1. 背景
对于很多数据团队来说,要满足实时需求并不容易。为什么?因为作流程(数据采集、预处理、分析、结果保存)涉及大量等待。等待数据发送到 ETL 工具,等待数据批量处理,等待数据加载到数据仓库中,甚至等待查询完成运行。
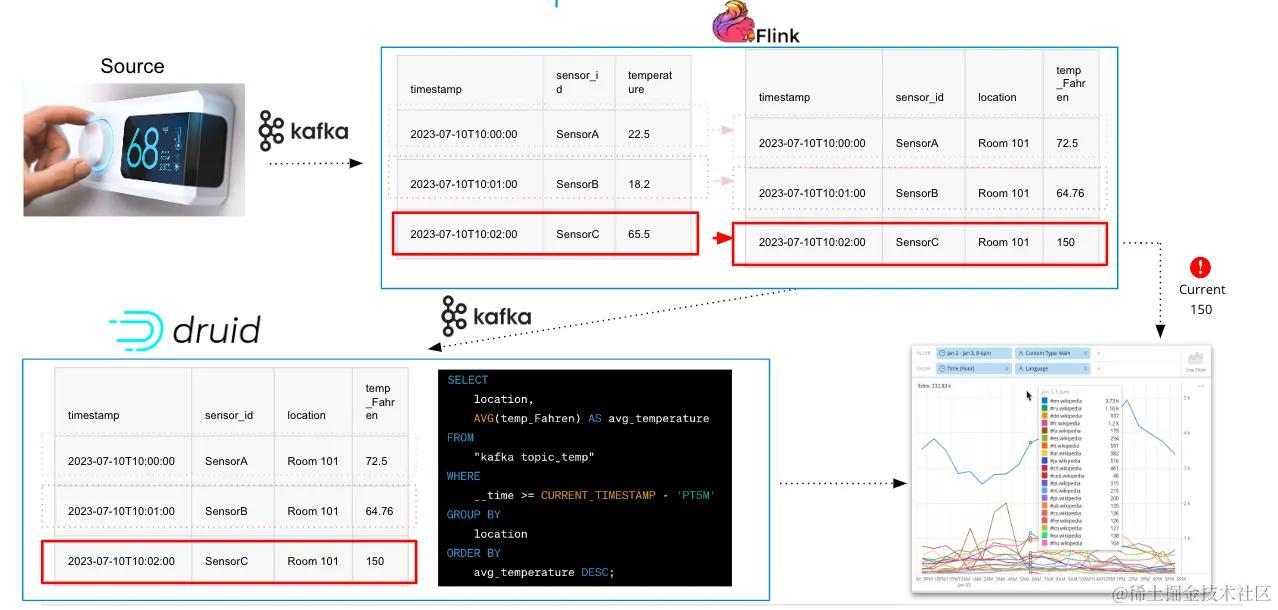
但开源领域有一个解决方案:Kafka、Flink和Druid一起使用时,可以创建一个实时数据架构,减少这些等待时间。在这篇文章中,我们将探讨如何利用Kafka、Flink、Druid实现广泛的实时数据系统架构。
2. 构建实时数据系统
什么是实时数据系统?想象一下任意一个后台系统或服务器端系统,它们利用数据来实时提供决策依据,这些数据包数据括警报、监控、仪表板、分析和个性化建议。
构建这种实时数据系统就是 Kafka-Flink-Druid (KFD) 架构的用武之地。

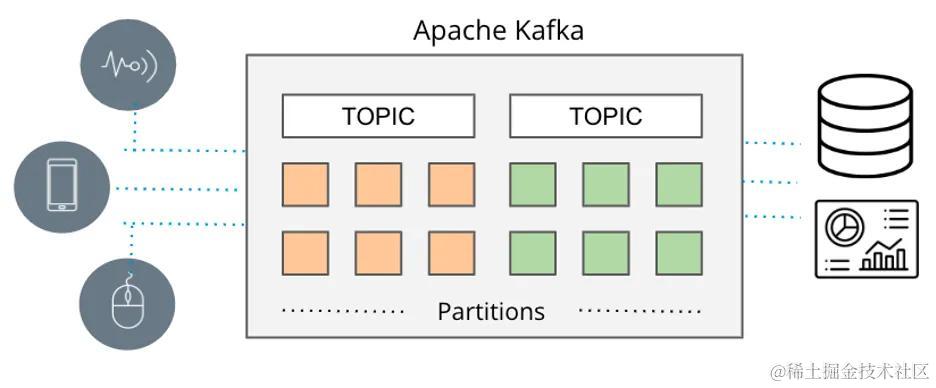
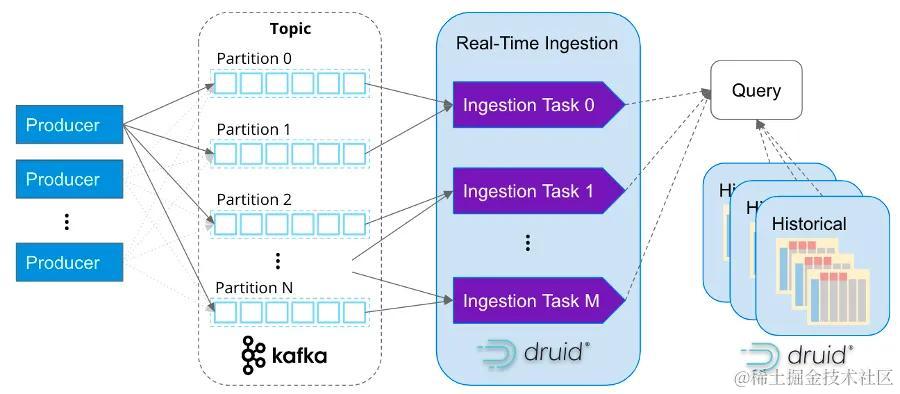
3. 流数据管道:Kafka
4. 流处理:Flink
2.1 丰富与转化
2.2 持续监控和警报
5. 实时分析:Druid
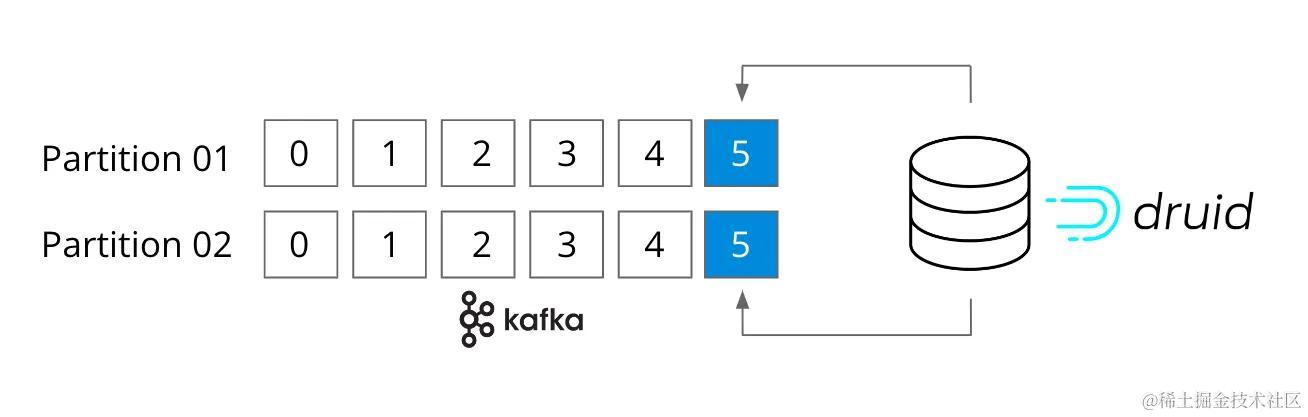
5.1 高度互动的查询
Flink 和 Druid 的决策清单
结论
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。