本文介绍: 接着就是模型构建,这里我选择了逻辑回归、KNN、SVM三种核函数、深度学习等算法,并进行了模型之间的对比,同时还使用了K折交叉验证,利用bagging算法进行模型融合,防止过拟合,输出预测错误的样本来进行模型调节等等。③如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。④有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
前言
本文章是我在完成机器学习课程设计写的总结,共计花费五天左右,在kaggle平台上测试,最高的一次准确率为0.78708。
在使用机器学习相关知识去处理某个实际的问题的时候首先就是从需求理解和问题预处理开始,通过异常数据收集、数据整合、数据分析探索,到模型训练和调优,最后进行模型验证评估。
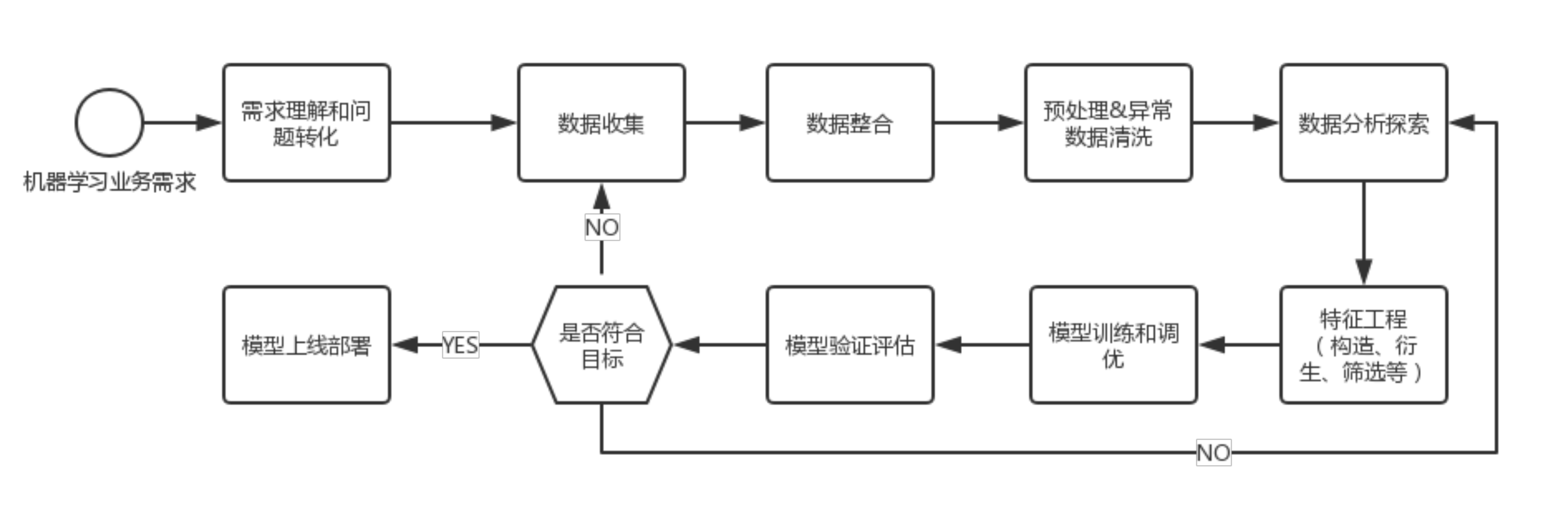
需求理解和问题预处理是整个流程的基础,在本次课程设计中,目标是判断乘客的生还率,怎样基于已有的特征来预测是否生还。
然后就是数据收集,这里我们用了kaggle平台上的数据集。但是这个数据集是不完整的这就需要我们对数据进行预处理和数据清洗。
需要数据进行清洗、整合和探索性分析,寻找数据的规律和特征,为模型的训练提供支持。在这里数据中存在缺失值,缺失值的填充方法有很多:
一、数据集收集
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






