。正则表达式可用于搜索、替换或提取具有可识别模式的数据,例如日期、邮政编码、HTML 标记、电话号码等。正则表达式还可用于验证密码和电子邮件地址等字段,确保用户的输入格式正确。
使用正则表达式解决问题的步骤(Steps for solving problems with regular expressions)
Support for regular expressions is provided by the re module in Python, which can be imported using the following statement:
Python 中的 re 模块提供了对正则表达式的支持,可以使用以下语句导入该模块:
If you have not already installed the re module, go to the Anaconda Prompt and enter the following command: