本文介绍: 「吴恩达」深度学习笔记 – 长短时记忆网络LSTM
一、经典模型
widetilde{c}^{<t>} = tanh(w_{c}[a^{<t-1>},x^{<t>}]+b_{c})
-
更新门:Gamma_{u} = sigma(w_{u}[a^{<t-1>},x^{<t>}]+b_{u})
-
遗忘门:Gamma_{f} = sigma(w_{f}[a^{<t-1>},x^{<t>}]+b_{f})
-
输出门:Gamma_{o} = sigma(w_{o}[a^{<t-1>},x^{<t>}]+b_{o})
c^{<t>} = Gamma_{u}*widetilde{c}^{<t>} + Gamma_{f}*widetilde{c}^{<t-1>}
a^{<t>} = Gamma_{o} * tanh(c^{<t>})

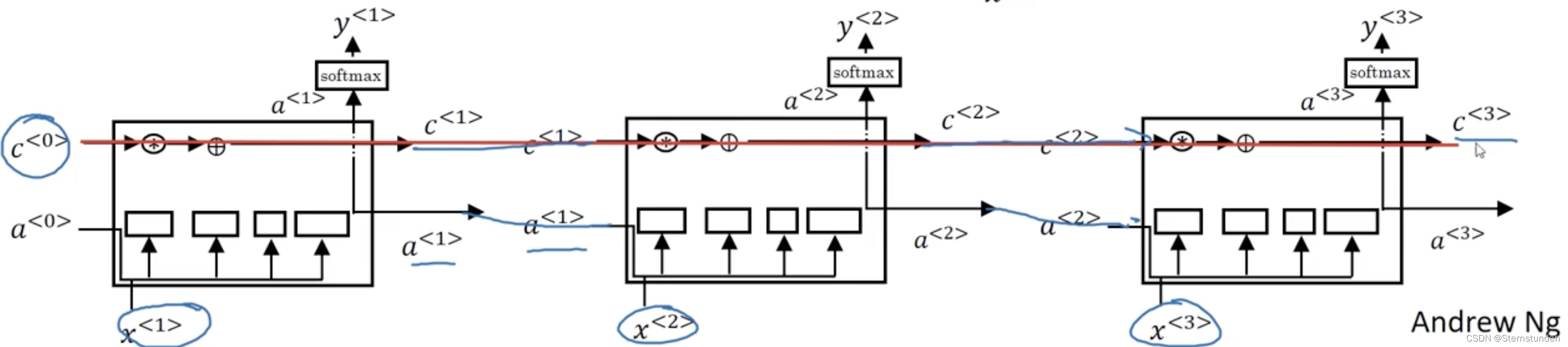
二、窥视孔连接
c^{<t-1>} 也能影响门的值:
Gamma_{u} = sigma(w_{u}[a^{<t-1>},x^{<t>},c^{<t-1>}]+b_{u})
Gamma_{f} = sigma(w_{f}[a^{<t-1>},x^{<t>},c^{<t-1>}]+b_{f})
Gamma_{o} = sigma(w_{o}[a^{<t-1>},x^{<t>},c^{<t-1>}]+b_{o})
三、vs GRU
GUR 相关内容见上一篇博客
GRU 是更简单的模型,只有两个门,运行快,更容易建立大的网络
LSTM 更加强大和灵活 —— 作为默认选择
原文地址:https://blog.csdn.net/qq_52063383/article/details/136027586
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_67421.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)