目录
一、空间索引快速理解
假设用户A使用某社交应用希望查看附近的人,以扩展社交圈或寻找志趣相投的人。
假设用户B使用某共享单车应用希望看到当前附近可以骑行的车,以快速查找并进行骑行计划。
这两类场景都需要通过地理位置服务来实现“附近的X”功能。

可以通过限定“附近”的范围来减少检索空间。一般可以将所有的检索空间划分为多个区域并做好编号,然后以区域编号为 key 做好索引。以查找附近的人为例,可以先快速查询到自己所属的区域,然后再将该区域中所有人的位置取出,计算和每一个人的距离就可以了。
(一)区域编码
对于一个完整的二维空间,可以通过二分的思想进行均匀划分。具体方法是在水平方向和垂直方向上分别进行二分,形成四个均匀划分的子空间。对这四个子空间进行编号,可以使用两个比特位。在水平方向上,用 0 表示左边的区域,用 1 表示右边的区域;在垂直方向上,用 0 表示下面的区域,用 1 表示上面的区域。按照顺时针的顺序,从左下角开始编号为 00、01、11 和 10。

通过这样的划分和编号方式,整个二维空间就被划分为多个具有唯一标识的区域。通过继续沿用区域划分的思路,可以将每个区域再分为四块,形成更细致的划分。整个空间会被划分成16块区域,对应的编号也会增加两位。例如,编号为01的区域被划分成4小块,分别为0100、0101、0110、0111。这就是区域编码的基本思路。
(二)区域编码检索
有了区域编码方式后,查询附近的人可以利用区域编码的一维特性,将二维空间的两个维度用一维编码表示。
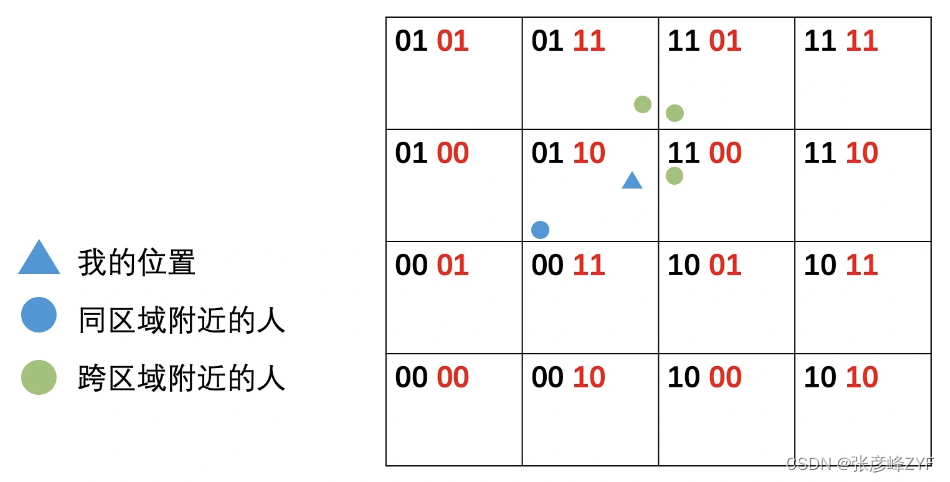
具体的查询步骤如下:
- 区域编码存储: 将区域编码作为 key 存储在有序数组中。有序数组的排序方式按照区域编码的大小进行排列。
- 二分查找: 使用二分查找技术在有序数组中快速定位自己所属区域的编码。这种方式适用于静态的区域信息,如果区域动态增加,也可以考虑使用二叉检索树或跳表等数据结构进行索引。
- 区域查询: 查询到自己所属区域的编码后,从索引中获取所有属于该区域的用户信息。这一步可以通过有序数组、二叉检索树、跳表等结构进行高效查询。
- 计算距离和排序: 对获取的用户信息进行距离计算,计算每个用户与自己的距离。最后,根据距离排序,展现给用户。
但找到的“附近的人”实际上是同一区域的人,并不一定是离自己最近的人。对于边缘区域的用户,可能在邻接区域里,因此在实际应用中需要权衡查询效率和精确度。如图中的蓝色圆点相比绿色圆点反而是更远的。
为了更精确地找到附近的人,可以建立一个更大的候选集合,将目标区域周围的邻接区域的用户都加入,然后进行距离计算和排序。
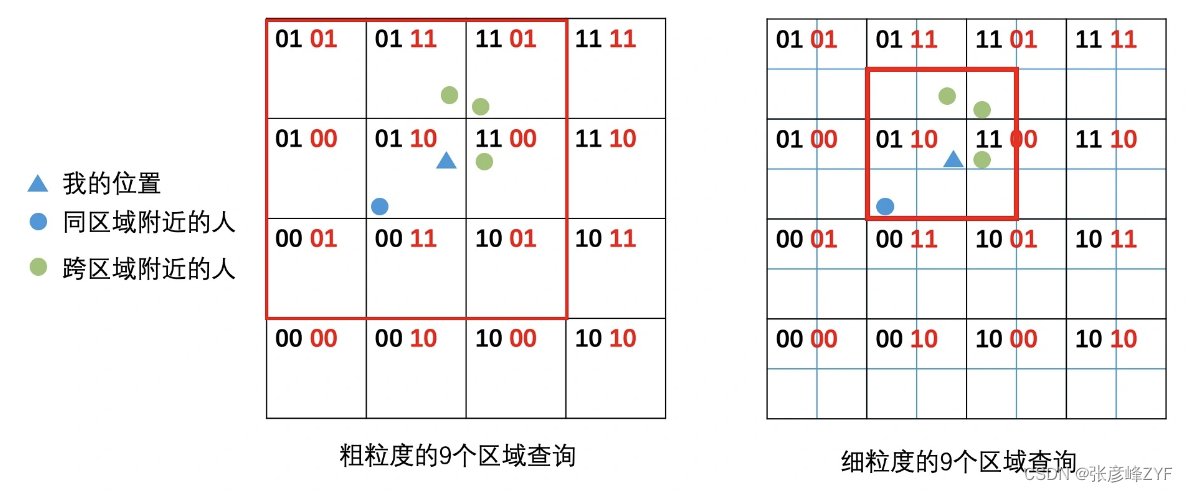
操作步骤如下:
-
确定查询半径: 根据期望的查询半径,以当前区域为中心向周围扩散。例如,如果查询半径是一个区域边长的一半,可以涵盖目标区域周围一圈的邻接区域。
-
扩展候选集: 将扩展后的邻接区域中的用户都加入候选集。在示例中,如果考虑目标区域周围的8个邻接区域,可以确保不遗漏任何可能的附近用户。
-
距离计算和排序: 对候选集中的用户进行距离计算,计算每个用户与目标用户的距离。最后,根据距离排序,得到最终的查询结果。
虽然这样的操作会增加计算量,但可以提供更精确的解。如果希望降低计算量,可以考虑提高区域划分的粒度,使得在相同查询半径下需要检索的用户数量减少。这样可以在保持查询效果的情况下降低计算复杂度。
回到区域编码方案本身:要快速寻找目标区域周围的邻接区域的编码,可以利用区域编码的奇偶位拆分水平编码和垂直编码。
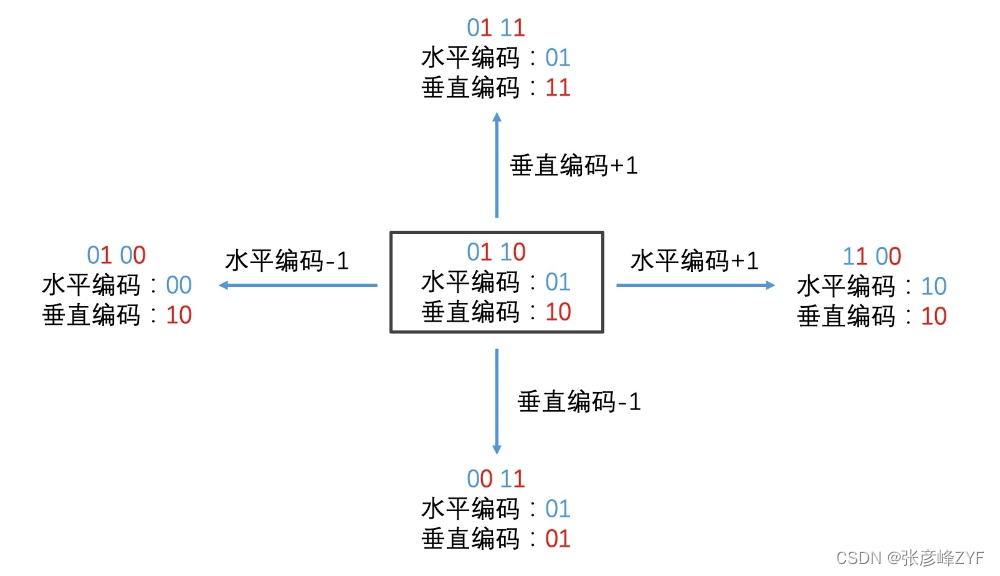
通过对这两块编码进行操作,可以得到不同方向上邻接的8个区域的编码。具体操作步骤如下:
-
分解编码: 对于一个区域编码,例如0110,可以分解成水平编码(01)和垂直编码(10)。
-
获取邻接区域编码: 对于当前区域,分别对水平编码和垂直编码进行加1或减1的操作,得到不同方向上邻接的8个区域的编码。例如,如果水平编码是01,那么右边区域的水平编码就是10,垂直编码相同。
通过这样的操作,可以快速获取目标区域周围邻接区域的编码,进而进行候选集的扩展和附近用户的查询。这种方法利用了区域编码的特性,实现了高效的邻接区域查找。
(三)Geohash 编码
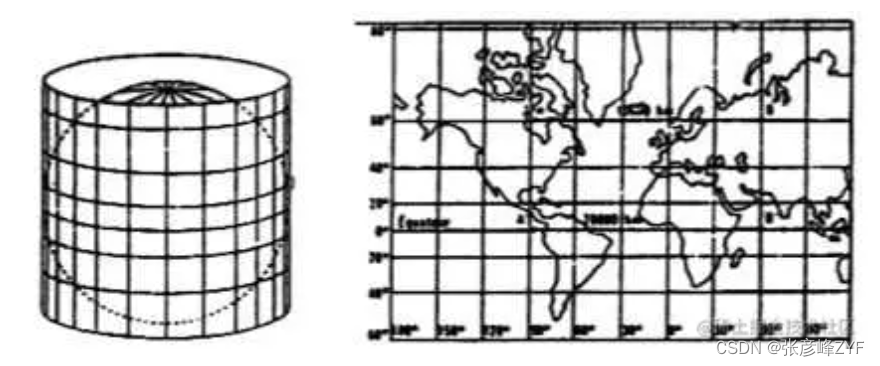
在实际工作中,用户的地理位置坐标通常用经纬度表示,而地球可以看作一个大的二维空间,经度和纬度就是这个空间的水平和垂直切分方向。地球的纬度区间是[-90,90],经度是[-180,180]。
如果给出的用户纬度(垂直方向)坐标是 39.983429,经度(水平方向)坐标是 116.490273,那求这个用户所属的区域编码的过程,就可以总结为 3 步:
- 在纬度方向上,第一次二分,39.983429 在[0,90]之间,[0,90]属于空间的上半边,因此我们得到编码 1。然后在[0,90]这个空间上,第二次二分,39.983429 在[0,45]之间,[0,45]属于区间的下半边,因此得到编码 0。两次划分之后得到的编码就是 10。
- 在经度方向上,第一次二分,116.490273 在[0,180]之间,[0,180]属于空间的右半边,因此得到编码 1。然后在[0,180]这个空间上,第二次二分,116.490273 在[90,180]之间,[90,180]还是属于区间的右半边,因此得到的编码还是 1。两次划分之后得到的编码就是 11。
- 纬度的编码和经度的编码交叉组合起来,先是经度,再是纬度。这样就构成了区域编码为 1110。
实际上,如果区域划分的粒度非常细,就要持续、多次二分。而每多二分一次,我们就需要增加一个比特位来表示编码。
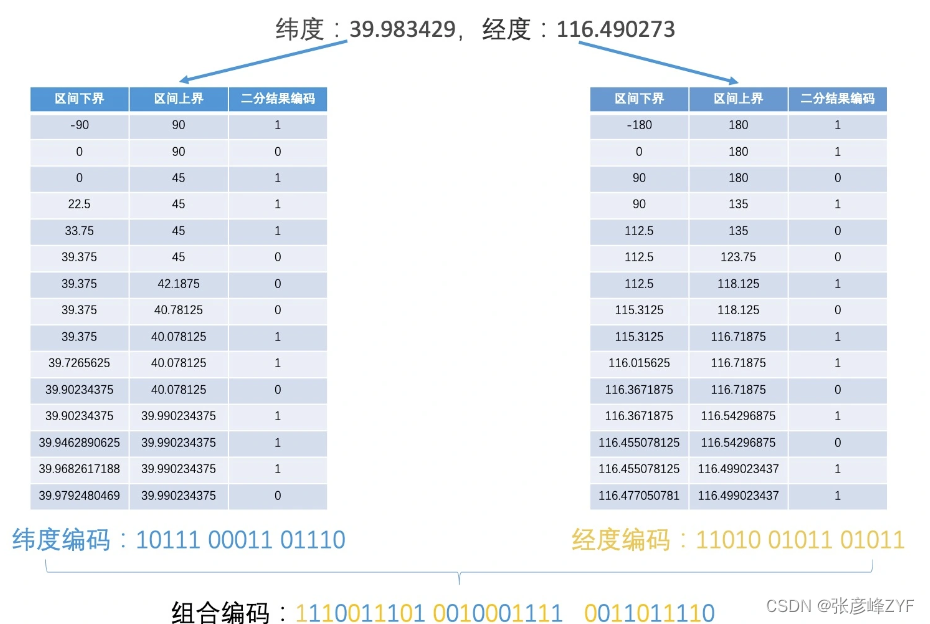
如果经度和纬度各二分 15 次的话,那我们就需要 30 个比特位来表示一个位置的编码。那上面例子中的编码就会是 11100 11101 00100 01111 00110 11110。
这样得到的编码会特别长,为了简化编码表示,可以以 5 个比特位为一个单位,把长编码转为 base32 编码,最终得到的就是 wx4g6y。这种将经纬度坐标转换为字符串的编码方式,就叫作 Geohash 编码。大多数应用都会使用 Geohash 编码进行地理位置的表示,以及在很多系统中,比如,Redis、MySQL 以及 Elastic Search 中,也都支持 Geohash 数据的存储和查询。
(四)RTree及其变体
另一种空间索引方法是按照数据进行划分,通常是对空间对象的外接矩形(MBR)进行多级划分。这种方法使用一棵多叉树来保存MBR和空间对象,其中每一级作为树的一层。只有叶子节点存储实际的空间对象,而非叶子节点存储更大范围的MBR。这类空间索引的典型代表是RTree及其变体。
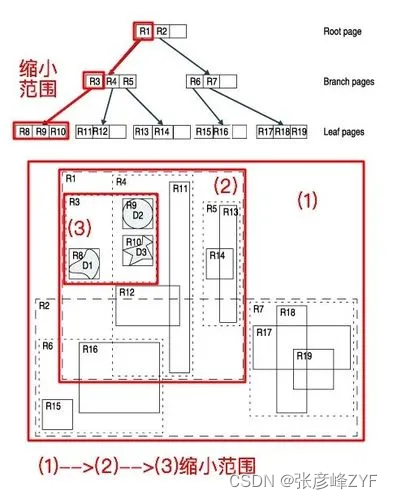
假设我们有一个城市地图上的空间数据集,其中包含了许多建筑物(空间对象)。希望使用RTree来组织这些建筑物的位置信息,以便能够高效地进行范围查询和邻近查询。
-
建立RTree: 开始时,RTree的根节点包含整个城市的外接矩形。每个节点都有一个关联的MBR,而叶子节点包含实际的建筑物信息。
-
插入建筑物: 当新的建筑物被插入时,RTree会调整相应的节点,确保树的平衡。插入操作可能导致节点的分裂,以容纳新的MBR。
-
范围查询: 假设我们要查询城市中某个区域内的所有建筑物。RTree会从根节点开始,逐层检查节点的MBR,仅选择与查询区域相交的节点。这样就能有效剪枝,减少搜索空间,直到到达叶子节点。然后,我们可以检查叶子节点中实际的建筑物数据,找到符合查询条件的建筑物。
-
邻近查询: 假设我们想找到某个特定建筑物附近的其他建筑物。我们首先找到包含该建筑物的叶子节点,然后沿着树遍历到根节点,选择可能与目标建筑物相交或接近的节点。这样,我们可以有效地缩小搜索范围,找到附近的建筑物。
-
删除建筑物: 如果需要删除某个建筑物,RTree会调整相关节点,确保树的平衡。删除操作可能导致节点的合并或调整。
通过RTree,我们能够以高效的方式组织、查询和更新城市地图上的建筑物数据,提供了对多维空间数据的灵活支持。这是一个简化的案例。
二、业内方案选取
空间数据的存储和空间关系计算需要借助空间索引来实现,常见的空间索引有三个方案,本地内存(比如基于RTree)、空间数据库(典型的如PostgreSQL+PostGIS)、分布式KV(比如基于Geohash的RedisGEO)。
| 方案 | 特点 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|
|
本地内存索引 (RTree) |
基于树状结构,适用于本地内存中的数据组织和查询 | 空间范围查询和邻近查询性能好 | 不适用于大规模数据存储和分布式计算 | 中小规模数据集的本地应用 |
|
空间数据库 (PostgreSQL+PostGIS) |
基于关系型数据库系统,提供空间扩展(PostGIS) | 支持复杂的空间查询和分析,数据持久化 | 部署和维护相对复杂,对小规模应用可能过重 | 大规模、复杂的空间数据应用 |
|
分布式KV (基于Geohash的RedisGEO) |
基于键值存储系统,使用Geohash编码 | 高效的地理位置查询,适用于分布式环境 | 不适用于复杂的空间查询和分析 | 实时位置服务,分布式系统 |
选择合适的空间索引方案通常取决于应用的需求和规模。如果是小规模、单机的应用,RTree等本地内存索引可能足够;对于复杂查询和大规模数据集,空间数据库是一个不错的选择;而分布式KV适用于需要分布式处理和实时查询的场景。
三、分布式空间索引架构
只提供一个简单的架构思考(实际中一定不能单独只用一种,这样实现上很受限,最好是结合着实际情况进行整合设计),具体应用请根据实际内容进行设置处理。基于读写分离的CQRS(Command Query Responsibility Segregation)架构,其中查询端和管理端之间通过消息传输实现松耦合。
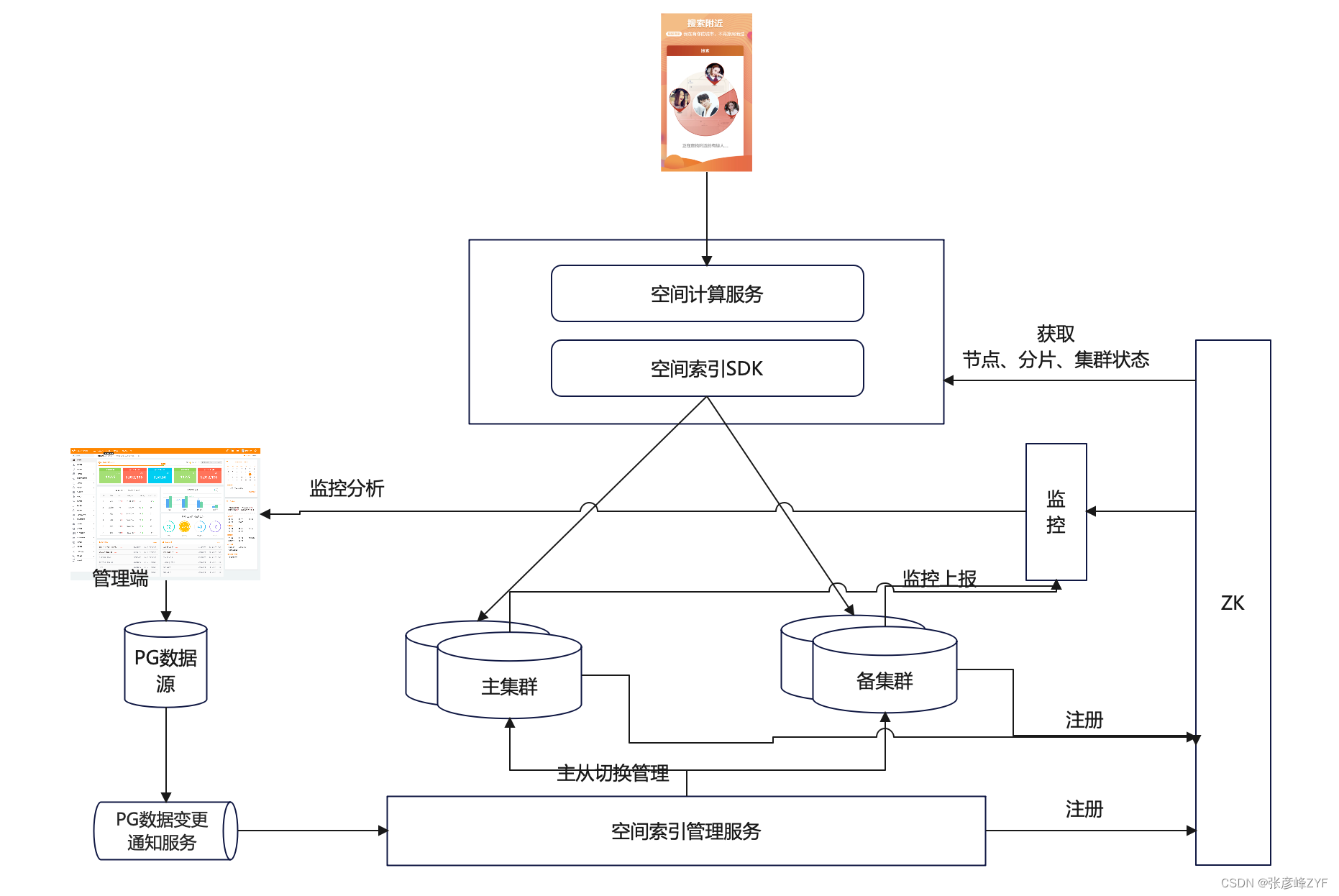
(一)PG数据变更通知服务
服务类型: 自研的PostgreSQL版本DTS服务。
职责: 负责订阅PG数据源的变更并进行变更通知。
功能: 提供实时的数据变更订阅功能,使得其他系统能够获取PG数据库的最新状态。
(二)空间索引管理服务
职责: 管理空间索引,包括多集群、多分片、多节点的管理。
功能:
- 增删集群、分片、节点。
- 数据分发、一致性保障。
- 处理围栏变更、主从切换、zk状态更新等操作。
- 提供可视化管理页面和基于Prometheus的监控报警平台。
(三)空间索引SDK
职责: 客户端路由和空间索引节点服务发现。
功能:
- 利用Lettuce非阻塞响应式开源库处理客户端请求。
- 提供空间索引节点的服务发现,确保客户端能够准确路由请求。
- 基于公司的ZK平台提供额外能力。
整体架构的特点包括CQRS的使用,读写分离,消息传输的松耦合,以及对PG数据库和空间索引的有效管理和通知机制。这样的设计有助于系统的可维护性、伸缩性和性能优化。
参考文章
1.13 | 空间检索(上):如何用Geohash实现“查找附近的人”功能?-极客时间
3.开源方案距离计算问题:https://github.com/tidwall/tile38/issues/222
4.RTree的距离计算算法:Для просмотра статьи разгадайте капчу
原文地址:https://blog.csdn.net/xiaofeng10330111/article/details/135887474
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_64083.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!